Пройшли ті дні, коли не треба було турбуватися про оптимізацію продуктивності баз даних. Час не стоїть на місці. Кожен новий бізнесмен зі сфери високих технологій хоче створити черговий Facebook, прагнучи при цьому збирати всі дані, до яких може дотягнутися. Ці дані потрібні бізнесу для якіснішого навчання моделей, які допомагають заробляти. В таких умовах програмістам необхідно створювати такі API, які дозволяють швидко і надійно працювати з величезними обсягами інформації.
Якщо ви вже деякий час займаєтеся проєктуванням серверних частин програм або баз даних, то ви, ймовірно, писали код для виконання запитів з розбиттям на сторінки. Наприклад, такий:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Я правий?
Але якщо для розбиття на сторінки ви виконували саме такий запит, я з жалем можу відзначити, що ви робили це далеко не найефективнішим чином.
Хочете мені заперечити? Можете не витрачати час. Slack, Shopify і Mixmax вже застосовують прийоми, про якиі я хочу сьогодні розповісти.
Назвіть хоча б одного розробника бекендів, який ніколи не користувався OFFSET та LIMIT для виконання запитів з розбиттям на сторінки. У MVP (Minimum Viable Product, мінімальний життєздатний продукт) і в проєктах, де використовуються невеликі обсяги даних, цей підхід цілком прийнятний. Він, так би мовити, «просто працює».
Але якщо потрібно з нуля створювати надійні та ефективні системи, варто завчасно подбати про ефективність виконання запитів до баз даних, що використовуються у таких системах.
Сьогодні ми поговоримо про проблеми та реалізації механізмів виконання запитів з розбиттям на сторінки, і про те, як досягти високої продуктивності при виконанні подібних запитів.
Що не так з OFFSET і LIMIT?
Як вже було сказано, OFFSET та LIMIT чудово показують себе у проєктах, в яких не потрібно працювати з великими обсягами даних.
Проблема виникає у випадку, якщо база даних розростається до таких розмірів, що перестає поміщатися в пам'яті сервера. Але при цьому в ході роботи з цією базою даних потрібно використовувати запити з розбиттям на сторінки.
Для того щоб ця проблема себе проявила, потрібно, щоб виникла ситуація, в якій СУБД вдається до неефективної операції повного сканування таблиці (Full Table Scan) при виконанні кожного запиту з розбиттям на сторінки (в той самий час можуть відбуватися операції вставки та видалення даних, і застарілі дані нам при цьому не потрібні!).
Що таке «повне сканування таблиці» (або «послідовний перегляд таблиці», Sequential Scan)? Це — операція, в ході якої СУБД послідовно зчитує кожний рядок таблиці та перевіряє їх на відповідність критеріям. Відомо, що цей тип сканування таблиць є найповільнішим. Справа в тому, що при його виконанні виконується багато операцій введення/виводу, що задіюють дискову підсистему сервера. Ситуацію погіршують затримки, супутні роботі з даними, що зберігаються на дисках, і те, що передача даних з диска в пам'ять — це ресурсоємна операція.
Наприклад, у вас є записи про 100000000 користувачів, і ви виконуєте запит з конструкцією OFFSET 50000000. Це означає, що СУБД доведеться завантажити всі ці записи (а вони нам навіть не потрібні!), помістити їх у пам'ять, а вже після цього взяти, припустимо, 20 результатів, про які вказано в LIMIT.
Скажімо, це може виглядати так: «вибрати рядки від 50000 до 50020 з 100000». Тобто, системі для виконання запиту потрібно буде спочатку завантажити 50000 рядків. Бачите, як багато непотрібної роботи їй доведеться виконати?
Якщо не вірите — подивіться на приклад, який я створив, користуючись можливостями db-fiddle.com.
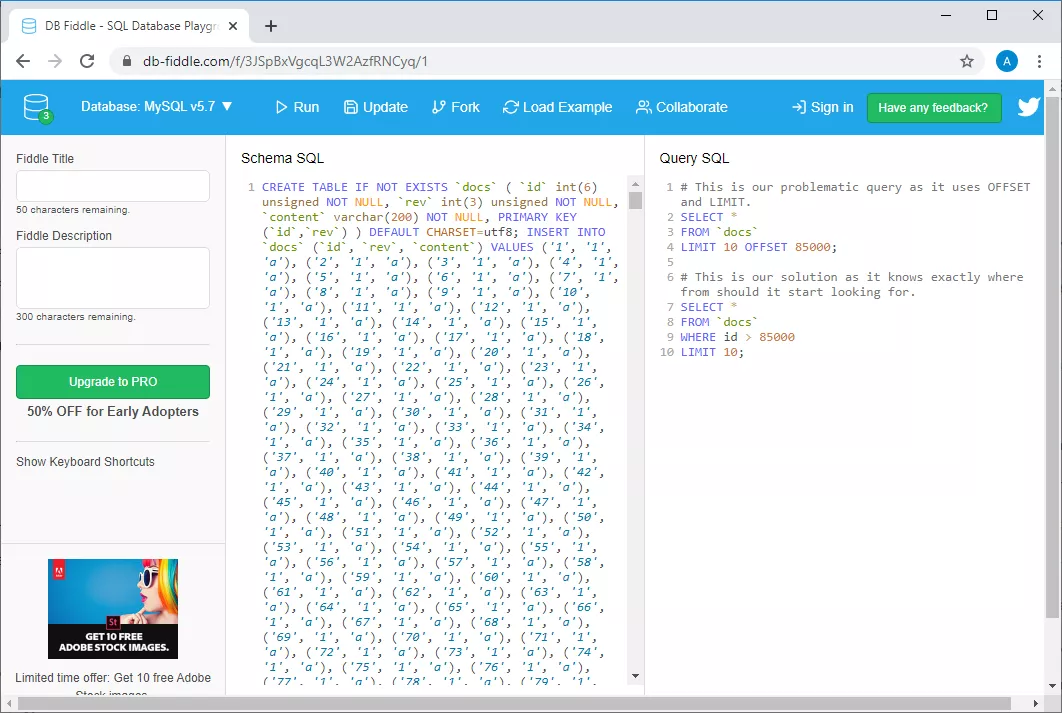
Приклад db-fiddle.com
Зліва, в полі Schema SQL, є код, який виконує вставку в базу даних 100000 рядків, а праворуч, у полі SQL Query, показані два запити. Перший, повільний, виглядає так:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
А другий, який являє собою ефективне рішення тієї ж задачі, так:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Для того щоб виконати ці запити, досить натиснути на кнопку Run у верхній частині сторінки. Зробивши це, порівняємо дані про час виконання запитів. Виявляється, що на виконання неефективного запиту йде, як мінімум, у 30 разів більше часу, ніж на виконання другого (від запуску до запуску цей час розрізняється, наприклад, система може повідомити про те, що на виконання першого запиту пішло 37 мс, а на виконання другого — 1 мс).
А якщо датих буде більше, то все буде виглядати ще гірше (для того щоб у цьому переконатися — погляньте на мій приклад з 10 мільйонами рядків).
 Те, що ми тільки що обговорили, повинно дати вам деяке розуміння того, як, насправді, обробляються запити до баз даних.
Те, що ми тільки що обговорили, повинно дати вам деяке розуміння того, як, насправді, обробляються запити до баз даних.
Враховуйте, що чим більше значення OFFSET — тим довше буде виконуватися запит.
Що варто використовувати замість комбінації OFFSET і LIMIT?
Замість комбінації OFFSET та LIMIT варто використовувати конструкцію, побудовану за такою схемою:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Це — виконання запиту з розбиттям на сторінки, засноване на курсорі (Cursor based pagination).
Замість того, щоб локально зберігати поточні OFFSET та LIMIT і передавати їх з кожним запитом, потрібно зберігати останній отриманий первинний ключ (зазвичай це ID) і LIMIT, в результаті й будуть виходити запити, що нагадують вищенаведений.
Чому? Річ у тому, що в явному вигляді вказуючи ідентифікатор останнього прочитаного рядка, ви повідомляєте своїй СУБД про те, де їй потрібно починати пошук потрібних даних. Причому, пошук, завдяки використанню ключа, буде здійснюватися ефективно, системі не доведеться відвертатися на рядки, що знаходяться за межами вказаного діапазону.
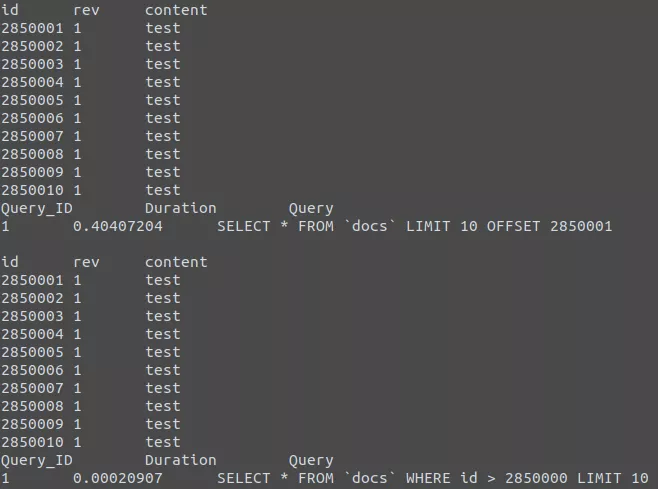
Погляньмо на наступне порівняння продуктивності різних запитів. Ось неефективний запит.
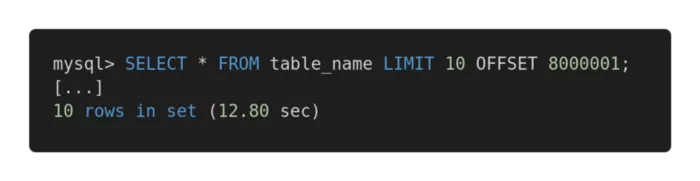
Повільний запит
А ось — оптимізована версія цього запиту.
 Швидкий запит
Швидкий запитОбидва запити повертають в точності один і той самий обсяг даних. Але на виконання першого йде 12,80 секунд, а на другий — 0,01 секунда. Відчуваєте різницю?
Можливі проблеми
Для забезпечення ефективної роботи запропонованого методу виконання запитів потрібно, щоб в таблиці був стовпець (стовпці), що містить унікальні, послідовно розташовані індекси, начебто цілочисельного ідентифікатора. В деяких специфічних випадках це може визначати успіх застосування подібних запитів задля підвищення швидкості роботи з базою даних.
Природно, конструюючи запити, потрібно враховувати особливості архітектури таблиць, і вибирати ті механізми, які найкращим чином покажуть себе на наявних таблицях. Наприклад, якщо в запитах потрібно працювати з великими обсягами пов'язаних даних, вам може здатися цікавою ця стаття.
Якщо перед нами стоїть проблема відсутності первинного ключа, наприклад, якщо є таблиця з відношенням «багатьох-до-багатьох» (many-to-may), традиційний підхід, що передбачає застосування OFFSET та LIMIT, нам гарантовано підійде. Але його застосування може призвести до виконання потенційно повільних запитів. У подібних випадках я порекомендував би використовувати первинний ключ з автоінкрементом, навіть якщо він потрібен тільки для організації виконання запитів з розбиттям на сторінки.
Якщо вам цікава ця тема — ось, ось і ось — кілька корисних матеріалів.
Підсумки
Головний висновок, який ми можемо зробити, полягають у тому, що завжди, про які б розміри бази даних не йшла мова, треба аналізувати швидкість виконання запитів. В наш час вкрай важлива масштабованість рішень, і якщо з самого початку роботи над певною системою спроєктувати все правильно, це, у майбутньому, здатне позбавити розробника від безлічі проблем.
Джерело ENG: medium.com

Ще немає коментарів