
Дослідники з OpenAI навчили GPT-2 модель доповнювати та генерувати зображення. Навчена iGPT обходить state-of-the-art підходи у задачі класифікації зображень. Всупереч більшій швидкості, у порівнянні зі згортковими моделями, навчання iGPT більш ресурсомістке. При цьому модель не вимагає змін в архітектурі для використання в інших завданнях.
Transfer learning для задач комп'ютерного зору
Навчання без вчителя і self-supervised навчання — це одне з відкритих завдань в машинному навчанні. Останні дослідження показували успіх моделей, заснованих на Transformer, для задач обробки природної мови. Такі моделі, як BERT, GPT-2, RoBERTa, T5, і їх варіації є state-of-the-art в більшості завдань NLP. Однак поки Transformer архітектурі не вдавалося вдало застосувати для задач обробки зображень.
Transformer моделі, як BERT і GPT-2, не залежать від області задачі. Це означає, що моделі можна використовувати для розв'язання широкого спектра задач без значних архітектурних змін. Спочатку моделі обробляли одномірні послідовності.
GPT-2, навчена на послідовностях пікселях, здатна розуміти такі характеристики двовимірного зображення, як наявність об'єкта та його категорія. Ваги моделі дозволяють досягти state-of-the-art результатів на задачі класифікації зображень. Дослідники тестували iGPT на CIFAR-10, STL-10 і ImageNet. Архітектура iGPT при цьому повністю збігається з GPT-2.
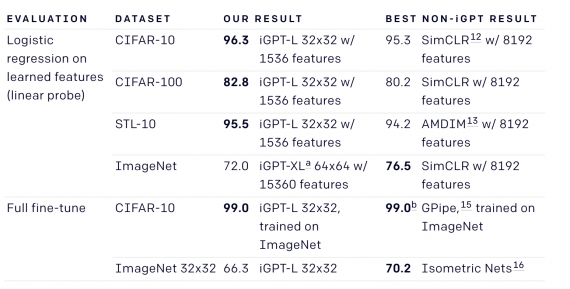 Результати iGPT в порівнянні з попередніми state-of-the-art підходами
Результати iGPT в порівнянні з попередніми state-of-the-art підходами

Ще немає коментарів