
У даній статті ми напишемо невелику програму для розв'язання задачі виявлення та розпізнавання об'єктів (object detection) в режимі реального часу. Програма написана на мові програмування Swift під платформу iOS. Для детектування об'єктів будемо використовувати нейронну мережу високої точності з архітектурою під назвою YOLOv3. У статті ми навчимося працювати в iOS з нейронними мережами за допомогою фреймворку CoreML, трохи розберемося, що з себе представляє мережа YOLOv3 і як використовувати і обробляти виходи даної мережі. Так само перевіримо роботу програми і порівняємо кілька варіацій YOLOv3: YOLOv3-tiny і YOLOv3-416.
Вихідний код буде доступний в кінці статті, тому всі бажаючі зможуть протестувати роботу нейронної мережі у себе на пристрої.
Object detection
Для початку коротко розберемося, що з себе представляє завдання детектування об'єктів (object detection) на зображенні і які інструменти застосовуються для цього на сьогоднішній день. Я розумію, що багато хто досить добре знайомий з цією темою, але я, все одно, дозволю собі трохи про це розповісти.
Зараз дуже багато завдань у галузі комп'ютерного зору вирішуються за допомогою згорткових нейронних мереж (Convolutional Neural Networks), в подальшому CNN. Завдяки своїй будові вони добре витягують ознаки з зображення. CNN використовуються в задачах класифікації, розпізнавання, сегментації та ще в багатьох інших.
Популярні архітектури CNN для розпізнавання об'єктів:
- R-CNN. Можна сказати перша модель для вирішення даної задачі. Працює як звичайний класифікатор зображень. На вхід мережі подаються різні регіони зображення і для них робиться передбачення. Дуже повільна оскільки проганяє одне зображення декілька тисяч разів.
- Fast R-CNN. Покращена і швидша версія R-CNN, працює за схожим принципом, але спочатку всі зображення подаються на вхід CNN, потім з отриманого внутрішнього подання генеруються регіони. Але все ще досить повільна для задач реального часу.
- Faster R-CNN. Головна відмінність від попередніх у тому, що замість selective search алгоритму для вибору регіонів використовує нейронну мережу для їх навчання.
- YOLO. Зовсім інший принцип роботи порівняно з попередніми, не використовує регіони взагалі. Найшвидша. Докладніше про неї піде мова в статті.
- SSD. За принципом схожа на YOLO, але в якості мережі для вилучення ознак використовує VGG16. Теж доволі швидка і придатна для роботи в реальному часі.
- Feature Pyramid Networks (FPN). Ще один різновид мережі типу Single Shot Detector, через особливості вилучення ознак краще ніж SSD розпізнає дрібні об'єкти.
- RetinaNet. Використовує комбінацію FPN+ResNet і завдяки спеціальній функції помилки (focal loss) дає вищу точність (ассигасу).
В даній статті ми будемо використовувати архітектуру YOLO, а саме її останню модифікацію YOLOv3.
Чому YOLO?
YOLO або Look You Only Once — це дуже популярна на поточний момент архітектура CNN, яка використовується для розпізнавання множини об'єктів на зображенні. Більш повну інформацію про неї можна отримати на офіційному сайті, там же можна знайти публікації в яких докладно описана теорія і математична складова цієї мережі, а так само розписаний процес її навчання.
Головна особливість цієї архітектури порівняно з іншими полягає в тому, що більшість систем застосовують CNN кілька разів до різних регіонів зображення, YOLO CNN застосовується один раз до всього зображення відразу. Мережа ділить зображення на своєрідну сітку і пророкує bounding boxes і ймовірності того, що там є шуканий об'єкт для кожної ділянки.
Плюси даного підходу полягає в тому, що мережа дивиться на все зображення відразу і враховує контекст при детектуванні і розпізнавання об'єкта. Так само YOLO в 1000 разів швидше, ніж R-CNN і близько 100x швидше ніж Fast R-CNN. В даній статті ми будемо запускати мережу на мобільному пристрої для онлайн обробки, тому це для нас найголовніше.
Більш детальну інформацію порівняно архітектур можна подивитися тут.
YOLOv3
YOLOv3 — це вдосконалена версія архітектури YOLO. Вона складається з 106-ти згорткових шарів і краще детектує невеликі об'єкти порівняно з її попереднецею YOLOv2. Основна особливість YOLOv3 полягає в тому, що на виході є три шари кожен з яких розрахований на виявлення об'єктів різного розміру.
На картинці нижче наведено її схематичне влаштування:
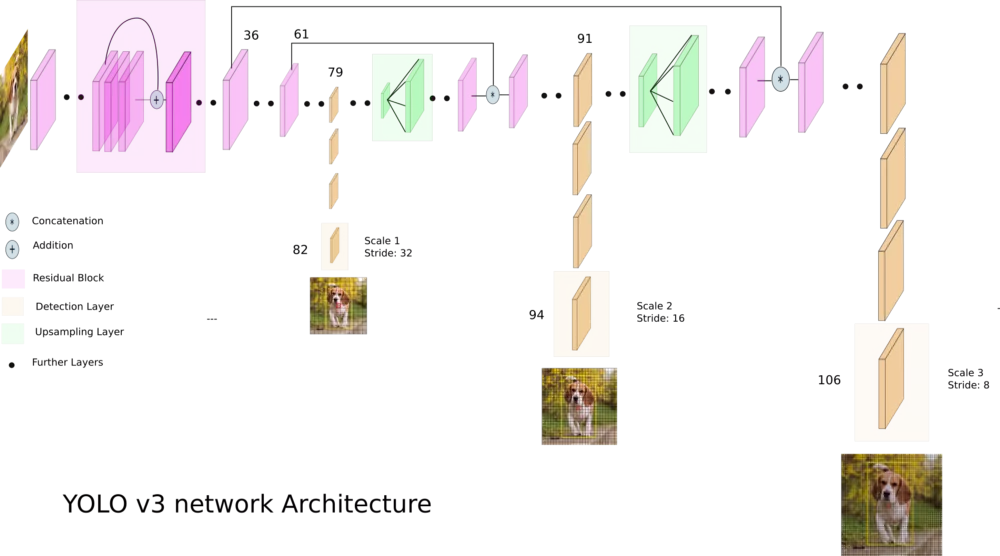
YOLOv3-tiny — обрізана версія архітектури YOLOv3, складається з меншої кількості шарів (вихідних шарів всього 2). Вона гірше пророкує дрібні об'єкти і призначена для невеликих датасетів. Але, через спрощену будову, мережа займає невеликий обсяг пам'яті (~35 Мб) і вона видає вищий FPS. Тому така архітектура краще для використання на мобільному пристрої.
Пишемо програму для розпізнавання об'єктів
Давайте створимо програму, яка буде розпізнавати різні об'єкти на зображенні в реальному часі використовуючи камеру телефону. Весь код будемо писати мовою програмування Swift 4.2 і запускати на iOS пристрої.
В даному тутаріалі ми візьмемо вже готову мережу з вагами навченими на COCO датасеті. У ньому представлено 80 різних класів. Отже наша нейронка буде здатна розпізнати 80 різних об'єктів
З Darknet в CoreML
Оригінальна архітектура YOLOv3 реалізована за допомогою фремворка Darknet.
На iOS, починаючи з версії 11.0, є чудова бібліотека CoreML, яка дозволяє запускати моделі машинного навчання безпосередньо на пристрої. Але є одне обмеження: програму можна буде запустити тільки на пристрої під управлінням iOS 11 і вище.
Проблема в тому, що CoreML розуміє тільки певний формат моделі .coreml. Для більшості популярних бібліотек, таких як Tensorflow, Keras або XGBoost, є можливість безпосередньо конвертувати у формат CoreML. Але для Darknet такої можливості немає. Для того, що б перетворити збережену і навчену модель з Darknet в CoreML можна використовувати різні варіанти, наприклад зберегти Darknet ONNX, а потім вже з ONNX перетворити в CoreML.
Ми скористаємося простішим способом і будемо використовувати Keras імплементацію YOLOv3. Алгоритм дії такий: завантажимо ваги Darknet в Keras модель, збережемо її в форматі Keras і вже з цього напряму перетворимо в CoreML.
- Завантажуємо Darknet. Завантажимо файли навченої моделі Darknet-YOLOv3 звідси. У даній статті я буду використовувати дві архітектури: YOLOv3-416 YOLOv3-tiny. Нам знадобиться обидва файлу cfg і weights.
- Darknet в Keras. Спочатку клонуємо репозиторій, переходимо в папку репо і запускаємо команду:
де yolov3.cfg і yolov3.weights викачані файли Darknet. У результаті в нас має з'явитися файл з розширенням .h5 — це і є збережена модель YOLOv3 у форматі Keras.python convert.py yolov3.cfg yolov3.weights yolo.h5 - Keras в CoreML. Залишився останній крок. Для того, що б перетворити модель в CoreML потрібно запустити скрипт на python (попередньо потрібно встановити бібліотеку coremltools для пітона):
import coremltools coreml_model = coremltools.converters.keras.convert( 'yolo.h5', input_names='image', image_input_names='image', input_name_shape_dict={'image': [None, 416, 416, 3]}, # розмір вхідного зображення для мережі image_scale=1/255.) coreml_model.input_description['image'] = 'Input image' coreml_model.save('yolo.mlmodel')
Кроки, що описані вище, треба виконати для двох моделей YOLOv3-416 YOLOv3-tiny.
Коли ми все це зробили у нас є два файли: yolo.mlmodel і yolo-tiny.mlmodel. Тепер можна приступати до написання коду програми.
Створення застосунку для iOS
Повністю весь код програми я описувати не буду, його можна подивитися в репозиторії посилання на який буде наведено в кінці статті. Скажу лише, що у нас є три UIViewController-a: OnlineViewController, PhotoViewController і SettingsViewController. У першому йде вивід камери і онлайн детектування об'єктів для кожного кадру. У другому можна зробити фотографію або вибрати знімок з галереї і протестувати мережу на цих зображеннях. У третьому знаходяться налаштування, можна вибрати модель YOLOv3-416 або YOLOv3-tiny, а так само підібрати пороги IoU (intersection over union) і object confidence (ймовірність того, що на поточній ділянці зображення є об'єкт).
Завантаження моделі в CoreML
Після того як ми перетворили навчену модель з Darknet формату в CoreML, у нас є файл з розширенням .mlmodel. В моєму випадку я створив два файли: yolo.mlmodel yolo-tiny.mlmodel, для моделей YOLOv3-416 YOLOv3-tiny відповідно. Тепер можна завантажувати ці файли в проект в Xcode.
Створюємо клас ModelProvider в ньому зберігається поточна модель і методи для асинхронного виклику нейронної мережі на виконання. Завантаження моделі здійснюється таким чином:
private func loadModel(type: YOLOType) {
do {
self.model = try YOLO(type: type)
} catch {
assertionFailure("error creating model")
}
}
Клас YOLO безпосередньо відповідає за завантаження .mlmodel обробку файлів і виходів моделі. Завантаження файлів моделі:
var url: URL? = nil
self.type = type
switch type {
case .v3_Tiny:
url = Bundle.main.url(forResource: "yolo-tiny", withExtension:"mlmodelc")
self.anchors = tiny_anchors
case .v3_416:
url = Bundle.main.url(forResource: "yolo", withExtension:"mlmodelc")
self.anchors = anchors_416
}
guard let modelURL = url else {
throw YOLOError.modelFileNotFound
}
do {
model = try MLModel(contentsOf: modelURL)
} catch let error {
print(error)
throw YOLOError.modelCreationError
}
Повний код ModelProvider.
import UIKit
import CoreML
protocol ModelProviderDelegate: class {
func show(predictions: [YOLO.Prediction]?,
stat: ModelProvider.Statistics,
error: YOLOError?)
}
@available(macOS 10.13, iOS 11.0, tvOS 11.0, watchOS 4.0, *)
class ModelProvider {
struct Statistics {
var timeForFrame: Float
var fps: Float
}
static let shared = ModelProvider(modelType: Settings.shared.modelType)
var model: YOLO!
weak var delegate: ModelProviderDelegate?
var predicted = 0
var timeOfFirstFrameInSecond = CACurrentMediaTime()
init(modelType type: YOLOType) {
loadModel(type: type)
}
func reloadModel(type: YOLOType) {
loadModel(type: type)
}
private func loadModel(type: YOLOType) {
do {
self.model = try YOLO(type: type)
} catch {
assertionFailure("error creating model")
}
}
func predict(frame: UIImage) {
DispatchQueue.global().async {
do {
let startTime = CACurrentMediaTime()
let predictions = try self.model.predict(frame: frame)
let elapsed = CACurrentMediaTime() - startTime
self.showResultOnMain(predictions: predictions, elapsed: Float(elapsed), error: nil)
} catch let error as YOLOError {
self.showResultOnMain(predictions: nil, elapsed: -1, error: error)
} catch {
self.showResultOnMain(predictions: nil, elapsed: -1, error: YOLOError.unknownError)
}
}
}
private func showResultOnMain(predictions: [YOLO.Prediction]?,
elapsed: Float, error: YOLOError?) {
if let delegate = self.delegate {
DispatchQueue.main.async {
let fps = self.measureFPS()
delegate.show(predictions: predictions,
stat: ModelProvider.Statistics(timeForFrame: elapsed,
fps: fps),
error: error)
}
}
}
private func measureFPS() -> Float {
predicted += 1
let elapsed = CACurrentMediaTime() - timeOfFirstFrameInSecond
let currentFPSDelivered = Double(predicted) / elapsed
if elapsed > 1 {
predicted = 0
timeOfFirstFrameInSecond = CACurrentMediaTime()
}
return Float(currentFPSDelivered)
}
}
Обробка виходів нейронної мережі
Тепер розберемося як обробляти виходи нейронної мережі і отримувати відповідні bounding box-и. В Xcode якщо вибрати файл моделі то можна побачити, що вона з себе представляє і побачити вихідні шари.
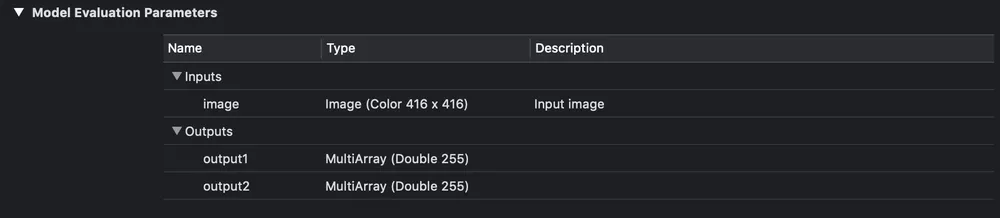
Вхід і вихід YOLOv3-tiny.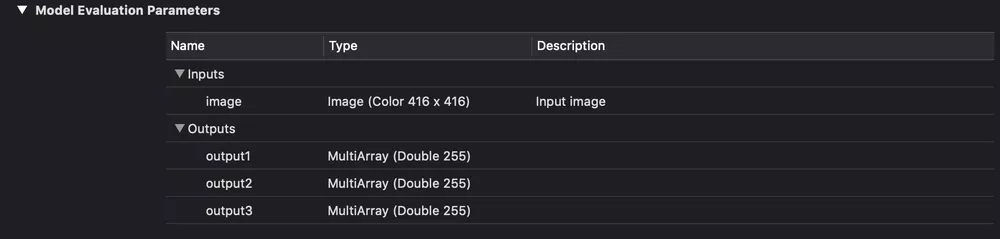
Вхід і вихід YOLOv3-416.
Як можна бачити на зображенні вище у нас є три для YOLOv3-416 і два для YOLOv3-tiny вихідних шари в кожному з яких передбачається bounding box-s для різних об'єктів.
В даному випадку це звичайний масив чисел, давайте ж розберемося як його парсити.
Модель YOLOv3 в якості виходу використовує три шари для розбиття зображення на різну сітку, розміри осередків цих сіток мають такі значення: 8, 16 і 32. Припустимо на вході у нас є зображення розміром 416x416 пікселів, тоді вихідні матриці (сітки) будуть мати розмір 52x52, 26x26 і 13x13 (416/8 = 52, 416/16 = 26 і 416/32 = 13). У випадку з YOLOv3-tiny все теж саме, тільки замість трьох сіток маємо дві: 16 і 32, тобто матриці розмірністю 26x26 і 13x13.
Після запуску завантаженої CoreML моделі на виході ми отримаємо два (або три) об'єкта класу MLMultiArray. І якщо подивитися на властивість shape у цих об'єктів, то побачимо таку картину (для YOLOv3-tiny):
![$[1, 1, 255, 26, 26]\\ [1, 1, 255, 13, 13]$](/storage/posts/2020/07/5f198e92621d6.webp)
Як і очікувалося розмірність матриць буде 26x26 і 13x13.Але що означає число 255? Як вже говорилося раніше, вихідні шари це матриці розмірністю 52x52, 26x26 і 13x13. Справа в тому, що кожен елемент цієї матриці це не число, це вектор. Тобто вихідний шар це трьох-мірна матриця. Цей вектор має розмірність B x (5 + C), де B — кількість bounding box в комірці, C — кількість класів. Звідки число 5? Причина така: для кожного box-a прогнозується ймовірність що там є об'єкт (object confidence) — це одне число, а решта чотири — це x, y, width і height для передбаченого box-a. На малюнку нижче показано схематичне подання цього вектора:
Схематичне уявлення вихідного шару (feature map).
Для нашої мережі навченої на 80-ти класах, для кожної клітини сітки розбиття передбачає 3 bounding box-a, для кожного з них — 80 ймовірностей класів + object confidence + 4 числа відповідають за стан і розмір цього box-a. Разом: 3 x (5 + 80) = 255.
Для отримання цих значень з класу MLMultiArray краще скористатися сирим покажчиком на масив даних та адресної арифметикою:
let pointer = UnsafeMutablePointer(OpaquePointer(out.dataPointer)) // одержання сирого покажчика
if out.strides.count < 3 {
throw YOLOError.strideOutOfBounds
}
let channelStride = out.strides[out.strides.count-3].intValue
let yStride = out.strides[out.strides.count-2].intValue
let xStride = out.strides[out.strides.count-1].intValue
func offset(ch: Int, x: Int, y: Int) -> Int { // функція доступу оффсетам
return ch * channelStride + y * yStride + x * xStride
}
Тепер необхідно обробити вектор з 255 елементів. Для кожного box-a потрібно отримати розподіл ймовірностей для 80 класів, зробити це можна за допомогою функції softmax.
Що таке softmax
Функція перетворює вектор x розмірності K у вектор тієї ж розмірності, де кожна координата xi отриманого вектора представлена речовим числом в інтервалі [0,1] і сума координат дорівнює 1.
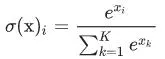 де K — розмірність вектора.
де K — розмірність вектора.
Функція softmax на Swift:
private func softmax(_ x: inout [Float]) {
let len = vDSP_Length(x.count)
var count = Int32(x.count)
vvexpf(&x, x, &count)
var sum: Float = 0
vDSP_sve(x, 1, &sum, len)
vDSP_vsdiv(x, 1, &sum, &x, 1, len)
}
Для отримання координат і розмірів bounding box-a потрібно скористатися формулами:
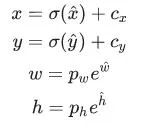
де  — передбачені x, y координати, ширина і висота відповідно,
— передбачені x, y координати, ширина і висота відповідно, σ(x) — функція сігмоіди, а pw,ph — значення якорів(anchors) для трьох box-ів. Ці значення визначаються під час тренування і задані у файлі Helpers.swift:
let anchors1: [Float] = [116,90, 156,198, 373,326] //якори для першого вихідного шару
let anchors2: [Float] = [30,61, 62,45, 59,119] //якори для другого вихідного шару
let anchors3: [Float] = [10,13, 16,30, 33,23] //якори для третього вихідного шару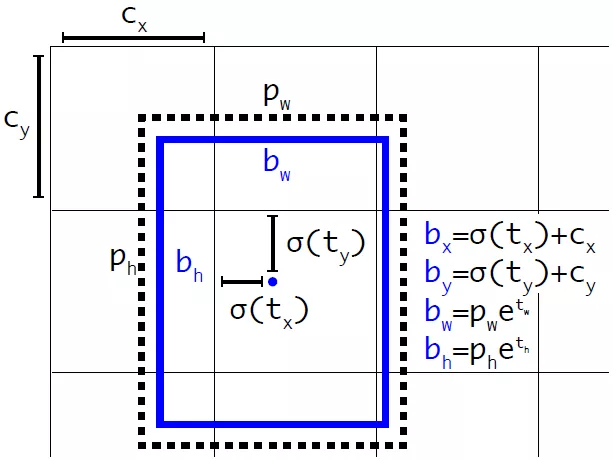
Схематичне зображення розрахунку положення bounding box-а.
Повний код обробки вихідних шарів.
private func process(output out: MLMultiArray, name: String) throws -> [Prediction] {
var predictions = [Prediction]()
let grid = out.shape[out.shape.count-1].intValue
let gridSize = YOLO.inputSize / Float(grid)
let classesCount = labels.count
print(out.shape)
let pointer = UnsafeMutablePointer<Double>(OpaquePointer(out.dataPointer))
if out.strides.count < 3 {
throw YOLOError.strideOutOfBounds
}
let channelStride = out.strides[out.strides.count-3].intValue
let yStride = out.strides[out.strides.count-2].intValue
let xStride = out.strides[out.strides.count-1].intValue
func offset(ch: Int, x: Int, y: Int) -> Int {
return ch * channelStride + y * yStride + x * xStride
}
for x in 0 ..< grid {
for y in 0 ..< grid {
for box_i in 0 ..< YOLO.boxesPerCell {
let boxOffset = box_i * (classesCount + 5)
let bbx = Float(pointer[offset(ch: boxOffset, x: x, y: y)])
let bby = Float(pointer[offset(ch: boxOffset + 1, x: x, y: y)])
let bbw = Float(pointer[offset(ch: boxOffset + 2, x: x, y: y)])
let bbh = Float(pointer[offset(ch: boxOffset + 3, x: x, y: y)])
let confidence = sigmoid(Float(pointer[offset(ch: boxOffset + 4, x: x, y: y)]))
if confidence < confidenceThreshold {
continue
}
let x_pos = (sigmoid(bbx) + Float(x)) * gridSize
let y_pos = (sigmoid(bby) + Float(y)) * gridSize
let width = exp(bbw) * self.anchors[name]![2 * box_i]
let height = exp(bbh) * self.anchors[name]![2 * box_i + 1]
for c in 0 ..< 80 {
classes[c] = Float(pointer[offset(ch: boxOffset + 5 + c, x: x, y: y)])
}
softmax(&classes)
let (detectedClass, bestClassScore) = argmax(classes)
let confidenceInClass = bestClassScore * confidence
if confidenceInClass < confidenceThreshold {
continue
}
predictions.append(Prediction(classIndex: detectedClass,
score: confidenceInClass,
rect: CGRect(x: CGFloat(x_pos - width / 2),
y: CGFloat(y_pos - height / 2),
width: CGFloat(width),
height: CGFloat(height))))
}
}
}
return predictions
}
Non max suppression
Після того як отримали координати і розміри bounding box-ів і відповідні ймовірності для всіх знайдених об'єктів на зображенні можна починати відмальовувати їх поверх картинки. Але є одна проблема! Може Виникнути така ситуація, коли для одного об'єкта передбачено декілька box-ів з досить високими ймовірностями. Як бути в такому випадку? Тут нам на допомогу приходить досить простий алгоритм під назвою Non maximum suppression.
Порядок дії алгоритму такий:
- Шукаємо bounding box з найбільшою ймовірністю приналежності до об'єкта.
- Пробігаємо по всім bounding box-ам які теж відносяться до цього об'єкту.
- Видаляємо їх якщо Intersection over Union (IoU) з першим bounding box більше заданого порога.
IoU рахується за простою формулою:

Розрахунок IoU.
static func IOU(a: CGRect, b: CGRect) -> Float {
let areaA = a.width * a.height
if areaA <= 0 { return 0 }
let areaB = b.width * b.height
if areaB <= 0 { return 0 }
let intersection = a.intersection(b)
let intersectionArea = intersection.width * intersection.height
return Float(intersectionArea / (areaA + areaB - intersectionArea))
}
Non max suppression.
private func nonMaxSuppression(boxes: inout [Prediction], threshold: Float) {
var i = 0
while i < boxes.count {
var j = i + 1
while j < boxes.count {
let iou = YOLO.IOU(a: boxes[i].rect, b: boxes[j].rect)
if iou > threshold {
if boxes[i].score > boxes[j].score {
if boxes[i].classIndex == boxes[j].classIndex {
boxes.remove(at: j)
} else {
j += 1
}
} else {
if boxes[i].classIndex == boxes[j].classIndex {
boxes.remove(at: i)
j = i + 1
} else {
j += 1
}
}
} else {
j += 1
}
}
i += 1
}
}
Після цього роботу безпосередньо з результатами передбачення нейронної мережі можна вважати закінченою. Далі необхідно написати функції і класи для отримання відеоряду з камери, виведення зображення на екран і відтворення передбачених bounding box-ів. Весь цей код в даній статті описувати не буду, але його можна буде подивитися в репозиторії.
Ще варто згадати, що я додав невелике згладжування bounding box-ів при обробці онлайн зображення, в даному випадку це звичайне усереднення положення та розміру передбаченого квадрата за останні 30 кадрів.
Тестування роботи програми
Тепер протестуємо роботу програми.
Ще раз нагадаю: В застосунку є три ViewController-а, один для обробки фотографій або знімків, другий для обробки онлайн відео потоку, третій для налаштування роботи мережі.
Почнемо з третього. У ньому можна вибрати одну з двох моделей YOLOv3-tiny або YOLOv3-416, підібрати confidence threshold і IoU threshold, так само можна увімкнути або вимкнути онлайн згладжування.
Тепер подивимося як працює навчена нейронна мережа з реальними зображеннями, для цього візьмемо фото з галереї і пропустимо її через мережу. Нижче на картинці представлено результати роботи YOLOv3-tiny з різними налаштуваннями.
 Різні режими роботи YOLOv3-tiny. На лівій картинці звичайний режим роботи. На середній — поріг IoU = 1 тобто як ніби відсутній Non-max suppression. На правій — низький поріг object confidence, тобто відображає всі можливі bounding box-и.
Різні режими роботи YOLOv3-tiny. На лівій картинці звичайний режим роботи. На середній — поріг IoU = 1 тобто як ніби відсутній Non-max suppression. На правій — низький поріг object confidence, тобто відображає всі можливі bounding box-и.
Далі наведено результат роботи YOLOv3-416. Можна помітити, що порівняно з YOLOv3-tiny отримані рамки більш правильні, а так само розпізнані дрібніші об'єкти на зображенні, що відповідає роботі третього вихідного шару.
оброблене Зображення з допомогою YOLOv3-416.
При включенні онлайн режиму роботи оброблявся кожен кадр і для нього робилося передбачення, тести проводилися на iPhone XS тому результат вийшов досить прийнятний для обох варіантів мережі. YOLOv3-tiny в середньому видає 30 — 32 fps, YOLOv3-416 — від 23 до 25 fps. Пристрій, на якому проходило тестування досить продуктивний, тому на більш ранніх моделях результати можуть відрізнятися, в такому випадку звичайно краще використовувати YOLOv3-tiny. Ще один важливий момент: yolo-tiny.mlmodel (YOLOv3-tiny) займає близько 35 Мб, в свою чергу yolo.mlmodel (YOLOv3-416) важить близько 250 Мб, що дуже суттєва різниця.
Висновок
В результаті був написаний iOS застосунок який за допомогою нейронної мережі може розпізнавати об'єкти на зображенні. Ми побачили як працювати з бібліотекою CoreML і як з її допомогою виконувати різні, заздалегідь навчені, моделі (до речі навчати з її допомогою теж можна). Задача розпізнавання об'єкта вирішувалася за допомогою YOLOv3 мережі. На iPhone XS дана мережа (YOLOv3-tiny) здатна обробляти зображення з частотою ~30 кадрів в секунду, що цілком достатньо для роботи в реальному часі.
Повний код програми можна подивитися на GitHub.

Ще немає коментарів