
Взявши за основу статтю Петра Зайцева про вузькі місця в продуктивності MySQL ( MySQL Performance Bottlenecks ), я хочу трохи розповісти про PostgreSQL.
В наші дні для роботи з PostgreSQL часто використовуються ORM-фреймворки. Зазвичай вони працюють добре, але з часом навантаження збільшується і виникає необхідність тюнінгувати сервер бази даних. Яким би надійним не був PostgreSQL, але і він може гальмувати при збільшенні трафіку.
Є багато способів усунення вузьких місць в продуктивності, але в цій статті ми звернемо увагу на наступне:
- Параметри сервера
- Управління підключеннями
- Налаштування автоочищення (autovacuum)
- Додаткове налаштування автоочищення
- Роздування таблиць (bloat)
- «Гарячі точки» в даних
- Сервера застосунків
- Реплікація
- Серверне оточення
Про «категорії» та «потенційний вплив»
«Складність» говорить про те наскільки просто реалізувати запропоноване рішення. А «потенційний вплив» дає уявлення про ступінь поліпшень в продуктивності системи. Однак з огляду на вік системи, її типу, технічного боргу і т.п. точний опис складності і впливу може бути проблематичним. Зрештою, в складних ситуаціях остаточний вибір завжди за вами.
Категорії:
- Складність
- Низька
- Середня
- Висока
- Низька-середня-висока
- Потенційний вплив
- Низький
- Середній
- Високий
- Низький-середній-високий
Параметри сервера
Складність: низька
Потенційний вплив: високий
Ще не так давно були часи, коли актуальні версії postgres могли працювати на i386. З тих пір налаштування за замовчуванням були змінені, але вони як і раніше налаштовані на використання найменшої кількості ресурсів.
Ці параметри змінити дуже просто і зазвичай вони налаштовуються при першій установці. Помилкові значення цих параметрів можуть привести до високого завантаження процесора і введення-виведення (IO):
- Параметр effective_cache_size ~ від 50 до 75%
- Параметр shared_buffers ~ 1/4 - 1/3 об'єму оперативної пам'яті
- Параметр work_mem ~ 10МБ
Рекомендоване значення effective_cache_size хоча і є типовим, але може бути пораховано точніше, якщо звернутися до «top» - free + cached оперативної пам'яті.
Обчислення значення shared_buffers - цікава головоломка. На неї можна дивитися з двох сторін: якщо у вас невелика база даних, то можна встановити значення shared_buffers досить великим, щоб вся база даних помістилася в оперативній пам'яті. З іншого боку, можна налаштувати завантаження в пам'ять тільки таблиць що часто використовувуються та індексів (згадуйте правило 80/20). Раніше рекомендувалося встановлювати значення в 1/3 від обсягу оперативної пам'яті, але з часом, оскільки обсяги пам'яті росли, воно було зменшено до 1/4. Якщо пам'яті виділено мало, то буде збільшуватися введення-виведення і навантаження на процесор. Ви дізнаєтесь про те що значення shared_buffers встановлено занадо високо коли навантаження на CPU та IO досягнуть плато.
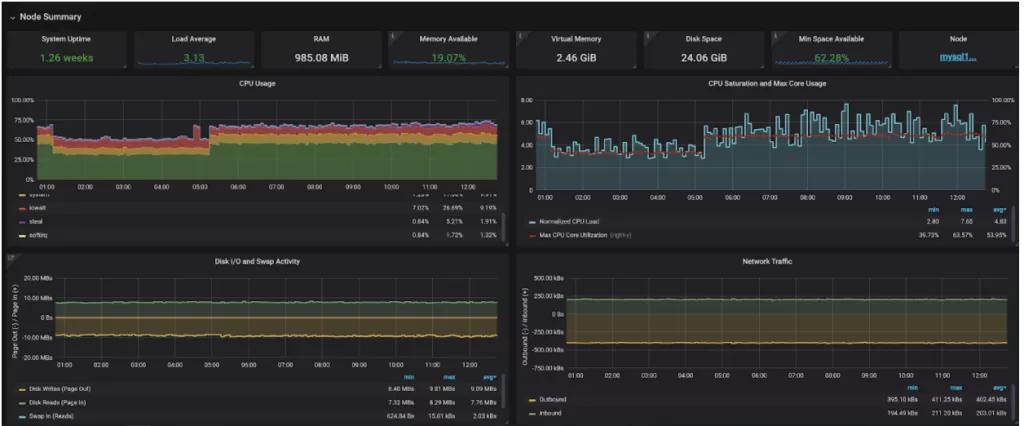 Ще один фактор, який слід враховувати - це кеш ОС . При достатньому обсязі оперативної пам'яті Linux буде кешувати таблиці і індекси в пам'яті і, в залежності від налаштувань, може змусити PostgreSQL повірити в те, що він читає дані з диска, а не з оперативної пам'яті. Одна і та ж сторінка знаходиться і в буфері postgres і в кеші ОС, і це одна з причин не робити shared_buffers дуже великим. За допомогою розширення pg_buffercache можна подивитися використання кеша в реальному часі.
Ще один фактор, який слід враховувати - це кеш ОС . При достатньому обсязі оперативної пам'яті Linux буде кешувати таблиці і індекси в пам'яті і, в залежності від налаштувань, може змусити PostgreSQL повірити в те, що він читає дані з диска, а не з оперативної пам'яті. Одна і та ж сторінка знаходиться і в буфері postgres і в кеші ОС, і це одна з причин не робити shared_buffers дуже великим. За допомогою розширення pg_buffercache можна подивитися використання кеша в реальному часі.
Параметр work_mem задає обсяг пам'яті, який використовується для операцій сортування. Установка дуже низького значення гарантує погану продуктивність, тому що сортування буде виконуватися з використанням тимчасових файлів на диску. З іншого боку, хоча установка великого значення і не впливає на продуктивність, але при великій кількості підключень є ризик нестачі оперативної пам'яті. Проаналізувавши пам'ять яка використовується усіма запитами і сеансами, можна порахувати необхідне значення.
Використовуйте EXPLAIN ANALYZE щоб побачити, як виконуються операції сортування, і змінюючи значення для сеансу, зможете визначити момент, коли починається злив на диск.
Можна також використовувати бенчмарк системи.
Управління підключеннями
Складність: низька.
Потенційний вплив: низький-середній-високий
Високе навантаження зазвичай пов'язане зі збільшенням сесій клієнтів в одиницю часу. Занадто велика їх кількість може блокувати процеси, викликати затримки або навіть призводити до помилок.
Просте рішення - збільшити максимальну кількість одночасних підключень:
# postgresql.conf: default is set to 100
max_connections
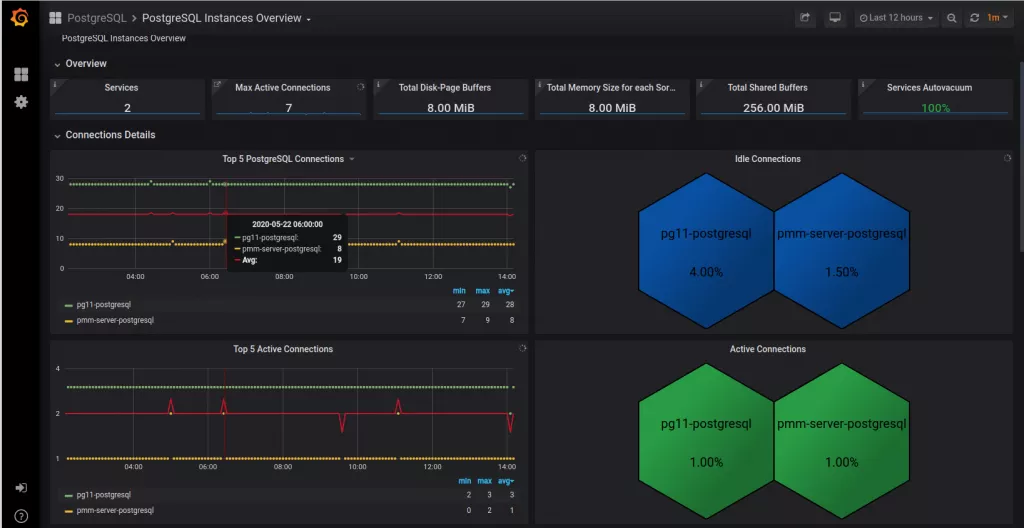 Але ефективніший підхід - пул з'єднань. Існує безліч рішень, але найпопулярніше - pgbouncer. PgBouncer може керувати з'єднаннями, використовуючи один з трьох режимів:
Але ефективніший підхід - пул з'єднань. Існує безліч рішень, але найпопулярніше - pgbouncer. PgBouncer може керувати з'єднаннями, використовуючи один з трьох режимів:
- Пул сеансів (session pooling). Найкоректніший підхід. При підключенні клієнта йому видається з'єднання і залишається за ним, поки він не відключиться. Коли клієнт відключається, підключення повертається в пул. Це метод за замовчуванням.
- Пул транзакцій (transaction pooling). Підключення призначається клієнту тільки на час транзакції. Коли PgBouncer помічає, що транзакція завершена, підключення повертається в пул.
- Пул операторів (statement pooling). Найагресивніший метод. Підключення до сервера буде повертатися в пул відразу після завершення запиту. Транзакції з декількома операторами в цьому режимі заборонені, так як вони будуть перериватися.
Також необхідно звернути увагу на Secure Socket Layer (SSL). При його включенні з'єднання за замовчуванням будуть використовувати SSL, що призведе до збільшення навантаження на процесор в порівнянні з незашифрованими підключеннями. Для звичайних клієнтів можна налаштувати аутентифікацію по імені вузла (host-based) без SSL (pg_hba.conf), а SSL використовувати для виконання адміністративних завдань або для потокової реплікації.
Налаштування автоочищення (autovacuum)
Складність: середня.
Потенційний вплив: низький-середній.
Управління паралельним доступом за допомогою багатоверсійності (Multi-Version Concurrency Control) - один з основоположних принципів, які роблять PostgreSQL таким популярним рішенням серед СУБД. Однак одним з неприємних моментів є те, що для кожної зміненого або видаленого запису створюються невикористовувані копії, від яких в кінцевому підсумку треба позбавлятися. Неправильно налаштований процес автоочищення (autovacuum) може знижувати продуктивність. При цьому чим більше завантажений сервер, тим сильніше виявляється проблема.
Для управління демоном автоочищення використовуються наступні параметри:
- Параметр autovacuum_max_workers . При наявності великої кількості величезних таблиць варто збільшити кількість одночасно працюючих процесів автоочищення (за замовчуванням три). В ідеалі повинен бути один робочий процес на один процесор, але не більше кількості процесорів. Занадто велика кількість може збільшити навантаження на процесор. Зазвичай береться значення між двома цими числами. Це баланс між максимальною ефективністю автоочищення і загальною продуктивністю системи.
- Параметр maintenance_work_mem . Чим більше значення, тим ефективніше процес очищення. Майте на увазі, що є закон спадання віддачі. Занадто велике значення в кращому випадку стане марною тратою оперативної пам'яті, а в гіршому може вичерпати всю доступну пам'ять.
- Параметр autovacuum_freeze_max_age зменшує ймовірність TXID WRAPAROUND. Чим більше це значення, тим рідше він запускається, що знижує навантаження на систему. Але, як і з усіма параметрами автоочищення, згаданими вище, є нюанс. Якщо зробити затримку занадто великою, то і ви ризикуєте вичерпати txid, що призведе до примусового завершення роботи сервера з метою захисту цілісності даних. Для визначення правильного значення необхідно зіставляти найбільший/найстаріший txid з процесом автоочищення використовуючи pg_stat_activity на предмет WRAPAROUND.
Остерігайтеся перевантаження оперативної пам'яті та процесора. Чим вище задане початкове значення, тим більший ризик вичерпання ресурсів при збільшенні навантаження на систему. Якщо встановити занадто великі значення, то продуктивність може різко впасти при перевищенні певного рівня навантаження.
Аналогічно обчисленню work_mem, це значення можна порахувати арифметично або виконати бенчмарки для отримання оптимальних значень .
Додаткове налаштування автоочищення
Складність: висока.
Потенційний вплив: високий.
Цей метод, через його складність, слід використовувати тільки коли продуктивність системи вже на межі фізичних меж хоста і це дійсно стала проблемою.
Runtime-параметри автоочищення налаштовуються в postgresql.conf. На жаль, немає єдиного універсального рішення, яке буде працювати в будь-який високонавантаженій системі.
Параметри зберігання для таблиць. Часто в базі даних значна частина навантаження лягає тільки на кілька таблиць. Налаштування індивідуальних параметрів автоочищення для таблиці - відмінний спосіб не вдаватися до ручного запуску VACUUM, який може суттєво впливати на систему.
Налаштувати таблиці можна за допомогою команди :
ALTER TABLE .. SET STORAGE_PARAMETER
Роздування таблиць (bloat)
Складність: низька.
Потенційний вплив: середній-високий.
Згодом продуктивність системи може погіршуватися через неправильних політик очищення, внаслідок надмірного роздування (bloat) таблиць. Так що навіть налаштування демона автоочищення і ручний запуск VACUUM не вирішує проблему. У цих випадках на допомогу приходить розширення pg_repack .
За допомогою розширення pg_repack можна перебудувати і реорганізувати таблиці та індекси в умовах продакшена
«Гарячі точки» в даних
Складність: висока.
Потенційний вплив: низький-середній-високий.
Як і у випадку з MySQL, позбавлення PostgreSQL від «гарячих точок» залежить від ваших потоків даних і може навіть спричинити за собою зміну архітектури системи.
В першу чергу слід звертати увагу на наступне:
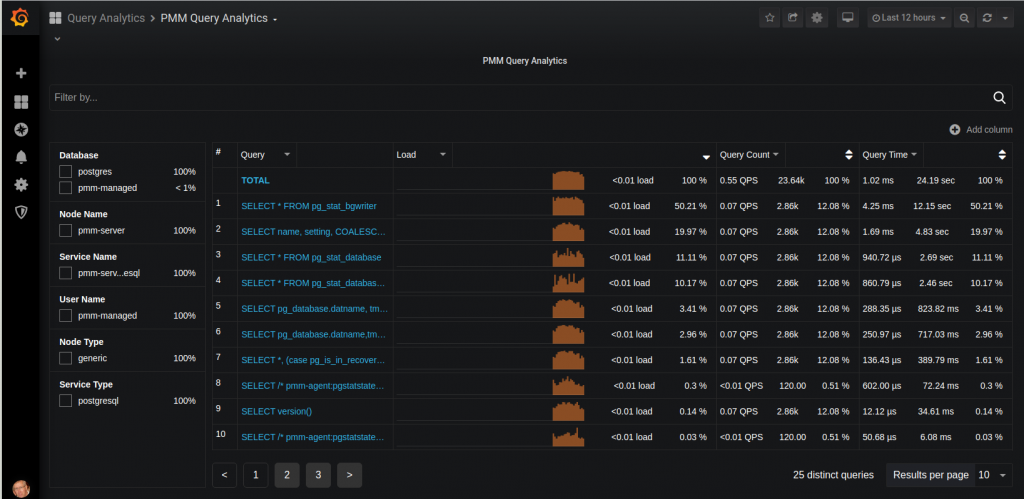
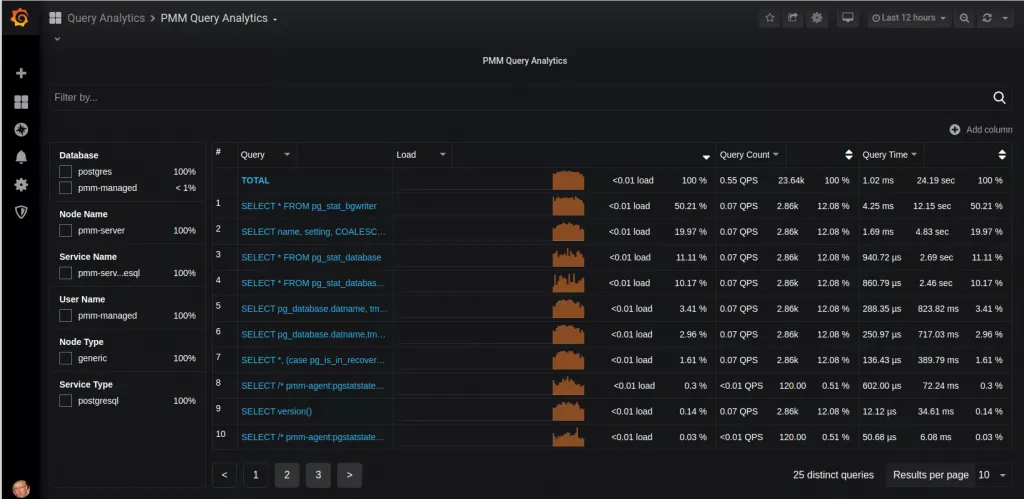
- Індекси. Переконайтеся, що для стовпців, за якими здійснюється пошук є індекси. Можна використовувати системні каталоги та подання для моніторингу і перевірки, що запити використовують індекси. Для аналізу продуктивності запитів використовуйте розширення pg_stat_statement і pgbadger.
- Heap Only Tuples (HOT). Індексів може бути і занадто багато. Знизити потенційне роздування і зменшити розмір таблиці можна, видаливши невикористовувані індекси.
- Секціонування таблиць. Ніщо так не впливає на продуктивність, як величезна таблиця, розмір якої в кілька разів перевищує середній розмір інших таблиць. Розбивка великої таблиці на дрібніші секції допоможе підвищити продуктивність запитів, наприклад, при запиті даних, секціонованих за датою. І оскільки таблиця може оброблятися тільки одним процесом автоочищення, то розбивка його на безліч менших таблиць дозволяє більш ніж одному процесу автоочищення виконувати автоматичне видалення. Ще одна перевага секціонування в тому, що видалення великої кількості рядків набагато ефективніше і швидше, ніж з єдиної величезної таблиці.
- Паралельні запити. З'явилися в останніх версіях postgres. Тепер для виконання одного запиту може використовуватися кілька процесорів, тоді як раніше запит обробляється тільки одним.
- Денормалізація. Можна підвищити продуктивність, об'єднавши стовпці з декількох таблиць в одну таблицю. Підвищення продуктивності досягається за рахунок збільшення надмірності даних. Ретельно обміркуйте цей варіант, перш ніж його використовувати!
 Конкуруючі процеси застосунків
Конкуруючі процеси застосунків
Складність: низька.
Потенційний вплив: високий.
Уникайте запуску застосунків (PHP, Java і Python) і postgres на одному хості. Ставтеся уважно до застосунків на цих мовах, бо вони можуть споживати великі обсяги оперативної пам'яті, особливо збирач сміття, що спричиняє за собою конкуренцію за ресурси з системами баз даних і зниження загальної продуктивності.
Реплікація
Складність: низька.
Потенційний вплив: високий.
Синхронна і асинхронна реплікація. Останні версії postgres підтримують логічну і потокову реплікацію як в синхронному, так і в асинхронному режимах. Хоча за замовчуванням використовується асинхронний режим реплікації, але необхідно враховувати наслідки використання синхронної реплікації, особливо в мережах з істотною затримкою.
Серверне оточення
І останнє, але не менш важливе - це просте збільшення потужності хоста. Давайте розглянемо, на що впливає кожен з ресурсів в плані продуктивності PostgreSQL:
- Оперативна пам'ять. Чим більше більше, тим краще. Велика кількість ОЗУ дозволяє виділити більше пам'яті для запитів і збільшити кількість одночасних сеансів. Чим більше оперативної пам'яті, тим більше кешується база даних, оптимізуючи введення-виведення.
- Процесор. Більше процесорів означає більше паралельних процесів, в тому числі для очищення, підключень і т. Д.
- Жорсткий диск. Збільшення розміру і швидкості.
- збільшення можливого розміру бази даних
- поліпшення загальної продуктивності за рахунок швидшого введення-виведення, особливо для таких операцій як сортування злиттям з використанням диску
- Розбивка на розділи.
- Використання декількох розділів ізолює одночасне виконання операцій. Наприклад, можна рознести індекси і таблиці на різні розділи з різною продуктивністю.
- Для тимчасових сеансових таблиць і таких операцій як сортування злиттям можна виділити окремий високошвидкісний розділ або розподілити їх по більшій кількості розділів.
- На окремому розділі можна розмістити логи. У разі нестачі місця це не вплине на СУБД.
- WAL-логи, як і звичайні логи, теж можна розмістити на окремому розділі, оскільки вони працюють тільки в режимі запису. Якщо місце на розділі закінчиться, що може статися при трансляції журналу (log shipping) і розриві з'єднання з резервним сервером, то таблиці не постраждають, бо вони розташовані в іншому місці.
Джерело: Removing PostgreSQL Bottlenecks Caused by High Traffic

Ще немає коментарів