Сьогодні я буду писати про Django - фреймворк, який вірно служить мені протягом останніх п'яти років. Він допоміг мені досягти успіху в розробці високонавантажених рішень, що використовують сьогодні мільйонами користувачів.
Дійсно, Python не надто «швидка» мову програмування, проте вона проста, зручна і люди її люблять. З точки зору продуктивності, вона не може бути такою ж швидкою, як Go або Node.js, але це стає несуттєвим, якщо розглядати сучасні інфраструктури та модульну розробку.
Оскільки я вже кілька років варюся в цьому «казані розробки на Django», я прийшов до кількох цінних висновків, якими збираюся з вами поділитися.
1. Інфраструктура вирішує
Крім продуктивності застосунку, перше, що вам потрібно - це інфраструктура, яка дозволяє вам здійснювати масштабування, коли застосунок досягає своєї межі, і Django може легко масштабуватися, якщо дотримуватися наступних правил:
- Розділіть свій застосунок на мікросервіси, але враховуйте обсяг даних, переданих між ними, тим більше, що надмірність даних і часта синхронізація стають причиною збільшення серверних ресурсів і комунікацій, а отже, і вищих витрат;
- Використовуйте Docker-контейнери, щоб відправляти свій код в роботу;
- Контейнеризації за допомогою Docker мало, отже, використовуйте Kubernetes, щоб управляти контейнерами та контролювати кількість реплік;
- Проєктуйте свою інфраструктуру з урахуванням технічного обслуговування: правильна дозволить вам збільшувати/зменшувати ресурси сервера без необхідності зупиняти роботу вашого сервісу;
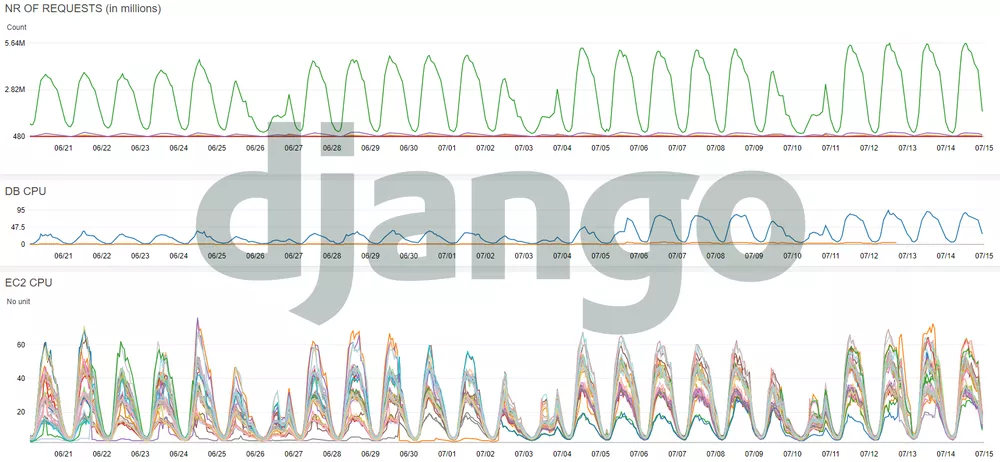
- Збирайте важливі показники та здійснюйте їх моніторинг: кількість запитів по якому-небудь мікросервісу і по кожній кінцевій точці обробки запитів, використання процесора на кожному поді (прим. Пер .: под - абстрактний об'єкт Kubernetes), використання процесора на вузлах Kubernetes, вхідний та вихідний трафік, використання процесора при роботі з базою даних і сховищем. Останнє з перерахованого що дозволить виявляти та розв'язувати проблеми на льоту - крок від традиційної діагностики до випереджувального технічного обслуговування.
2. База даних - ймовірна причина проблем
Яке б прискорення виконання коду ви не отримали, швидше за все воно буде втрачено на стороні бази даних. А саме, швидкість відповіді кінцевої точки обробки запитів залежить від того, наскільки швидко обробляється запит до бази даних, отже, слід перевірити наступне:
- З розумом вибирайте рушій бази даних і зосередьтеся на його продуктивності. Я віддаю перевагу PostgreSQL, тому що він заробив хорошу репутацію за перевірену архітектуру, надійність, безвідмовність, цілісність даних і продуктивність;
- При розгортанні шару зберігання даних сфокусуйтеся переважно на швидкому сховищі та процесорі. Вам напевно потрібно вибрати найкращий варіант за кількістю операцій введення-виведення в секунду (IOPS) і кількості доступних ядер процесора;
- Перевірте, що ви створили всі необхідні індекси для всіх запитів;
- Пам'ятайте, що занадто багато індексів - це погано, тому видаліть невикористовувані або зайві: кожен створений індекс може поліпшити показники тривалості пошуку за відповідним стовпцем (оператор SELECT), але знизить швидкість запису (оператори INSERT, UPDATE). Django може створити деякі повторювані індекси, отже, ви повинні перевірити та видалити їх.
3. Увімкніть журнали налагодження в Django ORM
При розробці надзвичайно важливо стежити за тим, які запити генерує ORM, а також за швидкістю відповіді. Коли ви створюєте кінцеву точку обробки запитів, ви повинні переконатися, що час її відповіді менше ніж 100 мілісекунд - саме тому запити повинні виконуватися не довше 20 мілісекунд.
Щоб включити логи та побачити, за який час виконується кожен запит, використовуйте наступні рядки коду в settings.py:
LOGGING = {
'version': 1,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'level': 'DEBUG',
},
},
'root': {
'handlers': ['console'],
}
}І після перезапуску ви повинні побачити запити в такому форматі:
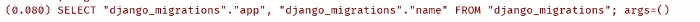
Перше число - це час виконання запиту
Якщо ваш вибір - PostgreSQL, то я рекомендую для перегляду повільних запитів і повторюваних індексів використовувати панель моніторингу продуктивності pghero.
4. Увімкніть постійні з'єднання
Якщо застосунку потрібно обробляти велику кількість запитів, включіть підтримку постійних з'єднань з базою даних. За замовчуванням Django закриває з'єднання в кінці кожного запиту, а постійні з'єднання запобігають подібному навантаженню на базу даних.
Ці з'єднання контролюються параметром CONN_MAX_AGE - показником, який визначає максимальний час існування з'єднання. Встановіть потрібне значення в залежності від вашого обсягу запитів до точки обробки запитів застосунку. Зазвичай я обмежую цей час 5 хвилинами. Переконайтеся, що база даних не обмежена в кількості одночасних з'єднань, яка, як правило, за замовчуванням встановлена в 100 з'єднань, а цього найчастіше мало в разі високого навантаження.
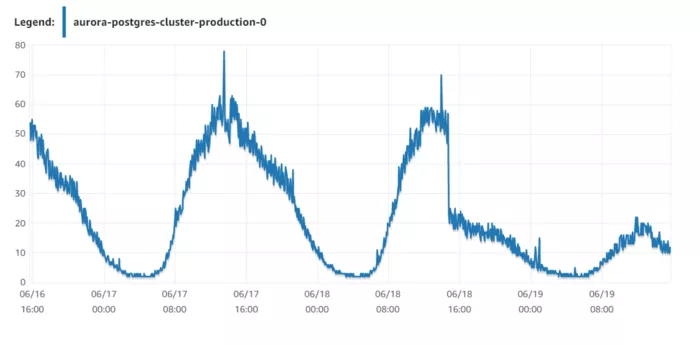
Наприклад, в одному з моїх введених в експлуатацію проєктів після установки цього параметра з 0 до 300 секунд я вдвічі зменшив навантаження на базу даних. Я скористався рушієм бази даних AWS Aurora з інстансами db.r5.8xlarge, переходячи на менш потужний db.r5.4xlarge, щоб скоротити витрати, але, в той самий час, забезпечити достатній рівень продуктивності.
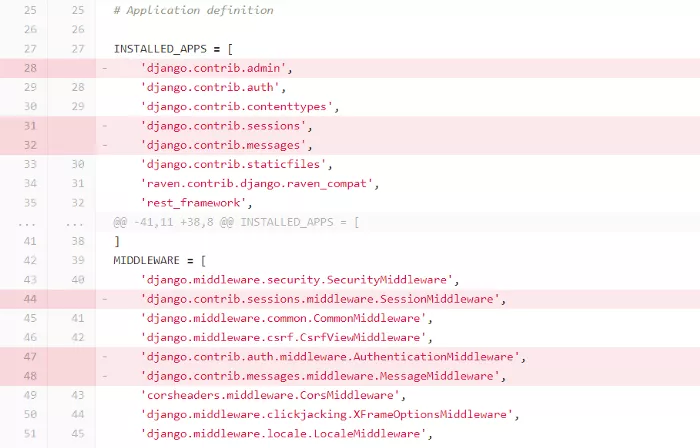
5. Вимкніть програми що не використовуються та проміжні шари (middlewares)
За замовчуванням у фреймворку є кілька включених застосунків, які можуть бути марні, особливо якщо ви використовуєте Django як REST API. Зверніть увагу на сесії (sessions) і повідомлення (messages) - в такому сценарії роботи коли вони не приносять користі й просто витрачали б ресурси та зменшували швидкість обробки. Чим менше проміжних шарів ви оголосили, тим швидше буде оброблятися кожен запит.
6. Використовуйте bulk-запити
Використовуйте bulk-запити, щоб ефективно обробляти великі набори даних і зменшувати кількість запитів до бази даних. Django ORM може виконувати кілька операцій вставки або оновлення в одному SQL-запиті.
Якщо ви збираєтеся вставляти понад 5000 об'єктів, задайте batch_size (прим. Пер.: розмір пакета). Великі пакети також знизять час обробки та високе споживання пам'яті в Python, отже, ви повинні знайти оптимальну кількість елементів, в залежності від розміру об'єкта.

Приклад bulk-запиту в Django
7. Зменште кількість операцій вибірки за допомогою select_related
Якщо у вас є дві пов'язані моделі й потрібно витягти певні властивості з обох, то зробіть попередню вибірку записів через оператор JOIN.
Ось сумний приклад, який ілюструє генерацію 11 непотрібних запитів до бази даних:

З іншого боку, ось правильний спосіб, з генерацією тільки одного запиту:

Використання select_related залежить від розмірів таблиці, оскільки ORM генерує SQL-запит з JOIN. Щоб домогтися оптимізації, умова в операторі WHERE має повертати невелику кількість рядків.
8. Зменште передачу між даними та шаром застосунку (application layer)
Зосередьтеся на істотно важливій інформації з бази даних. Вибірка необов'язкових стовпців збільшує час відповіді від бази даних, приводячи до витрат на передачу даних.
В Django ORM у класу QuerySet є функція .only() для вибору певних полів, або ж ви можете викликати .defer(), щоб повідомити Django про те, що деякі поля з бази даних використовувати не потрібно:

Вибірка імені та електронної пошти з таблиці
9. Зменште передачу даних між своїм API та клієнтами
Подібно суворій вибірці з бази даних, дуже важливо повертати необхідну інформацію з API. Оскільки JSON не найефективніший спосіб пересилання даних, потрібно зменшувати його розмір за допомогою виключення полів, які не використовуються клієнтом програми.
Наприклад: розмір відповіді від певної кінцевої точки обробки запитів становить 1 КБ, але якщо він викликається 1 мільйон разів в день, то щодня буде передаватися 1 ГБ даних, що означає 30 ГБ в місяць - досить велика ціна за використання ресурсу.
Висновок
Звичайно, легко звинувачувати Django або Python, однак, як кажуть мої колеги: «Не звинувачуйте піаніно - звинувачуйте піаніста».
При розробці високонавантаженого проєкту на Django важлива будь-яка дрібниця. Проблеми тонше волосини, помножені на мільйони, призводять до вельми жахливого стану справ, і вам доведеться зайнятися «стрижкою» всіх цих проблем.
Будь-яка зайва мілісекунда, помножена на мільйони запитів, може привести до надмірного споживання ресурсів. Якщо програма вже оптимізовано або добре побудовано, збільшення апаратних ресурсів не врятує положення.
Візьміть приклад з Instagram, Pinterest або Disqus - вони почали з Django «як є», і підняли його на наступний рівень. Звичайно, це, можливо, вже не той же самий фреймворк, однак, якщо в основі лежить здоровий глузд, то це тільки на користь.
Пишіть код ефективно і використовуйте його повторно, користуйтеся bulk-запитами, робіть моніторинг, заміряйте й оптимізуйте. Скоро побачимося.
Оригінал ENG: medium.com

Ще немає коментарів