
Юнікод — це дуже великий та складний світ, адже стандарт дозволяє ні багато ні мало представляти та працювати на комп'ютері з усіма основними письменностями світу. Деякі системи письма існують вже більше тисячі років, причому багато з них розвивалися практично незалежно одна від одної в різних куточках світу. Люди так багато всього придумали і воно часто настільки несхоже один на одне, що об'єднати все це в єдиний стандарт було вкрай непростим і амбітним завданням.
Щоб по-справжньому розібратися з Юнікодом потрібно хоча б поверхово уявляти собі особливості всіх писемностей, з якими дозволяє працювати стандарт. Але чи це так потрібно кожному розробнику? Ми скажемо, що ні. Для використання Юнікоду в більшості повсякденних завдань, достатньо володіти розумним мінімумом відомостей, а далі заглиблюватися в стандарт по мірі необхідності.
У статті ми розповімо про основні засади Юнікоду та висвітлимо ті важливі практичні питання, з якими розробники неодмінно зіткнуться у своїй повсякденній роботі.
Навіщо знадобився Юнікод?
До появи Юнікоду, майже повсюдно використовувалися однобайтні кодування, в яких грань між самими символами, їх поданням в пам'яті комп'ютера і відображенням на екрані була досить умовною. Якщо ви працювали з тією чи іншим національним мовою, то у вашій системі були встановлені відповідні шрифти-кодування, які дозволяли відтворювати байти з диска на екрані таким чином, щоб вони представляли сенс для користувача.
Якщо ви роздруковували на принтері текстовий файл і на паперовій сторінці бачили набір незрозумілих кракозябр, це означало, що у друкуючий пристрій не завантажені відповідні шрифти і вона інтерпретує байти не так, як вам би цього хотілося.
У такого підходу в цілому і однобайтових кодувань зокрема був ряд істотних недоліків:
- Можна було одночасно працювати лише з 256 символами, причому перші 128 були зарезервовані під латинські та керуючі символи, а у другій половині крім символів національного алфавіту потрібно було знайти місце для символів псевдографіки (╔ ╗).
- Шрифти були прив'язані до конкретного кодування.
- Кожне кодування представляло свій набір символів і конвертація з одного в інше була можлива тільки з частковими втратами, коли відсутні символи замінювалися на графічно схожі.
- Перенесення файлів між пристроями під управлінням різних операційних систем також був скрутною справою. Потрібно було або мати програму-конвертер, або тягати разом з файлом додаткові шрифти. Існування Інтернету яким ми його знаємо було неможливим.
- У світі існують не алфавитні системи письма (ієрогліфічне письмо), які в однобайтовому кодуванні неможливо представити в принципі.
Основні принципи Unicode
Всі ми прекрасно розуміємо, що комп'ютер ні про які ідеальних сутності не знає, а оперує бітами і байтами. Але комп'ютерні системи поки створюють люди, а не машини, і для нас з вами іноді буває зручніше оперувати умоглядними концепціями, а потім вже переходити від абстрактного до конкретного.
Важливо! Одним з центральних принципів у філософії Юнікоду є чітке розмежування між символами, їх поданням в комп'ютері і їх відображенням на пристрої виводу.
Вводиться поняття абстрактного юнікод-символу, що існує виключно у вигляді світоглядної концепції і домовленості між людьми, закріпленої стандартом. Кожному юнікод-символу поставлено у відповідність невід'ємне ціле число, назване його кодової позицією (code point).
Так, наприклад, юнікод-символ U+041F — це заголовна кирилична літера П. Існує кілька можливостей подання даного символу в пам'яті комп'ютера, рівно як і кілька тисяч способів відображення його на екрані монітора. Але при цьому П, воно і в Африці буде П або U+041F.
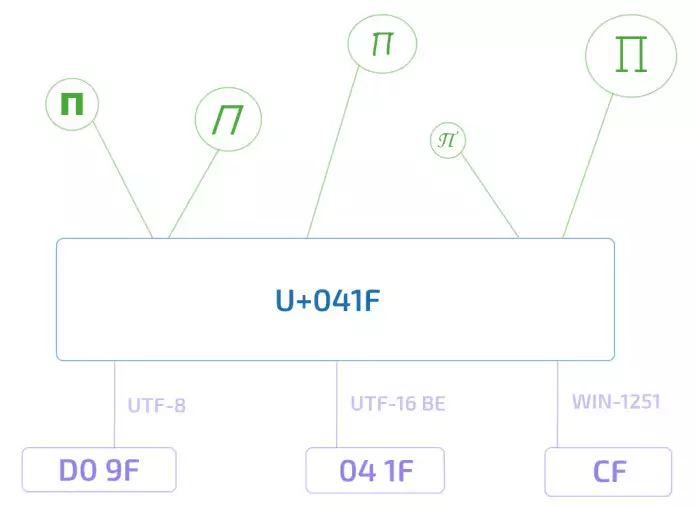
Це добре нам знайома інкапсуляція або відділення інтерфейсу від реалізації — концепція, що відмінно зарекомендувала себе в програмуванні.
Виходить, що керуючись стандартом, будь-який текст можна закодувати у вигляді послідовності юнікод-символів
Привіт
U+041f U+0440 U+0438 U+0432 U+0456 U+0442
записати на листочку, упакувати в конверт і переслати в будь-який кінець Землі. Якщо там знають про існування Юнікод, то текст буде сприйнятий ними рівно так само, як і нами з вами. У них не буде ні найменших сумнівів, що передостанній символ — це саме кирилична рядкова і (U+0456), а не скажімо латинська маленька і (U+0069). Зверніть увагу, що ми ні слова не сказали про байтове подання.
Хоча юнікод-символи і називаються символами, вони далеко не завжди відповідають символу в традиційно-наївному розумінні, наприклад букви, цифри, пунктуаційні знаки або ієрогліфи.
Приклади різних юнікод-символів Існують чисто технічні юнікод-символи, наприклад:
U+0000: нульовий символ;U+D800 – U+DFFF: молодші і старші сурогати для технічного представлення кодових позицій в діапазоні від 10000 до 10FFFF, за межами ББМП/BMP (Базової Багатомовної Площини/Basic Multilingual Plane), у сімействі кодування UTF-16;- і т. д.
Існують пунктуаційні маркери, наприклад U+200F: маркер зміни напряму письма справа-наліво.
Існує ціла когорта пропусків різної ширини і призначення:
U+0020(пробіл);U+00A0нерозривний пробіл, в HTML);U+2002(напівкругла шпація або En Space);U+2003(кругла шпація або Em Space);- і т. д.
Існують комбіновані діакритичні знаки (сombining diacritical marks) — різноманітні штрихи, крапки, тільди і т. д., які змінюють/уточнюють значення попереднього знака і його накреслення. Наприклад:
U+0300іU+0301: знаки основного (гострого) і другорядного (слабкого) наголосів;U+0306: коротка (надрядкова дуга), як й;U+0303: надрядкова тільда;- і т. д.
Існує навіть така екзотика, як мовні теги (U+E0001, U+E0020 – U+E007E, і U+E007F), які зараз знаходяться в підвішеному стані. Вони задумувалися як можливість маркувати певні ділянки тексту які відносяться до того чи іншого варіанту мови (скажімо американський і британський варіант англійської), що могло впливати на деталі відображення тексту.
Що таке символ, чим відрізняється графемный кластер (читай: що сприймається як єдине ціле зображення символу) від юнікод-символу і від кодового кванта ми розповімо наступного разу.
Кодовий простір Unicode
Кодовий простір Юнікоду складається з 1 114 112 кодових позицій в діапазоні від 0 до 10FFFF. З них до дев'ятої версії стандарту значення присвоєно лише 128 237. Частина простору зарезервована для приватного використання і консорціум Unicode обіцяє ніколи не присвоювати значення позиціям з цих спеціальний областей.
Заради зручності весь простір поділено на 17 площин (зараз задіяно шість них). До недавнього часу було прийнято говорити, що швидше за все вам доведеться зіткнутися лише з базовою багатомовною площиною (Basic Multilingual Plane, BMP), що включає в себе юнікод-символи від U+0000 до U+FFFF. (Забігаючи трохи вперед: символи з BMP представляються в UTF-16 двома байтами, а не чотирма). У 2016 році ця теза вже викликає сумніви. Так, наприклад, популярні символи Emoji цілком можуть зустрітися в користувальницькому повідомленні і треба вміти їх коректно обробляти.
Кодування
Якщо ми хочемо переслати текст через Інтернет, то нам потрібно закодувати послідовність юнікод-символів у вигляді послідовності байтів.
Стандарт Юнікод включає в себе опис ряду юнікод-кодувань, наприклад, UTF-8 і UTF-16BE/UTF-16LE, які дозволяють шифрувати весь простір кодових позицій. Конвертація між цими кодуваннями може вільно здійснюватися без втрат інформації.
Також ніхто не відміняв однобайтові кодування, але вони дозволяють закодувати свій індивідуальний і дуже вузький шматочок юнікод-спектра — 256 або менше кодових позицій. Для таких кодувань існують і доступні всім бажаючим таблиці, де кожному значенню єдиного байта зіставлений юнікод-символ (див. наприклад, CP1251.TXT). Незважаючи на обмеження, однобайтні кодування виявляються вельми практичними, якщо мова йде про роботу з великим масивом текстової інформації однією мовою.
З юнікод-кодувань найпоширенішою в Інтернеті є UTF-8 (вона виборола пальму першості у 2008 році), головним чином завдяки її економічності і прозорою сумісністю з семибітною ASCII. Латинські і службові символи, основні знаки пунктуації та цифри — тобто всі символи семибітної ASCII — кодуються в UTF-8 одним байтом, тим же, що і в ASCII. Символи багатьох основних писемностей, не рахуючи деяких рідкісніших ієрогліфічних знаків, представлені в ній двома або трьома байтами. Найбільша з визначених стандартом кодових позицій — 10FFFF — кодується чотирма байтами.
Зверніть увагу, що UTF-8 — це кодування із змінною довжиною коду. Кожен юнікод-символ у ній подається послідовністю кодових квантів з мінімальною довжиною в один квант. Число 8 означає бітову довжину кодового кванта (code unit) — 8 біт. Для сімейства кодування UTF-16 розмір кодового кванта становить, відповідно, 16 біт. Для UTF-32 — 32 біта.
Якщо ви пересилаєте по мережі HTML-сторінку з кириличним текстом, то UTF-8 може дати досить відчутний виграш, оскільки вся розмітка, а також JavaScript і CSS блоки будуть ефективно кодуватися одним байтом. Приміром сторінка займає в UTF-8 - 139Кб, а в UTF-16 вже 256Кб. Для порівняння, якщо використовувати win-1251 із втратою можливості зберігати деякі символи, розмір, порівняно з UTF-8, скоротиться всього на 11Кб до 128Кб.
Для зберігання строкової інформації в застосунках часто використовуються 16-бітні юнікод-кодування в силу їх простоти, а також того факту, що символи основних світових систем письма кодуються одним шіснадцятибітовим квантом. Так, наприклад, Java для внутрішнього представлення рядків успішно застосовує UTF-16. Операційна система Windows всередині себе також використовує UTF-16.
У будь-якому випадку, поки ми залишаємося в просторі Юнікоду, не так вже й важливо, як зберігається символьна інформація в рамках окремого застосунку. Якщо внутрішній формат зберігання дозволяє коректно кодувати всі мільйони з гаком кодових позицій і на кордоні програми, наприклад, при читанні з файлу або копіювання в буфер обміну, не відбувається втрат інформації, то все добре.
Для коректної інтерпретації тексту, прочитаного з мережевого диска або з сокета, необхідно спочатку визначити його кодування. Це робиться або з використанням метаінформації, наданої користувачем, записаної в тексті або поруч з ним, або визначається евристично.
У сухому залишку
- Юнікод постулює чітке розмежування між символами, їх поданням в комп'ютері і їх відображенням на пристрої виводу.
- Юнікод-символи не завжди відповідають символу в традиційно-наївному розумінні, наприклад букви, цифри, пунктуационному знаку або ієрогліфу.
- Кодовий простір Юнікоду складається з 1 114 112 кодових позицій в діапазоні від 0 до 10FFFF.
- Базова багатомовна площину включає в себе юнікод-символи від
U+0000доU+FFFF, які кодуються в UTF-16 двома байтами. - Будь-яке юнікод-кодування дозволяє закодувати весь простір кодових позицій Юнікоду, конвертація між такими різними кодуваннями здійснюється без втрат інформації.
- Однобайтові кодування дозволяють закодувати лише невелику частину юнікод-спектру, але можуть виявитися корисними при роботі з великим об'ємом інформації на одній мові.
- Кодування UTF-8 і UTF-16 володіють змінною довжиною коду. В UTF-8 кожен юнікод-символ може бути закодований одним, двома, трьома або чотирма байтами. В UTF-16 — двома або чотирма байтами.
- Внутрішній формат зберігання текстової інформації в рамках окремого застосунка може бути довільним за умови коректної роботи з усім простором кодових позицій Юнікоду та відсутності втрат при транскордонній передачі даних.
Коротке зауваження про кодування
З терміном кодування може відбутися деяка плутанина. В рамках Unicode кодування відбувається двічі. Перший раз кодується набір символів Юнікоду (character set), в тому сенсі, що кожному юнікод-символу ставиться з відповідність кодова позиція. В рамках цього процесу набір символів Юнікоду перетворюється в кодований набір символів (coded character set). Другий раз послідовність юнікод-символів перетворюється в рядок байтів і цей процес також називається кодування.
В англомовній термінології існують два різних дієслова to code і to encode, але навіть носії мови часто в них плутаються. До того ж термін набір символів (character set або charset) використовується як синонім до терміна кодований набір символів (coded character set).
Ми все це говоримо до того, що має сенс звертати увагу на контекст і розрізняти ситуації, коли мова йде про кодові позиції абстрактного юнікод-символу і коли мова йде про його байтове подання.
Висновок
В Юнікод так багато різних аспектів, що освітити все в рамках однієї статті неможливо. Та й непотрібно. Наведеної вище інформації цілком достатньо, щоб не плутатися в основних принципах і працювати з текстом в більшості повсякденних завдань (читай: не виходячи за рамки BMP)

Коментарі (3)