Використовуючи сучасніші альтернативи поряд зі старими інструментами командного рядка, можна отримати більше задоволення і навіть підвищити продуктивність праці.
У повсякденній роботі в Linux / Unix ми використовуємо безліч інструментів командного рядка - наприклад, du для моніторингу використання диска і системних ресурсів. Деякі з цих інструментів існують вже давно, наприклад, top з'явився в 1984 році, а перший реліз du датується 1971 роком.
За минулі роки ці інструменти були модернізовані та перенесені на різні системи, але в цілому далеко не пішли від своїх перших версій, їх зовнішній вигляд і usability також сильно не змінилися.
Це відмінні інструменти, які необхідні багатьом системним адміністраторам. Однак спільнота розробила альтернативні інструменти, які надають додаткові переваги. Деякі з них просто мають сучасний красивий інтерфейс, а інші значно покращують зручність використання. У цьому перекладі розповімо про п'ять альтернативи стандартним інструментам командного рядка Linux.
1. ncdu vs du
NCurses Disk Usage (ncdu) схожий на du, але з інтерактивним інтерфейсом на основі бібліотеки curses. Ncdu показує структуру каталогів, які займають більшу частину вашого дискового простору.
Ncdu аналізує диск, а потім показує результати, відсортовані по каталогах які найчастіше використовуються або файлів, наприклад:
ncdu 1.14.2 ~ Use the arrow keys to navigate, press ? for help
--- /home/rgerardi ------------------------------------------------------------
96.7 GiB [##########] /libvirt
33.9 GiB [### ] /.crc
7.0 GiB [ ] /Projects
. 4.7 GiB [ ] /Downloads
. 3.9 GiB [ ] /.local
2.5 GiB [ ] /.minishift
2.4 GiB [ ] /.vagrant.d
. 1.9 GiB [ ] /.config
. 1.8 GiB [ ] /.cache
1.7 GiB [ ] /Videos
1.1 GiB [ ] /go
692.6 MiB [ ] /Documents
. 591.5 MiB [ ] /tmp
139.2 MiB [ ] /.var
104.4 MiB [ ] /.oh-my-zsh
82.0 MiB [ ] /scripts
55.8 MiB [ ] /.mozilla
54.6 MiB [ ] /.kube
41.8 MiB [ ] /.vim
31.5 MiB [ ] /.ansible
31.3 MiB [ ] /.gem
26.5 MiB [ ] /.VIM_UNDO_FILES
15.3 MiB [ ] /Personal
2.6 MiB [ ] .ansible_module_generated
1.4 MiB [ ] /backgrounds
944.0 KiB [ ] /Pictures
644.0 KiB [ ] .zsh_history
536.0 KiB [ ] /.ansible_async
Total disk usage: 159.4 GiB Apparent size: 280.8 GiB Items: 561540По записах можна переміщатися за допомогою клавіш зі стрілками. Якщо ви натиснете Enter, ncdu покаже вміст обраного каталогу:
--- /home/rgerardi/libvirt ----------------------------------------------------
/..
91.3 GiB [##########] /images
5.3 GiB [ ] /mediaВи можете використовувати цей інструмент, щоб, наприклад, визначити, які файли займають найбільше дискового простору. У попередній каталог можна перейти, натиснувши клавішу зі стрілкою вліво. За допомогою ncdu ви можете видалити файли, натиснувши клавішу d. Перед видаленням він запитує підтвердження. Якщо ви хочете відключити функцію видалення, щоб запобігти випадковій втраті цінних файлів, використовуйте опцію -r для включення режиму доступу тільки для читання: ncdu -r.
Ncdu доступний для багатьох платформ і дистрибутивів Linux. Наприклад, ви можете використовувати dnf для його установки на Fedora безпосередньо з офіційних репозиторіїв:
$ sudo dnf install ncduАбо sudo apt install ncdu на Ubuntu
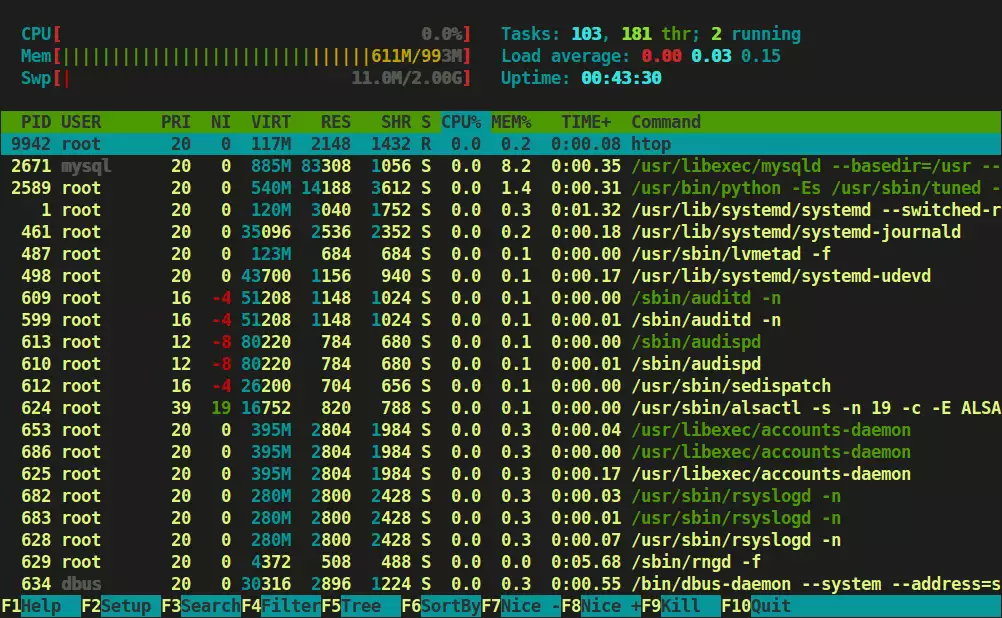
2. htop vs top
Htop - це інтерактивна утиліта для перегляду процесів, схожа на top, але з коробки забезпечує приємну взаємодію з користувачем. За замовчуванням htop показує ту ж інформацію, що і top, але в більш наочному і барвистому вигляді.
За замовчуванням htop виглядає так: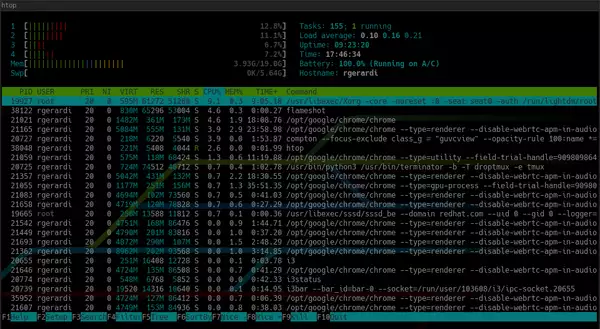
На відміну від top: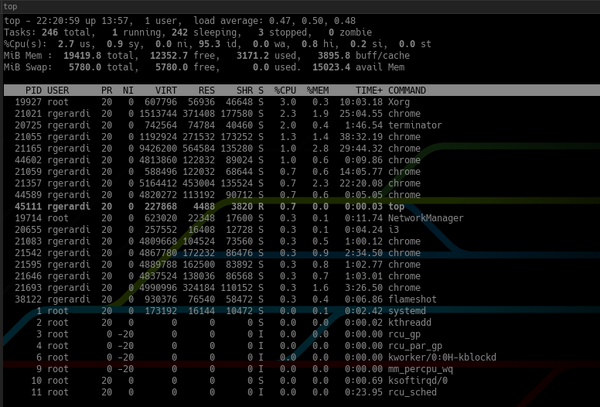
Крім того, у верхній частині htop показує основну інформацію про систему, а нижній частині - панель для запуску команд за допомогою функціональних клавіш. Ви можете налаштувати її, натиснувши F2, щоб відкрити екран налаштування. В налаштуваннях можна змінити кольори, додати або видалити метрики або змінити параметри показу панелі огляду.
Хоча, покрутивши налаштування останніх версій top, теж можна добитися схожого usability, htop надає зручні конфігурації за замовчуванням, що робить його практичнішим і простішим у використанні.
3. tldr vs man
Інструмент командного рядка tldr показує спрощену довідкову інформацію про команди, в основному приклади. Його розробила спільнота tldr pages project.
Варто відзначити, що tldr - це не заміна man. Він як і раніше є канонічним і найповнішим інструментом виведення довідкових сторінок. Однак в деяких випадках man є надмірною. Коли вам не потрібна вичерпна інформація про будь-яку команду, ви просто намагаєтеся запам'ятати основні варіанти її використання. Наприклад, сторінка man для команди curl містить майже 3000 рядків. Сторінка tldr для curl має довжину 40 рядків. Її фрагмент виглядає так:
$ tldr curl
# curl
Transfers data from or to a server.
Supports most protocols, including HTTP, FTP, and POP3.
More information: .
- Download the contents of an URL to a file:
curl http://example.com -o filename
- Download a file, saving the output under the filename indicated by the URL:
curl -O http://example.com/filename
- Download a file, following [L]ocation redirects, and automatically [C]ontinuing (resuming) a previous file transfer:
curl -O -L -C - http://example.com/filename
- Send form-encoded data (POST request of type `application/x-www-form-urlencoded`):
curl -d 'name=bob' http://example.com/form
- Send a request with an extra header, using a custom HTTP method:
curl -H 'X-My-Header: 123' -X PUT http://example.com
- Send data in JSON format, specifying the appropriate content-type header:
curl -d '{"name":"bob"}' -H 'Content-Type: application/json' http://example.com/users/1234
... TRUNCATED OUTPUTTLDR означає «занадто довго; не читав »: тобто, деякий текст був проігнорований через його надмірну багатослівність. Назва підходить для цього інструменту, тому що man-сторінки, хоча і корисні, але іноді бувають занадто довгими.
Для Fedora tldr був написаний на Python. Ви можете встановити його за допомогою менеджера dnf. Зазвичай для роботи інструменту необхідний доступ до інтернету. Але клієнт Python в Fedora дозволяє завантажувати й кешувати ці сторінки для автономного доступу.
4. jq vs sed / grep
jq - це JSON-процесор для командного рядка. Він схожий на sed або grep, але спеціально розроблений для роботи з даними в форматі JSON. Якщо ви розробник або системний адміністратор, який використовує JSON в повсякденних завданнях, цей інструмент для вас.
Більше про команду sed
Основна перевага jq перед стандартними інструментами обробки тексту, такими як grep і sed, полягає в тому, що він розуміє структуру даних JSON, дозволяючи створювати складні запити в одному вираженні.
Наприклад, ви намагаєтеся знайти назви контейнерів в цьому файлі JSON:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"labels": {
"app": "myapp"
},
"name": "myapp",
"namespace": "project1"
},
"spec": {
"containers": [
{
"command": [
"sleep",
"3000"
],
"image": "busybox",
"imagePullPolicy": "IfNotPresent",
"name": "busybox"
},
{
"name": "nginx",
"image": "nginx",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Never"
}
}Запустіть grep для пошуку рядка name:
$ grep name k8s-pod.json
"name": "myapp",
"namespace": "project1"
"name": "busybox"
"name": "nginx",
Grep повернув всі рядки, що містять слово name. Ви можете додати ще кілька параметрів в grep, щоб обмежити його, і за допомогою деяких маніпуляцій з регулярними виразами знайти імена контейнерів.
Щоб отримати цей же результат за допомогою jq, досить написати:
$ jq '.spec.containers[].name' k8s-pod.json
"busybox"
"nginx"Ця команда видасть вам імена обох контейнерів. Якщо ви шукаєте тільки ім'я другого контейнера, додайте індекс елемента масиву в вираз:
$ jq '.spec.containers[1].name' k8s-pod.json
"nginx"Оскільки jq знає про структуру даних, він дає ті ж результати, навіть якщо формат файлу незначно зміниться. grep і sed в цьому випадку можуть не працювати належним чином.
У jq багато функцій, але для їх опису потрібна ще одна стаття. Для отримання додаткової інформації зверніться до сторінки проєкту jq або до tldr.
5. fd vs find
fd - це спрощена альтернатива утиліті find. Fd не покликаний замінити її повністю: в ньому за умовчанням встановлено найпоширеніші налаштування, що визначають загальний підхід до роботи з файлами.
Наприклад, при пошуку файлів в каталозі сховища Git, fd автоматично виключає приховані файли та підкаталоги, включаючи каталог .git, а також ігнорує шаблони з файлу .gitignore. В цілому, він прискорює пошук, видаючи релевантніші результати з першої спроби.
За замовчуванням fd виконує пошук без урахування регістру в поточному каталозі з кольоровим виводом. Той же пошук з використанням команди find вимагає введення додаткових параметрів в командному рядку. Наприклад, щоб знайти всі файли .md (або .MD) в поточному каталозі, потрібно написати таку команду find:
$ find . -iname "*.md"Для fd вона виглядає так:
$ fd .mdАле в деяких випадках і для fd потрібні додаткові параметри: наприклад, якщо ви хочете включити приховані файли та каталоги, ви повинні використовувати опцію -H, хоча зазвичай при пошуку це не потрібно.
fd доступний для багатьох дистрибутивів Linux. У Fedora його можна встановити так:
$ sudo dnf install fd-findНеобов'язково від чогось відмовлятися
Чи використовуєте ви нові інструменти командного рядка Linux? Або сидите виключно на старих? Але швидше за все, у вас комбо, так? Будь ласка, поділіться вашим досвідом в коментарях.

Ще немає коментарів