Якщо реляційні бази даних стандартизовані, то повнотекстовий пошук — досі ні. Існує кілька його варіантів відкритим кодом, наприклад ElasticSearch, Solr та Xapian. ElasticSearch — чи не найпопулярніше рішення, однак його складно налаштовувати та підтримувати.
Крім того, якщо ви не користуєтеся певними додатковими функціями ElasticSearch, вам варто звернутись до можливостей повнотекстового пошуку, які пропонують багато реляційних (як-от Postgres, MySQL, SQLite) та нереляційних баз даних (як-от MongoDB та CouchDB). Зокрема Postgres добре підходить для повнотекстового пошуку. Django також підтримує його одразу з коробки.
Для більшості Django-застосунків вам слід принаймні почати з повнотекстового пошуку з Postgres. Після цього вже можна шукати функціональніше рішення, таке як ElasticSearch або Solr.
Поки що ми розповімо, як додати базовий та повнотекстовий пошук до Django-застосунку за допомогою Postgres.
Мета
У цій статті ми навчимося:
Налаштовувати базовий пошук у Django-застосунку з об'єктом Q.
Додавати повнотекстовий пошук до Django-застосунку.
Впорядковувати результати повнотекстового пошуку за відповідністю (через стемінг, ранжування та визначення ваги).
$ git clone https://github.com/testdrivenio/django-search --branch base --single-branch
$ cd django-search
Ми користуватимемося Docker для простішого налаштування та запуску Postgres разом з Django.
З кореневої директорії проєкту створіть образи та запустіть контейнери Docker:
$ docker-compose up -d --build
Далі виконайте міграції та створіть суперкористувача:
$ docker-compose exec web python manage.py migrate
$ docker-compose exec web python manage.py createsuperuser
Тоді перейдіть до http://127.0.0.1:8011/quotes/, щоб переконатися, чи застосунок працює як слід. Ви маєте побачити таке:
Зверніть увагу на модель `Quote` у quotes/models.py:
```
from django.db import models
class Quote(models.Model):
name = models.CharField(max_length=250)
quote = models.TextField(max_length=1000)
def __str__(self):
return self.quote
```
Запустіть цю команду керування, щоб додати 10 000 цитат до бази даних:
```
$ docker-compose exec web python manage.py add_quotes
```
Це триватиме кілька хвилин. Коли буде готово, перейдіть до [http://127.0.0.1:8011/quotes/](http://127.0.0.1:8011/quotes/), щоб переглянути дані:
У файлі *quote/templates/quote.html* ми маємо базову форму з полем пошуку:
```
```
Під час подання формою пошуку надсилається запит `GET`, а не `POST`, тому ми маємо доступ до рядка запиту і в URL-адресі, і у Django view. В URL-адресі з'являється рядок запиту, тож ми можемо поділитися ним з іншими як посиланням.
Перш ніж рухатися далі, побіжно перегляньте структуру проєкту та решту коду.
## Базовий пошук
Почнімо наше дослідження пошуку з огляду [об'єктів Q](https://docs.djangoproject.com/en/3.2/topics/db/queries/#complex-lookups-with-q-objects), які дозволяють нам шукати слова, за допомогою логічних операторів AND (`&`) або OR (`|`).
Наприклад, застосовуємо оператор OR, щоб перевизначити типове значення `QuerySet` для `SearchResultsList` у *quote/views.py*:
```
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.filter(
Q(name__icontains=query) | Q(quote__icontains=query)
)
```
Тут ми застосували метод [filter](https://docs.djangoproject.com/en/3.2/topics/db/queries/#retrieving-specific-objects-with-filters) для фільтрації поля `name` або `quote`. Ми також скористалися тестом [icontains](https://docs.djangoproject.com/en/3.2/ref/models/querysets/#icontains), щоб перевірити, чи є в полях введене слово (без урахування регістру). Якщо воно там є, це поле буде повернуто.
Не забуваємо про імпорт:
```
from django.db.models import Q
```
Пробуємо:
Для невеликих наборів даних це чудовий спосіб додати базову функціональність пошуку до застосунку. Коли ваші набори даних збільшаться, а вміст, який ви шукаєте, стане об'ємнішим, вам знадобиться вже повнотекстовий пошук.
## Повнотекстовий пошук
Базовий пошук, який ми розглянули раніше, має деякі вади, особливо коли ми шукаємо збіги у великих наборах даних.
Перша вада — це [слова зупинки](https://uk.wikipedia.org/wiki/%D0%A8%D1%83%D0%BC%D0%BE%D0%B2%D1%96_%D1%81%D0%BB%D0%BE%D0%B2%D0%B0). Прикладами таких слів є «a», «an» та «the». Ці слова є загальними та недостатньо значущими, тому ними слід нехтувати. Щоб перевірити це, спробуйте знайти слово з «the». Скажімо, ви шукали «the middle». У цьому разі ви побачите результати лише для «the middle», тобто ви не отримаєте результатів, у яких перед словом «middle» не стоїть слово «the».
Наприклад, ви маєте два речення:
I am in the middle.
You don't like middle school.
Ось що повертатиме кожен тип пошуку:
Запит
Базовий пошук
Повнотекстовий пошук
«the middle»
Речення 1
Речення 1 і 2
«middle»
Речення 1 і 2
Речення 1 і 2
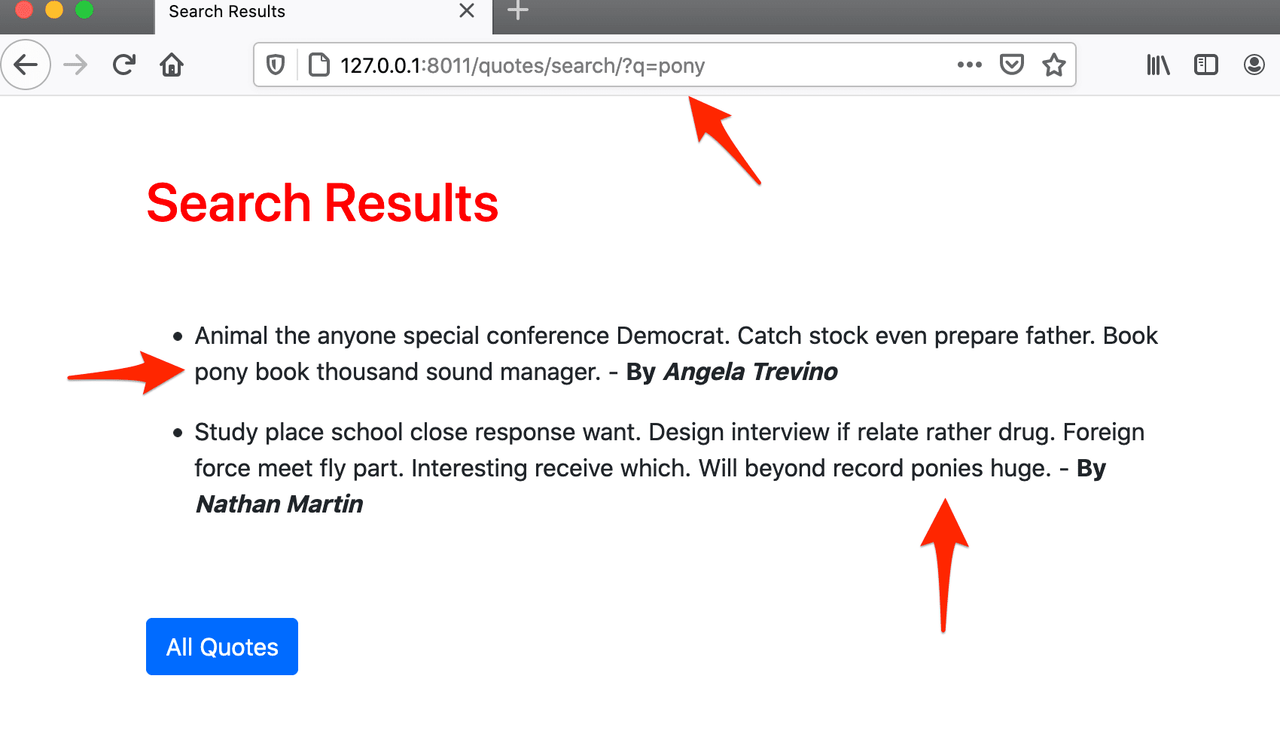
Інша вада — схожі слова. У базовому пошуку повертаються лише точні збіги, це досить обмежує. За допомогою повнотекстового пошуку ми можемо враховувати схожі слова. Щоб перевірити, спробуйте знайти, наприклад, «pony» та «ponies». У базовому пошуку, якщо ви шукаєте «pony», ви не побачите результатів, що містять «ponies», і навпаки.
Наприклад, ви маєте два речення:
I am a pony.
You don't like ponies
Ось що повертатиме кожен тип пошуку:
Запит
Базовий пошук
Повнотекстовий пошук
«pony»
Речення 1
Речення 1 і 2
«ponies»
Речення 2
Речення 1 і 2
Обидві ці вади нівелюються у повнотекстовому пошуку. Майте на увазі, що залежно від мети повнотекстовий пошук може знизити точність (якість) та кількість відповідних результатів. Як правило, повнотекстовий пошук менш точний, ніж базовий, оскільки базовий дає точні збіги до пошукового запиту. Отже, якщо ви шукаєте у великих наборах даних з великими блоками тексту, повнотекстовий пошук буде кращим, оскільки він зазвичай набагато швидший.
Повнотекстовий пошук — це вдосконалена техніка, яка перевіряє всі слова у кожному збереженому документі, намагаючись знайти відповідники критеріям пошуку. Тут слова-зупинки «a», «an» та «the» пропускаються, оскільки вони є загальними та недостатньо значущими. Крім того, у повнотекстовому пошуку ми можемо застосовувати притаманний певній мові пошук за основою шуканого слова (стемінг). Наприклад, слово «drives», «drove» та «driven» буде записано під єдиним поняттям «drive». Стемінг — це процес зведення слів до їхньої основи або кореневої форми.
Варто зауважити, що повнотекстовий пошук не є досконалим — адже є ймовірність отримати безліч помилкових збігів у відповідь на запит. Однак існують деякі методи, що базуються на Баєсових алгоритмах і допомагають скоротити кількість цих проблем.
Щоб скористатися перевагами повнотекстового пошуку Postgres за допомогою Django, додайте django.contrib.postgres у свій список INSTALLED_APPS:
Тепер гляньмо на два короткі приклади повнотекстового пошуку, у одному полі та у кількох полях.
Пошук в одному полі
Оновлюємо SearchResultsList:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.filter(quote__search=query)
Тут ми шукаємо лише цитату з поля пошуку.
Як бачите, пошук враховує схожі слова: наприклад, «ponies» та «pony» у нашому прикладі.
### Пошук у кількох полях
Щоб фільтрувати поєднання полів та пов'язаних з ними моделей, ви можете скористатися класом [SearchVector](https://docs.djangoproject.com/en/3.1/ref/contrib/postgres/search/#searchvector).
Знову ж, оновлюємо `SearchResultsList`:
```
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.annotate(search=SearchVector("name", "quote")).filter(
search=query
)
```
Щоб шукати у кількох полях, нам довелося [уточнювати](https://docs.djangoproject.com/en/3.2/topics/db/aggregation/) запит за допомогою `SearchVector`.
Обов'язково додайте імпорт:
```
from django.contrib.postgres.search import SearchVector
```
Спробуйте здійснити пошук.
## Стемінг і ранжування
У цьому розділі ми поєднаємо методи [SearchVector](https://docs.djangoproject.com/en/3.1/ref/contrib/postgres/search/#searchvector), [SearchQuery](https://docs.djangoproject.com/en/3.1/ref/contrib/postgres/search/#searchquery) та [SearchRank](https://docs.djangoproject.com/en/3.1/ref/contrib/postgres/search/#searchrank), щоб отримати точніший пошук, який використовує і стемінг, і ранжування.
Повторимося, стемінг — це процес зведення слів до їхньої основи, або кореневої форми. Наприклад child та children вважатимуться схожими словами. Водночас ранжування дозволяє нам упорядковувати результати за відповідністю.
Оновлюємо `SearchResultsList`:
```
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", "quote")
search_query = SearchQuery(query)
return (
Quote.objects.annotate(
search=search_vector, rank=SearchRank(search_vector, search_query)
)
.filter(search=search_query)
.order_by("-rank")
)
```
Що тут відбувається?
1. `SearchVector` — застосовується для пошуку за кількома полями.
2. `SearchQuery` — обробляє слова із форми запиту, проводить їх через стемінговий алгоритм, знаходить кореневу форму, а потім шукає збіги для всіх отриманих термінів.
3. `SearchRank` — дозволяє нам упорядковувати результати за відповідністю. Він враховує, як часто терміни запиту з'являються в документі, наскільки вони близькі в документі та наскільки важлива частина, де вони трапляються.
Додаємо імпортування:
```
from django.contrib.postgres.search import SearchVector, SearchQuery, SearchRank
```
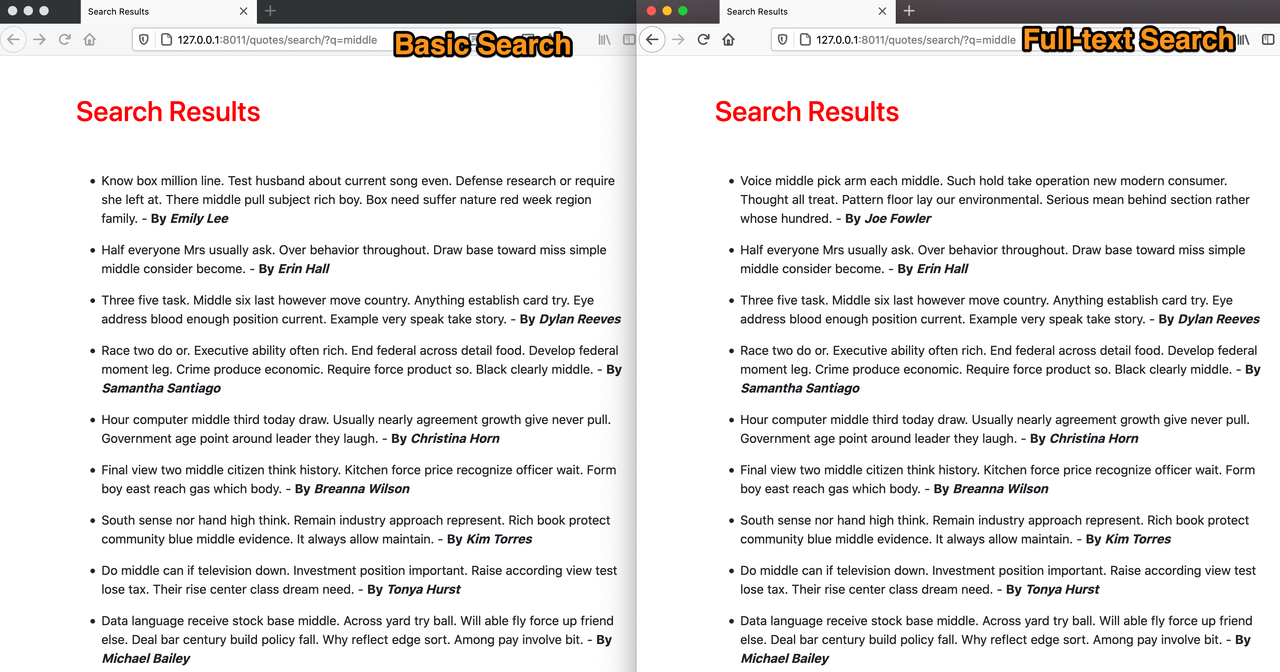
Порівняйте результати базового пошуку з результатами повнотекстового пошуку. Є помітні відмінності. У повнотекстовому пошуку спочатку показано найвідповідніші результати. У цьому перевага `SearchRank`. Поєднання `SearchVector`, `SearchQuery` та `SearchRank` — це швидкий спосіб отримати значно потужніший та точніший механізм, ніж базовий пошук.
## Додавання ваги
Повнотекстовий пошук дає нам можливість додати більшої важливості деяким полям у нашій таблиці бази даних. Ми можемо зробити це, додавши ваги нашим запитам.
[Вага](https://docs.djangoproject.com/en/3.2/ref/contrib/postgres/search/#postgresql-fts-weighting-queries) позначається однією з таких букв: D, C, B, A. Типово вони посилаються до числа 0,1, 0,2, 0,4 та 1,0 відповідно.
```
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", weight="B") + SearchVector(
"quote", weight="A"
)
search_query = SearchQuery(query)
return (
Quote.objects.annotate(rank=SearchRank(search_vector, search_query))
.filter(rank__gte=0.3)
.order_by("-rank")
)
```
Тут ми додали ваги до `SearchVector` за допомогою полів `name` і `quote`. Ми застосували ваги 0,4 та 1,0 до полів `name` та `quote` відповідно. Тому збіги полів `quote` мають перевагу над збігами вмісту `name`. Потім ми впорядкували результати, щоб показати лише ті, вага яких більша за 0,3.
## Підсумуємо
Хоча повнотекстовий пошук швидкий, він може працювати повільно, коли є понад кілька сотень записів, через його прискіпливість. Щоб все відбувалось швидше, ви можете створити функціональний індекс, який збігатиметься з потрібним вам вектором пошуку. Цей підхід слід застосовувати, лише якщо ви помічаєте зниження швидкості. Щоб отримати додаткові відомості, перегляньте розділ [Performance](https://docs.djangoproject.com/en/3.2/ref/contrib/postgres/search/#performance) у документації Django про повнотекстовий пошук.
У цій статті ми розповіли вам, як налаштувати можливості базового пошуку Django-застосунку та розширити його до повнотекстового пошуку за допомогою модуля Postgres від Django.
Ви можете переглянути весь код у репозиторії [django-search](https://github.com/testdrivenio/django-search).


Ще немає коментарів