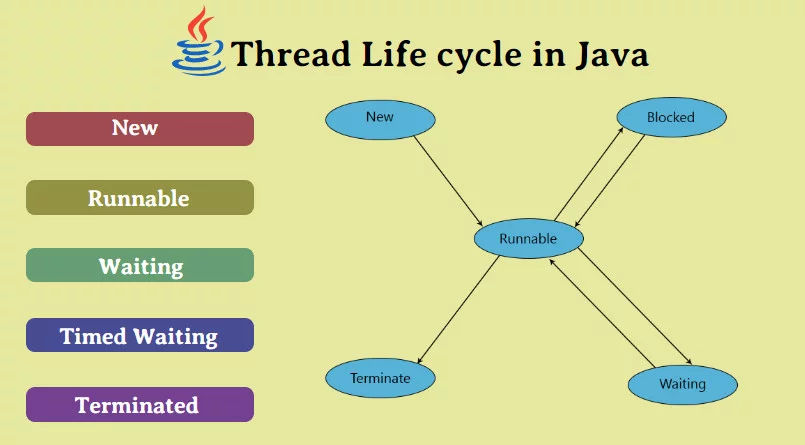
Ця стаття спрямована на пояснення різних станів потоку в світі Java. Якщо ви новачок в області багатопотокового програмування, спробуйте спочатку почитати про потоки що-небудь базове.
Згідно Sun Microsystems, існує чотири стану життєвого циклу потоку Java. Ось вони:
- New - потік знаходиться в стані
New, коли створюється екземпляр об'єкта класуThread, але методstartне викликається. - Runnable - коли для об'єкта
Threadбув викликаний методstart. У цьому стані потік або очікує, що планувальник забере його для виконання, або вже запущений. Назвемо стан, коли потік вже обраний для виконання, "працюючим" (running) . - Non-Runnable (Blocked, Timed-Waiting) - коли потік живий, тобто об'єкт класу
Threadіснує, але не може бути обраний планувальником для виконання. Він тимчасово не працює. - Terminated - коли потік завершує виконання свого методу
run, він переходить в станterminated(завершений). На цьому етапі завдання потоку завершується.
Нижче дано схематичне представлення життєвого циклу потоку в Java:
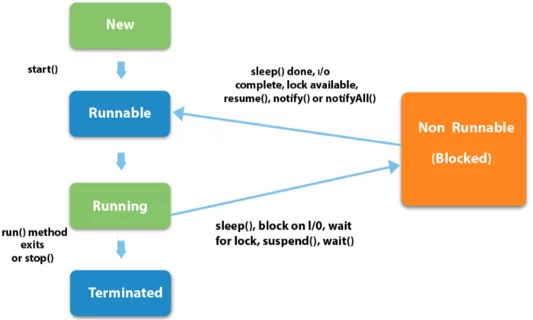
Хвилиночку! Звучить чудово, але що це за "планувальник" такий? Я викликав метод start, так чому б системі просто не запустити мій потік, а не чекати в робочому стані, поки планувальник його не підбере?
Гарне питання! Планувальник - це програмне забезпечення, яке використовується для відстеження завдань комп'ютера. Він відповідає за виділення ресурсів завданням, які можуть здійснювати роботу. Ми не будемо заглиблюватися в логіку, яку реалізує планувальник. На даний момент досить знати, що планувальник має контроль над тим, який апаратний ресурс має виділитися якому завданню, і коли, виходячи з доступності ресурсу і стану завдання.
Виходить, планувальник вирішує, коли видляти завданню необхідний ресурс. Але як завдання переходить в неробочий стан? Як і чому потік повинен відмовитися від процесорного часу і призупинити виконання? Це відбувається за вибором чи вимушено?
Що ж. Потік може перебувати в неробочому стані з різних причин - іноді примусово, іноді за власним вибором. Вимушені причини можуть полягати в тому, що він очікує операції введення-виведення, наприклад отримання повідомлення по порту, або він може чекати об'єкт, який утримується іншим потоком. Останній сценарій призводить до появи синхронізованого об'єкта. Коли потік звертається до синхронізованому об'єкту, він створює блокування на цьому об'єкті.
Блокування - це щось на зразок тимчасового контракту між потоком і об'єктом, який дає потоку ексклюзивний доступ до об'єкта, забороняючи доступ будь-якого іншого потоку. Для забезпечення цього контракту Java пов'язує з кожним об'єктом монітор. Потік також може бути переміщений планувальником в неробочий стан (сплячий режим) на основі логіки спільного використання ресурсів планувальника.
Потоки можуть перейти в неробочий стан за вибором. Тобто за вибором програміста. Програміст може написати метод потоку (run або будь-який інший метод, який викликається всередині run) таким чином, щоб той навмисно поступався процесорним часом. Так робиться, щоб отримати максимальну віддачу від доступних обчислювальних потужностей або викликати затримки після виконання певної частини потоку. Давайте подивимося, які методи добровільної відмови від процесорного часу нам доступні:
- sleep(long millis) - цей метод ініціює сплячий режим на час, вказаний в якості параметра. Важливо відзначити, що при виклику
sleepпотік віддає процесорний час, але блокування об'єктів не відміняються. Після виходу із сплячого режиму потік повертається в робочий стан, чекаючи, поки планувальник забере його для виконання. Це зазвичай застосовується для виклику затримки в частині виконання потоку. - wait() або wait(long timeout) - цей метод змушує потік відмовитися від процесорного часу, а також зняти будь-які блокування об'єктів. Він може бути викликаний з параметром
timeout. При виклику без тайм-ауту потік залишається в непрацюючому стані нескінченно, поки інший потік не викличе методnotify()абоnotifyAll(). Коли ви викликаєтеметод з параметромtimeoutпотік очікує не більше тривалості тайм-ауту, а потім автоматично переходить в станrunnable. Цей метод необхідний в ситуаціях, коли кілька потоків повинні працювати синхронно. - yield() - цей метод є свого роду повідомленням планувальнику про те, що потік готовий відмовитися від виконання. Потім планувальник, грунтуючись на інших наявних потоках і їх пріоритетів, вирішує: чи хоче він перемістити потік в стан
runnableі надати процесорний час іншим потокам або продовжувати виконувати існуючий потік. Особисто мені цей метод здається вельми корисним. Якщо ми знаємо, що виконання методу/функції займе багато часу і що завдання не є терміновим, ми можемо написати її зі стратегічно розташованими викликами методуyield, щоб планувальник міг використовувати процесор для виконання потоків з вищим пріоритетом і коротшим часом виконання. - join() - викликається для припинення виконання програми до тих пір, поки потік, що викликає метод
joinне буде завершений.
Час забруднити руки! Напишемо невеликий код, щоб створити кілька потоків і перевірити їх стан на впродовж всього виконання.
Просте виконання єдиного потоку
package multithreadingPackage;
class Thread1 implements Runnable{
@Override
public void run() {
System.out.println("We are inside the run function."
+ "The thread is in the \"" + Thread.currentThread().getState() + "\" state.");
}
}
public class BasicThreadLifeCycleDemo{
public static void printThreadState(Thread threadToCheck) {
System.out.println("The thread is in the \"" + threadToCheck.getState() + "\" state.");
}
public static void main(String[] args) {
Thread t1 = new Thread(new Thread1());
printThreadState(t1);
t1.start();
printThreadState(t1);
for(int i=0; i<=10000; i++) {
for(int j=0; j<=10000; j++) {
}
}
printThreadState(t1);
}
}
Цей код виведе наступне:

Давайте спробуємо зрозуміти, що тут відбувається.
Функція printThreadState виводить поточний стан потоку. Вперше вона викликається після створення екземпляра об'єкта Thread, і її вивід відповідає тому, що ми побачили нещодавно. Потік виявився в стані new. Тепер уважно спостерігайте за виводом.
Після методу start ми виконали метод printThreadState, і потік перейшов в стан runnable. Це відбувається до того, як планувальник передав потік для виконання, тому що якби потік вже був запущений, ми отримали б у виводі інструкцію print, написану всередині методу run класу Thread1. Звідси можна бачити, що потік виконується.
Також читайте про: Метод Гауса на Java
Зверніть увагу, що потік так і знаходиться в стані runnable, оскільки, як згадувалося на початку цієї статті, Java визначає тільки чотири стану в життєвому циклі потоку. Стан running фігурує в цій статті тільки для спрощення розуміння.
Нарешті, після завершення виконання методу run, потік теж завершується, а потім знищується. Цикли for в програмі існують лише для того, щоб дати потоку достатньо часу для завершення виконання.
2. Виконання декількох потоків
1. Вплив синхронізації
Тепер давайте розглянемо сценарії з синхронізованими блоками коду. Ми напишемо програму для запуску двох потоків, які намагаються отримати доступ до одного і того ж екземпляру класу. Ми запустимо програму двічі: один раз без ключового слова synchronized в оголошенні методу і один раз з ключовим словом synchronized.
package multithreadingPackage.objectsForDemo;
public class Person implements Runnable {
private String name;
private String job;
private String address;
public Person(String name, String job, String addr){
this.name = name;
this.job = job;
this.address = addr;
}
/*Non-synchronized version.
To convert this to synchronized block, replace method declaration with
public synchronized void printPersonDetails(){ */
public void printPersonDetails() {
String threadName = Thread.currentThread().getName();
System.out.println("-------------------------------");
System.out.println(threadName + " holds lock?- " + Thread.currentThread().holdsLock(this));
System.out.println(threadName + " Name - " + this.name);
System.out.println(threadName + " Job - " + this.job);
System.out.println(threadName + " Address - " + this.address);
System.out.println("-------------------------------");
}
@Override
public void run() {
printPersonDetails();
}
}
package multithreadingPackage;
import multithreadingPackage.objectsForDemo.Person;
public class SynchronizationDemo{
public static void printThreadState(Thread threadToCheck) {
System.out.println("Thread \"" + threadToCheck.getName() + "\" is in the \"" + threadToCheck.getState() + "\" state.");
}
public static void main(String[] args) {
Person person = new Person("Rajat", "Blogger", "Ireland");
Thread t1 = new Thread(person);
t1.setName("FirstThread");
Thread t2 = new Thread(person);
t2.setName("SecondThread");
t1.start();
t2.start();
}
}
На рис. 3 показаний вивід без ключового слова synchronized, а на рис. 4 - з ключовим словом synchronized.


Чому вивід такий рандомний? 🤔
Тому що два потоки виконуються паралельно. Зверніть увагу: статус блокування потоків false, тому будь-який потік може отримати доступ до об'єкта в один і той самий час.
А оскільки ми використовували ключове слово synchronized для отримання виводу на рис.4, то перший потік, який отримав доступ до об'єкта, утримував його блокування. Це перепиняло іншому потоку доступ до об'єкта до завершення виконання першого потоку.
2. Методи "sleep" і "yield"
public void printPersonDetails() {
String threadName = Thread.currentThread().getName();
System.out.println("-------------------------------");
System.out.println(threadName + " holds lock?- " + Thread.currentThread().holdsLock(this));
if(threadName.equals("FirstThread")) {
try {
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(threadName + " Name - " + this.name);
System.out.println(threadName + " Job - " + this.job);
System.out.println(threadName + " Address - " + this.address);
System.out.println("-------------------------------");
}
public static void main(String[] args) {
Person person = new Person("Rajat", "Blogger", "Ireland");
Thread t1 = new Thread(person);
t1.setName("FirstThread");
Thread t2 = new Thread(person);
t2.setName("SecondThread");
t1.start();
t2.start();
for(int i=0; i<=10000; i++) {
for(int j=0; j<=10000; j++) {
}
}
printThreadState(t1);
}
Змініть код в файлах SynchronizationDemo.java і Persons.java, як показано в наведеному вище фрагменті коду. Запустіть код як в синхронізованому, так і в несинхронізованому режимах. Ми переводимо перший потік в сплячий режим на дві секунди, як тільки починається його виконання.

Як і очікувалося, в несинхронізованому режимі обидва потоки не утримують ніякого блокування на об'єкті. FirstThread переходить в Timed_Waiting при виклику методу sleep. Другий потік продовжує виконання, бо немає блокування його доступу до об'єкта.

У синхронізованому режимі потоки утримують блокування, і тому, навіть коли перший потік знаходиться в стані Timed_Waiting, другий потік все одно не може отримати доступ до об'єкта.
Тепер замініть метод sleep на yield і видаліть блок try-catch у файлі Persons.java. Результат буде таким же, як і в розділі 2.1. Цей метод буде корисний для завдань, які вимагають великих обчислювальних потужностей, але не такі термінові.
3. Методи "wait" і "notify"
Що робити, якщо ми не хочемо, щоб потік закінчував виконання, поки якийсь інший потік не скаже йому продовжити?
Навіщо це нам?
Припустимо, у нас є обліковий запис у постачальника широкосмугових мережевих послуг і ми хочемо додати на баланс ще даних. Якщо у нашого облікового запису недостатньо коштів, ми не зможемо поповнити рахунок для передачі даних. Таким чином, постачальник послуг буде чекати, поки ми додамо на аккаунт кошти, щоб завершити дозакупку. Давайте поглянемо на код.
package multithreadingPackage;
class BroadbandAccount{
private double dataInGb;
private double moneyInEuros;
public BroadbandAccount(double data, double money){
this.dataInGb = data;
this.moneyInEuros = money;
}
public synchronized void addData() {
System.out.println("Current balance = " + this.moneyInEuros);
if(moneyInEuros<20) {
System.out.println("You don't have enough balance. Waiting for you to add money");
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("Adding data and deducting money");
this.moneyInEuros -= 20;
this.dataInGb += 20;
System.out.println("Remaining Balance = " + this.moneyInEuros + ". Remaining data = " + this.dataInGb);
}
public synchronized void addMoney() {
System.out.println("Adding 20 Euros");
this.moneyInEuros += 20;
System.out.println("Added. New balance = " + this.moneyInEuros);
notify();
}
}
public class WaitNotifyImplementationDemo{
public static void main(String[] args) {
BroadbandAccount account = new BroadbandAccount(1, 10);
new Thread() {
public void run() {
account.addData();
}
}.start();
new Thread() {
public void run() {
account.addMoney();
}
}.start();
}
}
Зверніть увагу, що методи потоку синхронізовані, тому тільки один потік одноразово може отримати доступ до об'єкта BroadBandAccount. Вивід цього коду буде залежати від того, який потік був обраний планувальником першим. Якщо другий потік, тобто потік додавання грошей, буде виконаний першим, то грошей буде достатньо для поповнення рахунку і наступному потоку в моніторі об'єкта, тобто, потоку поповнення не доведеться чекати (переходити в неробочий стан). Однак, якщо потік add data виконується першим, він буде переведений в неробочий стан через недостатній баланс і буде чекати завершення виконання потоку add money і виклику методу notify. Як думаєте, що станеться, якщо ви не викличете метод notify в останньому сценарії? Спробуйте розібратися самі 😉.

Крім того, ви помітили інший стиль створення екземпляра об'єкта Thread? Це відбувається тому, що в класі може бути тільки один метод run. Я хотів виконати два різних методи того ж класу, що і потоки, тому динамічно визначив різні методи запуску для обох потоків.
4. Метод "join"
Метод join використовується, коли ми хочемо зупинити виконання програми до тих пір, поки викликаний потік не завершить виконання. Чи можете ви уявити собі такий сценарій?
Розглянемо об'єкт Person, який ми приводили як приклад вище. Припустимо, Job і Address - це не просто строкові значення, а об'єкти. А якщо у них є свої власні таблиці бази даних і їх значення звідти потрібно витягти, щоб відобразити фрагменти інформації про людину Person? У нас може бути два потоки, які створюють зв'язки з кожною таблицею - роботи та адреси, витягують записи відповідно до конкретного Person, а потім відображають повні відомості про людину. Але тут потрібна обережність. Якщо ми витягуємо дані за допомогою потоків, а потім створюємо екземпляр об'єкта Person з цими значеннями, немає гарантії, що потоки витягнуть дані до моменту, коли виконається команда створення екземпляра об'єкта. Ось тут на сцені і з'являється join.
Погляньте на наведений нижче код:
package multithreadingPackage;
class Address implements Runnable {
private String address;
public String getAddress() {
return address;
}
public Address(){
}
@Override
public void run() {
this.address = "Dublin";
}
}
class Job implements Runnable {
private String job;
public String getJob() {
return job;
}
public Job() {
}
@Override
public void run() {
try {
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
this.job = "Software Developer";
}
}
class Person{
private String name;
@Override
public String toString() {
return "Person [name=" + name + ", job=" + job.getJob() + ", address=" + address.getAddress() + "]";
}
private Job job;
private Address address;
public Person(String name, Address address, Job job) {
this.name = name;
this.address = address;
this.job = job;
}
}
public class JoinImplementationDemo{
public static void main(String[] args) {
Address address = new Address();
Thread tAddress = new Thread(address);
Job job = new Job();
Thread tJob = new Thread(job);
tJob.start();
tAddress.start();
try {
tAddress.join();
tJob.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
Person person = new Person("Rajat", address, job);
System.out.println(person.toString());
}
}
Вивід без join:
Person [name=Rajat, job=null, address=Dublin]
Вивід з join:
Person [name=Rajat, job=Software Developer, address=Dublin]
Зверніть увагу на результати і порівняйте їх. Я додав метод sleep в потік Job, щоб збільшити час виконання і більш наочно продемонструвати результати. Без втручання join, виконання не чекає, коли потоки завершать виконання, і створює об'єкт Person. В результаті об'єкт містить значення null в атрибуті job. Тоді як, коли ми використовували метод join, все відпрацювало гладко.
Простіше кажучи, розпаралелювання завдань, що вимагають великої обчислювальної потужності, скорочує загальний час виконання, але треба бути обережним, щоб в процесі не втратити якусь інформацію. Метод join - один із кращих інструментів для цього.
Займаючись багатопотоковим програмуванням, я провів багато років у пошуках ідеального способу реалізації, і це було важко. Отже, я спробував пояснити вам багатопоточне програмування. Рекомендую пограти з кодом з цієї статті, щоб дослідити його глибше і зміцнити своє розуміння предмета.
Все, що вам потрібно, - практика👍.
Переклад статті: Rajat Gogna , "Thread Life Cycle - Java"

Ще немає коментарів