У статті оглянемо найпопулярніші функції бібліотек Lodash/Underscore.js та їх аналоги серед чистих JS-функцій ES5, ES6.
Поговоримо також про функціональне програмування, яке лежить в основі згаданих бібліотек.
Що таке функціональне програмування
Існує багато визначень та пояснень функціонального програмування, ми наведемо стисле:
Функціональне програмування — стиль програмування, за якого процес розрахунку трактується як обчислення значень виразів. Порівняйте з імперативним програмуванням, де програми складаються з виразів, які змінюють глобальний стан програми при виконанні. Функціональне програмування уникає використання змінюваного стану та віддає перевагу функціям без сторонніх ефектів з незмінюваними даними.
Ключовий момент тут — ваші функції не повинні мати сторонніх ефектів. Так їх легше тестувати, підтримувати та передбачати їх поведінку.
Почнемо з простих прикладів, щоб проілюструвати концепцію та поступово перейдемо до більш складних функцій.
1. find
Почнемо саме з цієї поширеної функції. Знайдемо перший елемент колекції, що задовольняє умову.
const users = [
{ 'user': 'joey', 'age': 32 },
{ 'user': 'ross', 'age': 41 },
{ 'user': 'chandler', 'age': 39 }
]
// Нативна функція
users.find(function (o) { return o.age < 40; })
// lodash
_.find(users, function (o) { return o.age < 40; })
Порівняємо продуктивність обох функцій.
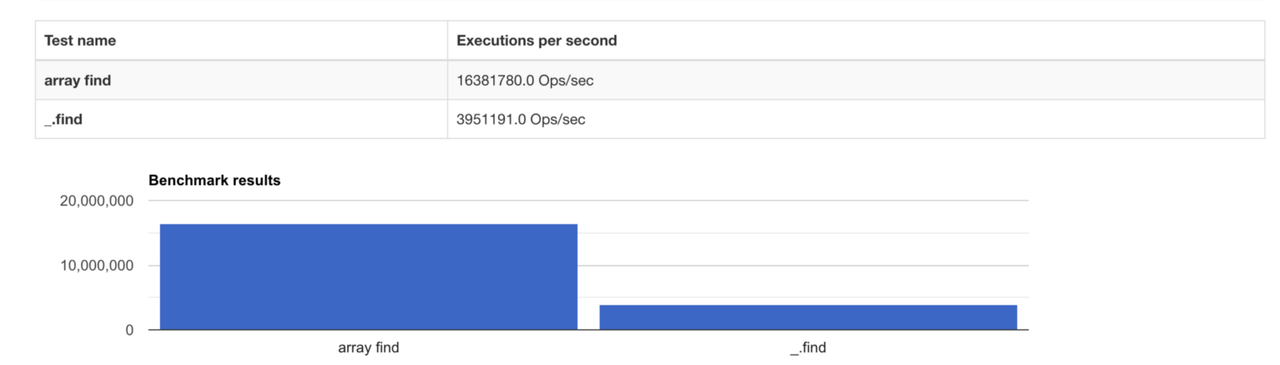
Ви можете оглянути код з тестовими і власними даними за посиланням.
Не варто думати, що нативні функції завжди продуктивніші за аналоги в Lodash. Є досить складні функції, які ми реалізуємо менш продуктивно, ніж у бібліотеці. Але якщо нативна функція проста та більш читабельна, варто розглядати її як гарну альтернативу.
2. filter
array.filter допомагає отримати усі елементи колекції, які задовольняють певну умову.
const numbers = [10, 40, 230, 15, 18, 51, 1221]
_.filter(numbers, num => num % 3 === 0)
numbers.filter(num => num % 3 === 0)
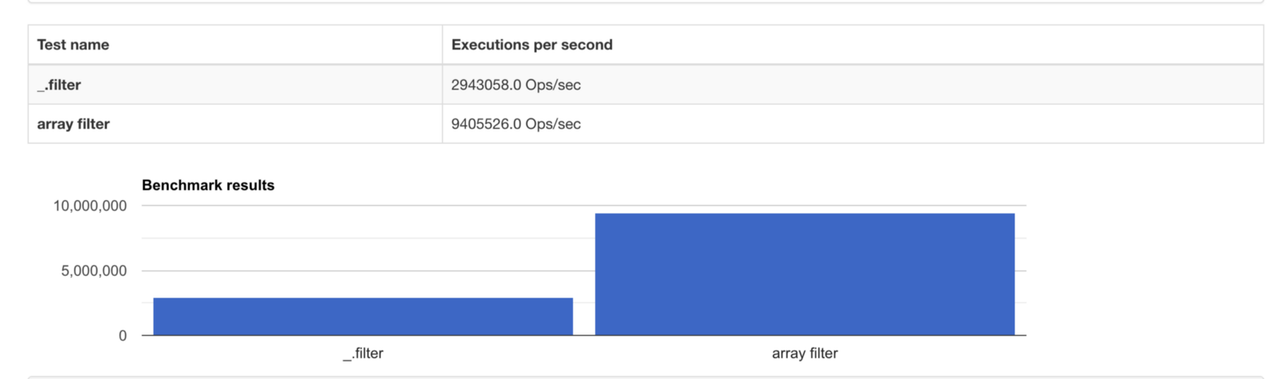
Порівняйте продуктивність методів.
3. first and rest
Існує безліч ситуацій, коли вам треба отримати перший елемент з колекції, а решту зберегти в масив.
const names = ["first", "middle", "last", "suffix"]
const firstName = _.first(names)
const otherNames = _.rest(names)
const [firstName, ...otherNames] = names
console.log(firstName) // 'first'
console.log(otherNames) // [ 'middle', 'last', 'suffix' ]
Імовірно, ви використовували spread-оператор (...) для інших випадків. Тут ми використовуємо його для деструктурування елементів масиву.
Порівняння продуктивності між first та rest залишаємо на читача.
4. each
Вам краще використовувати «ванільний» цикл for, ніж будь-які вбудовані ітератори. Це той самий випадок, коли функції lodash мають перевагу у продуктивності.
_.each([1, 2, 3], (value, index) => {
console.log(value)
})
[1, 2, 3].forEach((value, index) => {
console.log(value)
})
_.forEach({ 'a': 1, 'b': 2 }, (value, key) => {
console.log(key);
});
({ 'a': 1, 'b': 2 }).forEach((value, key) => { // !помилка
console.log(key);
});
Результати тесту виходять цікавими:
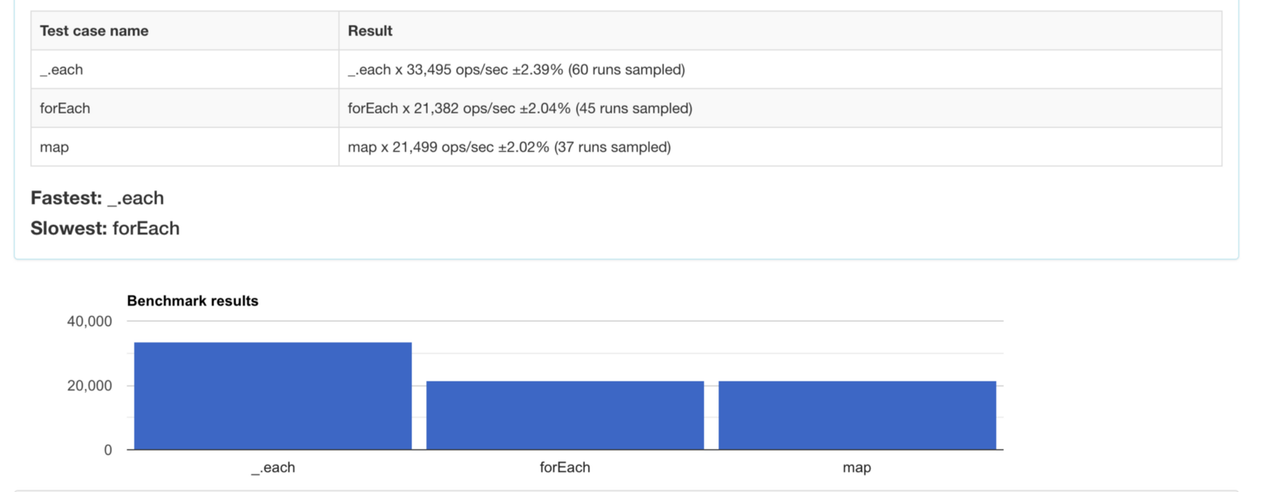
each від Lodash набагато швидший, адже його реалізація особлива для кожного браузеру.
Розробники Lodash пояснюють, що відносна швидкість нативного forEach відрізняється залежно від браузера. Хоч forEach нативний, це ще не означає, що він швидший за звичайний цикл for чи while. По-перше, forEach має справу з більш особливими випадками. По-друге, forEach використовує колбеки, а це потенційні додаткові витрати на виклик функцій.
5. every
Функція every перевіряє, чи всі елементи у масиві задовольняють певну умову. Тут нативна реалізація значно швидша.
const elements = ["cat", "dog", "bat"]
_.every(elements, el => el.length == 3)
elements.every(el => el.length == 3) //true
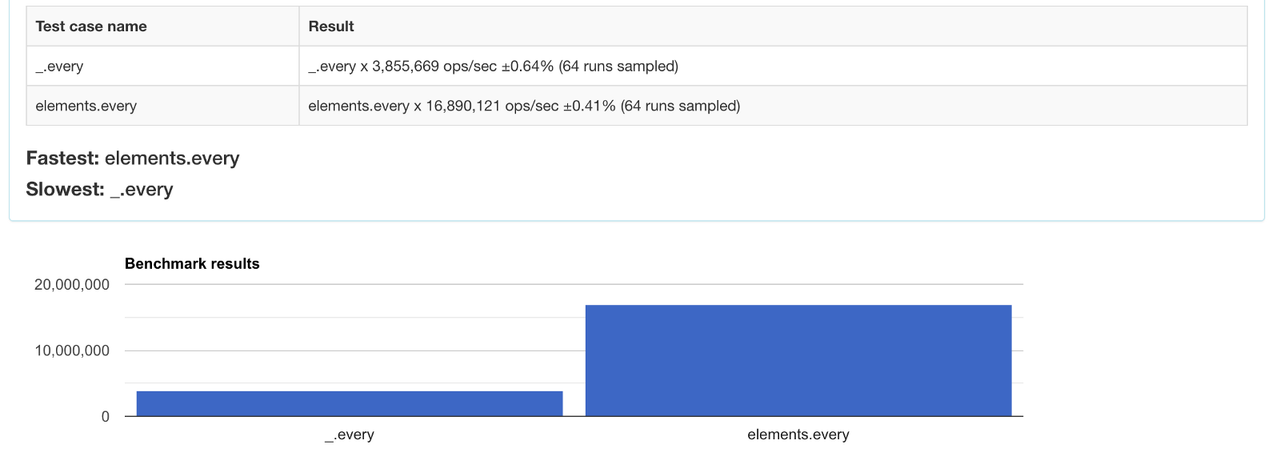
Порівняйте продуктивність методів тут.
6. some
Функція some перевіряє, щоб хоча б один елемент масиву задовольняв певну умову.
const elements = ["cat", "dog", "bat"]
_.some(elements, el => el.startsWith('c'))
elements.some(el => el.startsWith('c'))
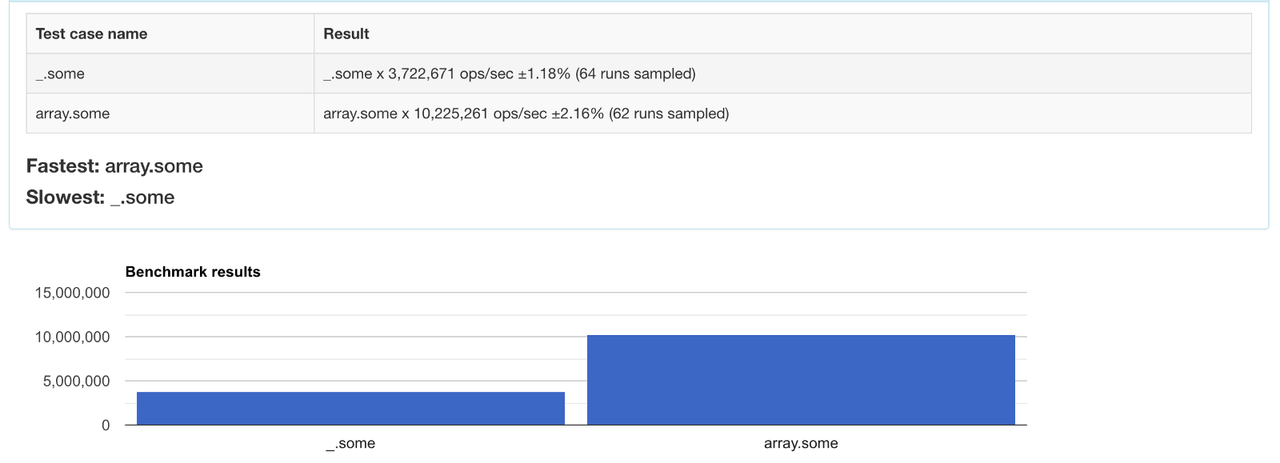
Порівняйте продуктивність методів.
7. includes
Метод перевіряє, чи є елемент у колекції.
const primes = [2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,97]
_.includes(primes, 47)
primes.includes(79)
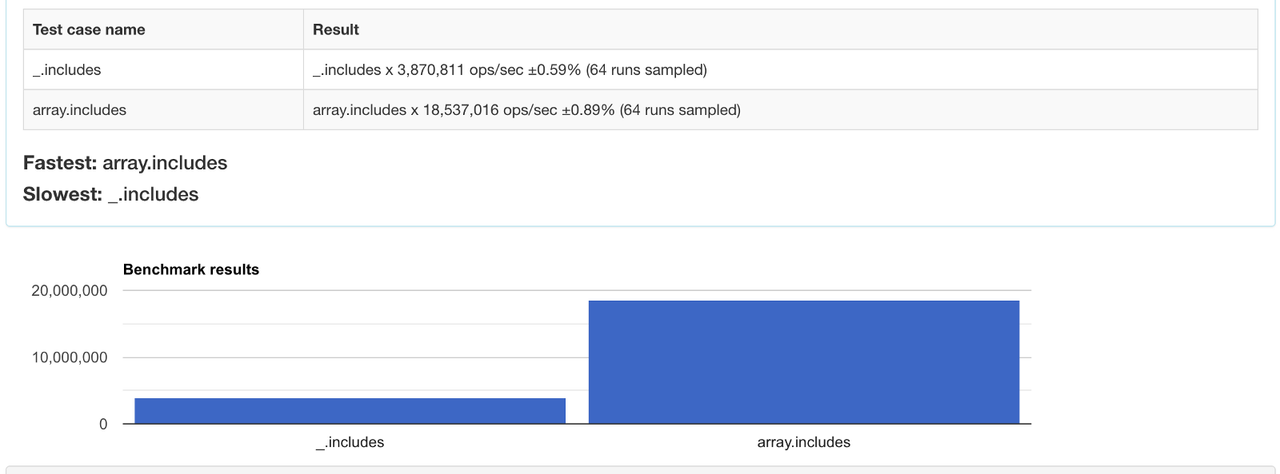
Порівняйте продуктивність методів тут.
8. uniq
Знаходить унікальні елементи масиву.
var elements = [1,2,3,1,2,4,2,3,5,3]
_.uniq(elements)
[...new Set(elements)]
Використаємо прийом зі структурою даних Set, а також spread-оператор для перетворення сету в масив. Тепер перевіримо, як впливатимуть на продуктивність такі маніпуляції.
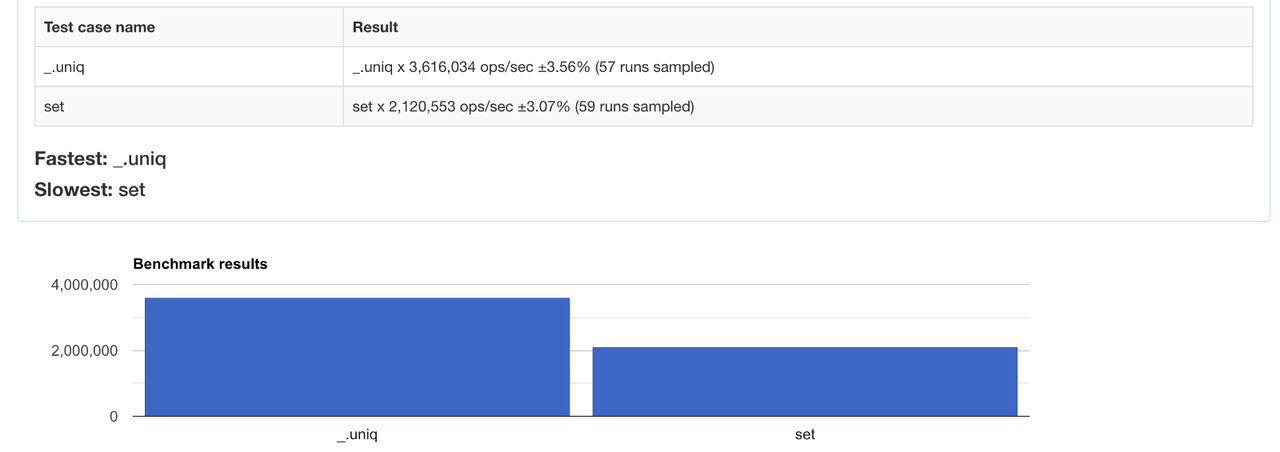
Порівняйте продуктивність методів.
Існує ще кращий спосіб відфільтрувати елементи:
elements.filter((v, i, a) => a.indexOf(v) === i) // definition: filter(callback(value, index, array)
Використовувати нативні функції або їх аналоги з Lodash — вирішувати вам.
9. compact
compact — корисна функція для видалення хибних значень або undefined з масиву.
var array = [undefined, 'cat', false, 434, '', 32.0]
_.compact(array)
array.filter(Boolean)
Тут помічаємо трохи синтаксичного цукру, адже треба перетворити кожен елемент у Boolean, використовуючи array.filter(Boolean), та повернути усі правдиві значення.
Висновок
Так на декількох прикладах ми визначили, на що треба звертати увагу при виборі нативної функції замість бібліотечної. Ось дві головні умови:
- Чи можете ви дозволити собі додати зовнішню бібліотеку в застосунок? Варто пам'ятати, що за допомогою таких технік як tree-shaking ви можете додавати лише використовувані модулі. Але чи будете ви готові використовувати зовнішню функцію?
- Чи готові ви пожертвувати читабельністю коду заради продуктивності?

Ще немає коментарів