
- Explore - одна з найбільших рекомендаційних систем в Instagram.
- Ми використовуємо машинне навчання, щоб переконатися, що люди завжди бачать найцікавіший та найактуальніший для них контент.
- Використовуючи досконаліші моделі машинного навчання, такі як нейронні мережі Two Towers, ми змогли зробити систему рекомендацій Explore ще масштабованішою та гнучкішою.
ШІ відіграє важливу роль у тому, що люди бачать на платформах Meta. Щодня сотні мільйонів людей відвідують Explore в Instagram, щоб відкрити для себе щось нове, що робить його однією з найпопулярніших рекомендаційних платформ в Instagram.
Щоб створити масштабну систему, здатну рекомендувати людям найбільш релевантний контент у режимі реального часу з мільярдів доступних варіантів, ми використали машинне навчання (ML), щоб впровадити специфічну для конкретних завдань доменну мову (DSL) та багатоступеневий підхід до ранжування.
Оскільки система продовжує розвиватися, ми розширили наш багатоступеневий підхід до ранжування кількома чітко визначеними етапами, кожен з яких фокусується на різних цілях і алгоритмах.
- Пошук
- Перший етап ранжування
- Другий етап ранжування
- Фінальне переранжування
Використовуючи кешування і попередні обчислення з висококонфігурованими методами моделювання, такими як нейронна мережа Two Towers (NN), ми створили систему ранжування для Explore, яка є ще гнучкішою і масштабованішою, ніж будь-коли раніше.
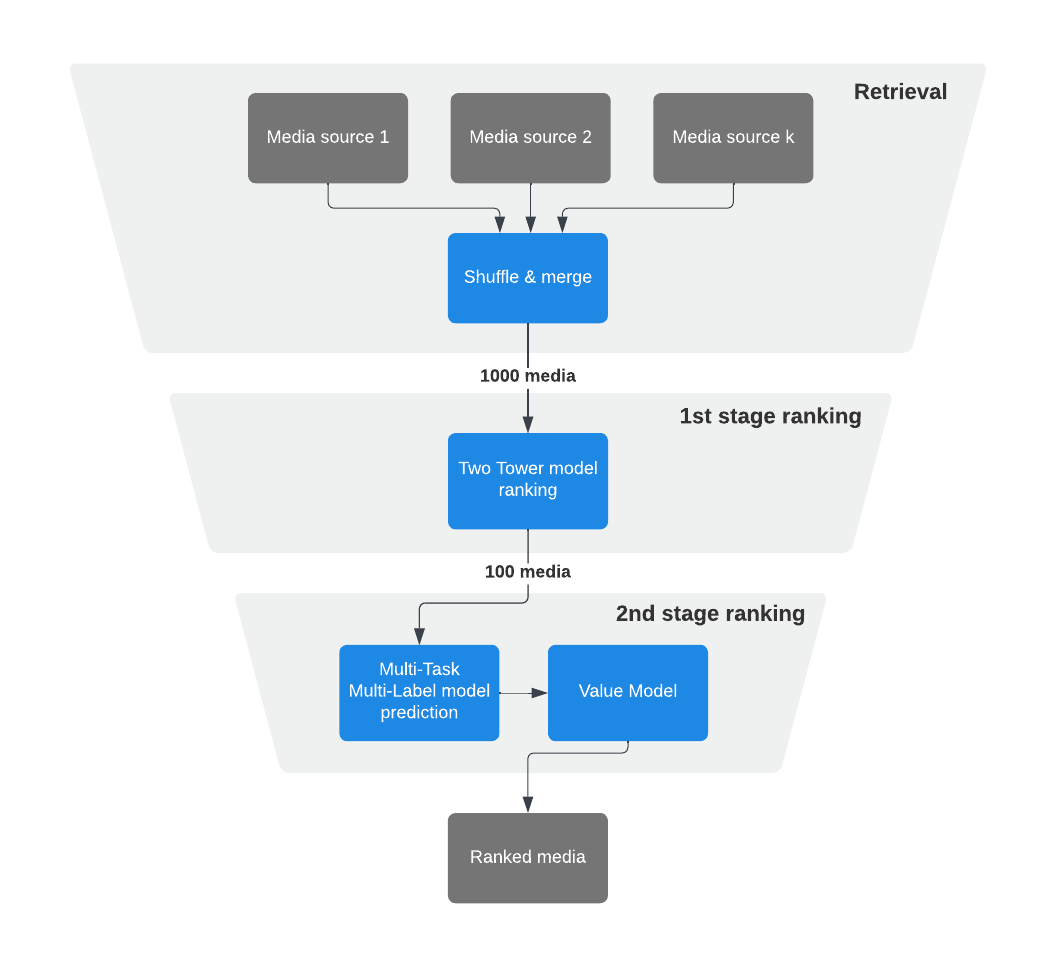
Читачі можуть помітити, що лейтмотивом цієї статті буде розумне використання кешування та попередніх обчислень на різних етапах ранжування. Це дозволяє нам використовувати важчі моделі на кожному етапі ранжування, вивчати поведінку на основі даних і менше покладатися на евристику.
Пошук
Основна ідея пошуку полягає в тому, щоб отримати приблизне уявлення про те, який контент (кандидати) отримає високий рейтинг на наступних етапах процесу, якщо весь контент буде взято із загального розподілу медіа.
У світі з безмежними обчислювальними потужностями та без вимог до затримок ми могли б ранжувати весь можливий контент. Але, враховуючи реальні вимоги та обмеження, більшість масштабних рекомендаційних систем використовують багатоступеневий підхід воронки - починаючи з тисяч кандидатів і звужуючи кількість кандидатів до сотень, коли ми спускаємося вниз по воронці.
У більшості великих рекомендаційних систем етап пошуку складається з декількох джерел пошуку кандидатів (скорочено "джерел"). Основне призначення джерела - відібрати сотні релевантних матеріалів з мільярдної медіа-бази. Отримавши кандидатів з різних джерел, ми об'єднуємо їх разом і передаємо моделям ранжування.
Джерела кандидатів можуть ґрунтуватися як на евристиці (наприклад, на трендових публікаціях), так і на складніших підходах ML. Крім того, джерела пошуку можуть бути в режимі реального часу (фіксуючи останні взаємодії) і попередньо згенеровані (фіксуючи довгострокові інтереси).
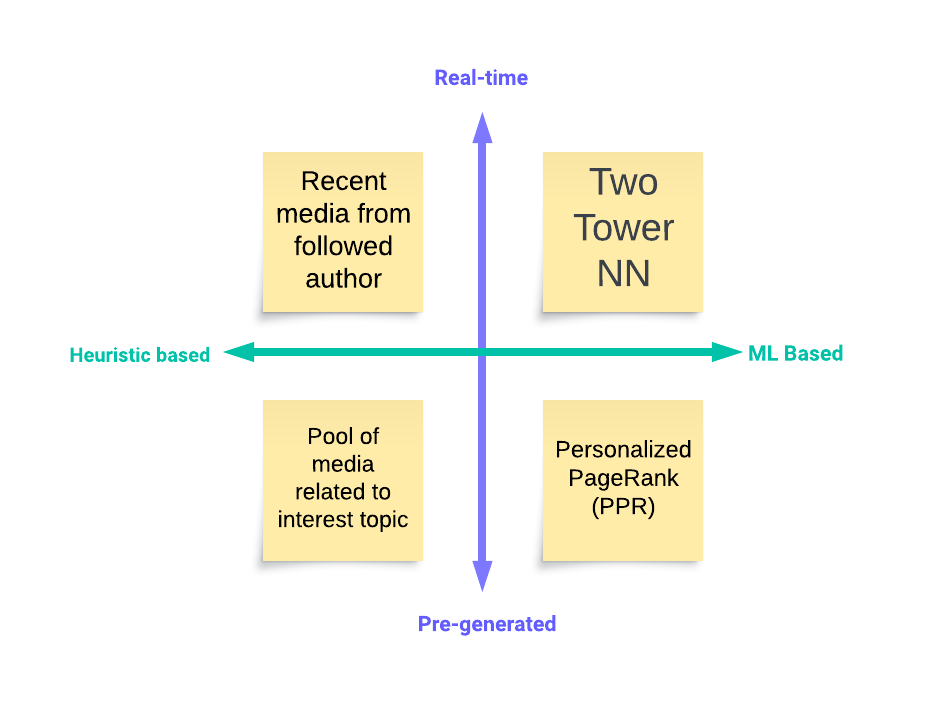
The four types of retrieval sources
Щоб змоделювати пошук медіа даних для різних груп користувачів з різними інтересами, ми використовуємо всі згадані типи джерел разом і змішуємо їх з вагами, які можна налаштовувати.
Кандидати з попередньо згенерованих джерел можна генерувати офлайн у непікові години (наприклад, локально популярні матеріали), що ще більше підвищує масштабованість системи.
Розглянемо докладніше кілька методів, які можна використовувати в пошуку.
Two Tower NN
Two Tower NN заслуговують на особливу увагу в контексті пошуку.
Наш підхід до пошуку на основі ML використовує алгоритм Word2Vec для генерації вбудовувань користувача та медіа/автора на основі їхніх ідентифікаторів.
Модель Two Towers розширює алгоритм Word2Vec, дозволяючи нам використовувати довільні характеристики користувача або медіа/автора і вчитися на основі декількох завдань одночасно для багатоцільового пошуку. Ця нова модель зберігає ремонтопридатність і роботу в режимі реального часу Word2Vec, що робить її чудовим вибором для алгоритму пошуку кандидатів.
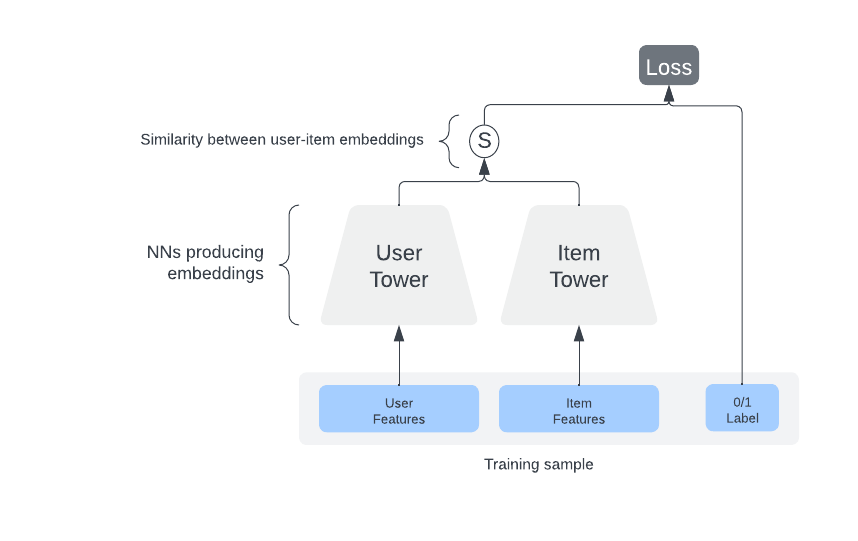
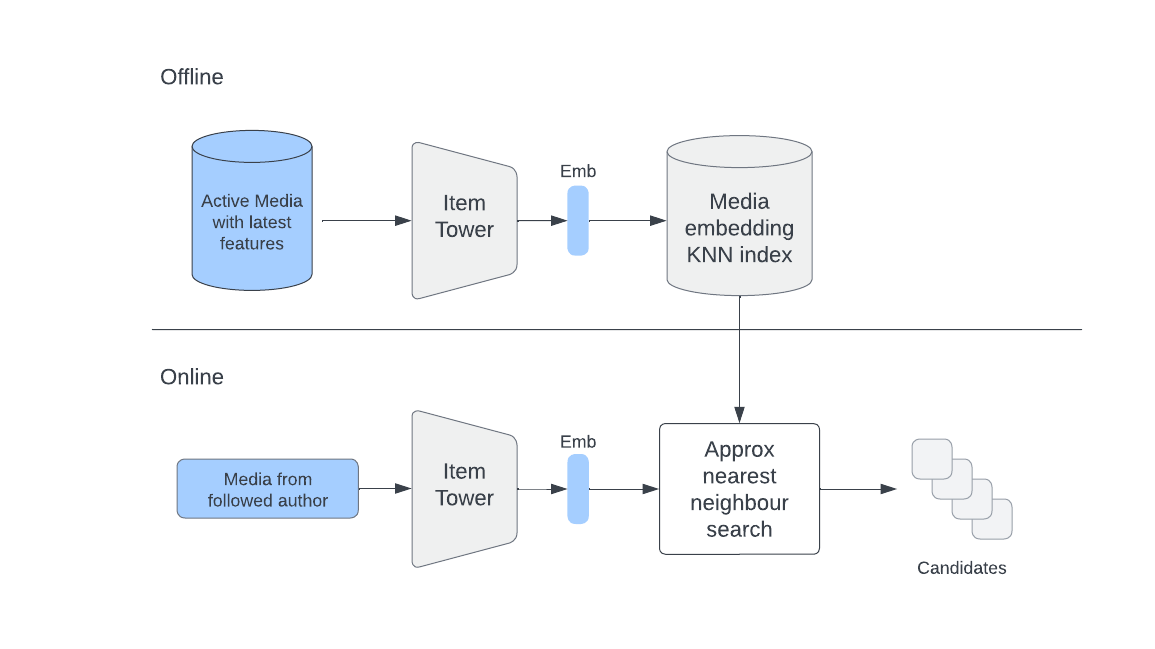
Ось як працює пошук Two Tower в загальних рисах зі схемою:
- Модель Two Tower складається з двох окремих нейронних мереж - одна для користувача та одна для документа.
- Кожна нейронна мережа завантажує лише ознаки, пов'язані з їхнім об'єктом, і видає вбудовування.
- Мета навчання полягає в тому, щоб передбачити взаємодію (наприклад, коли комусь подобається публікація) як міру схожості між вбудовуваннями користувача та об'єкта.
- Після навчання вбудовування користувачів повинні бути близькими до вбудовувань релевантних елементів для даного користувача. Таким чином, вбудовування елементів, близькі до вбудовування користувача, можуть бути використані як кандидати для ранжування.
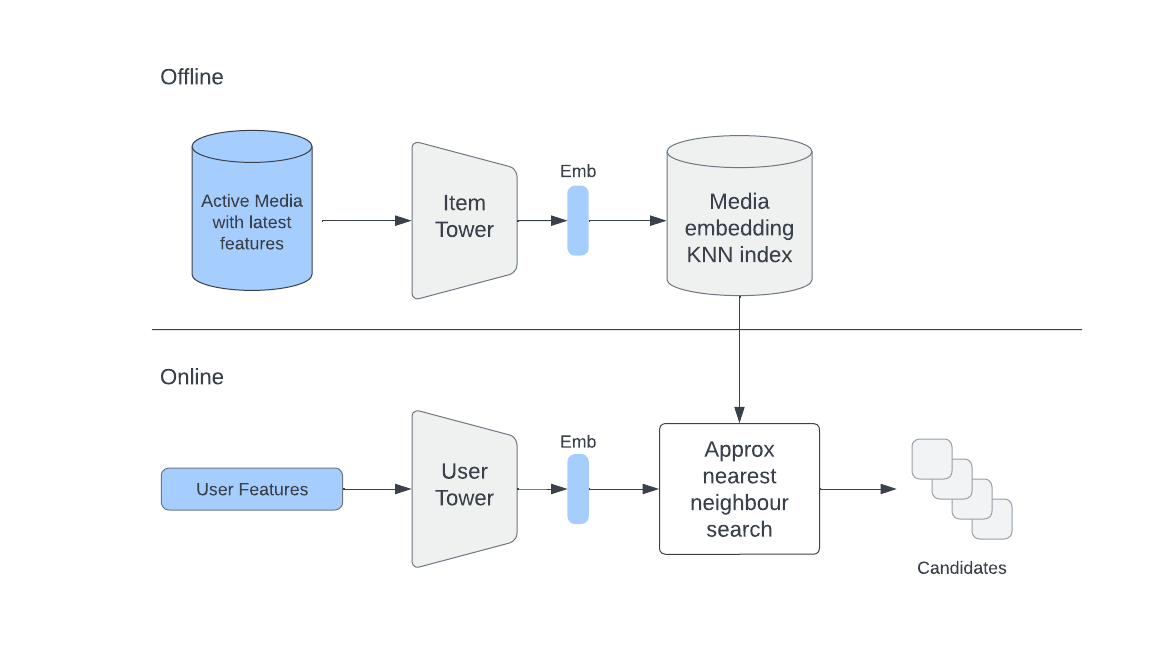
 Враховуючи, що мережі (вежі) елементів і користувачів є незалежними після навчання, ми можемо використовувати вежу елементів для генерації вбудовувань для елементів, які можуть бути використані як кандидати під час пошуку. І ми можемо робити це щоденно, використовуючи автономний конвеєр.
Враховуючи, що мережі (вежі) елементів і користувачів є незалежними після навчання, ми можемо використовувати вежу елементів для генерації вбудовувань для елементів, які можуть бути використані як кандидати під час пошуку. І ми можемо робити це щоденно, використовуючи автономний конвеєр.
Ми також можемо розмістити згенеровані вбудовування в сервіси, які підтримують онлайн-пошук приблизних найближчих сусідів (ANN) (наприклад, FAISS, HNSW тощо), щоб переконатися, що нам не доведеться сканувати весь набір об'єктів, щоб знайти схожі об'єкти для певного користувача.
Під час онлайн-пошуку ми використовуємо вежу користувача, щоб генерувати вбудовування користувача на льоту, отримуючи найсвіжіші користувацькі функції, та використовуємо їх для пошуку найбільш схожих елементів у сервісі ANN.
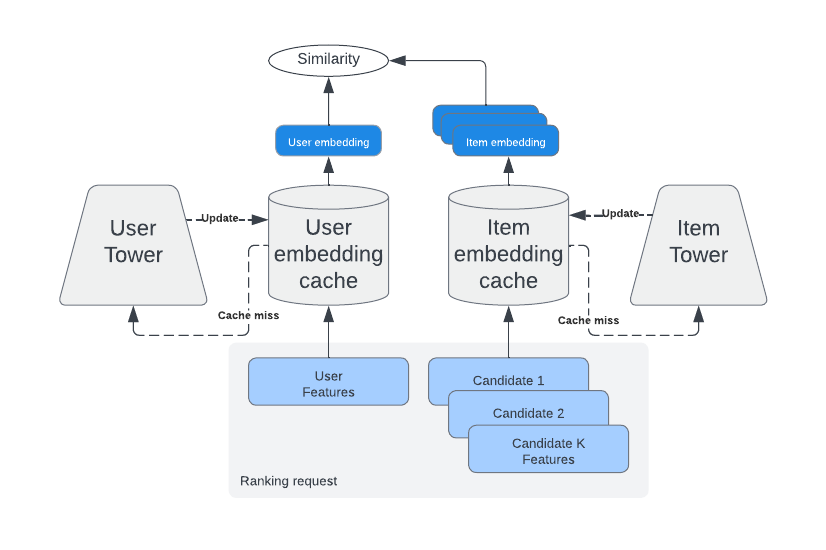
Важливо пам'ятати, що модель не може використовувати функції взаємодії користувача з елементом (які зазвичай є найпотужнішими), оскільки, використовуючи їх, вона втратить можливість надавати кешовані вбудовування користувача/елемента.
Основна перевага підходу "Дві вежі" полягає в тому, що вбудовування користувача та елемента можна кешувати, що робить результати виведення за моделлю "Дві вежі" надзвичайно ефективними.
Історія взаємодій користувача
Ми також можемо використовувати вбудовування елементів безпосередньо, щоб отримати подібні елементи з історії взаємодій користувача.
Припустимо, користувач вподобав/зберіг/поділився деякими елементами. Знаючи, що у нас є вбудовування цих елементів, ми можемо знайти список схожих елементів для кожного з них і об'єднати їх в один список.
Цей список міститиме елементи, що відображають попередні та поточні інтереси користувача.
Порівняно з пошуком кандидатів за допомогою користувацького вбудовування, безпосереднє використання історії взаємодій користувача дозволяє нам краще контролювати онлайн-компроміс між різними типами залучення.
Для того, щоб цей підхід давав високоякісних кандидатів, важливо вибрати хороші елементи з історії взаємодій користувача. (Тобто, якщо ми спробуємо знайти товари, схожі на випадково натиснутий товар, ми ризикуємо наповнити чиїсь рекомендації нерелевантним контентом).
Щоб вибрати хороших кандидатів, ми застосовуємо підхід, заснований на правилах, щоб відфільтрувати неякісні матеріали (наприклад, сексуальні/неприйнятні зображення, пости з великою кількістю "повідомлень" і т.д.) з історії взаємодій. Це дозволяє нам знаходити набагато кращих кандидатів для подальших етапів ранжування.
Ранжування
Після того, як кандидати знайдені, система повинна проранжувати їх за цінністю для користувача.
Ранжування у високонавантажених системах зазвичай поділяється на кілька етапів, які поступово зменшують кількість кандидатів з кількох тисяч до кількох сотень, які зрештою представляються користувачеві.
Оскільки в Explore неможливо ранжувати всіх кандидатів, використовуючи важкі моделі, ми використовуємо два етапи:
- Ранжування першого етапу (тобто, легка модель), яка є менш точною і менш інтенсивною в обчисленнях і може враховувати тисячі кандидатів.
- Ранжування другого етапу (тобто важка модель), яка є точнішою та обчислювально інтенсивнішою й оперує 100 найкращими кандидатами з першого етапу.
Використання двоетапного підходу дозволяє нам ранжувати більше кандидатів, зберігаючи при цьому високу якість фінальних рекомендацій.
Для обох етапів ми вирішили використовувати нейронні мережі, тому що в нашому випадку важливо мати можливість дуже швидко адаптуватися до мінливих тенденцій у поведінці користувачів. Нейронні мережі дозволяють нам робити це, використовуючи безперервне онлайн-навчання, тобто ми можемо перенавчати (доналаштовувати) наші моделі щогодини, як тільки отримуємо нові дані. Крім того, багато важливих функцій мають категоричний характер, а нейронні мережі забезпечують природний спосіб обробки категоричних даних шляхом навчання вбудовувань
Перший етап ранжування
На першому етапі ранжування наш старий знайомий двобаштовий NN знову вступає в гру завдяки своїй властивості кешування.
Хоча архітектура моделі може бути схожою на пошукову, мета навчання досить сильно відрізняється: Ми навчаємо ранжирувальник першого етапу передбачати вихід другого етапу з міткою:
PSelect = {медіа з перших K результатів, ранжованих другим етапом}.
Ми можемо розглядати цей підхід як спосіб дистиляції знань з більшої моделі другого етапу до меншої (легшої) моделі першого етапу.
Ранжування другого етапу
Після першого етапу ми застосовуємо другий етап ранжування, який прогнозує ймовірність різних подій залучення (клік, лайк тощо) за допомогою багатозадачної моделі нейронної мережі з декількома мітками (MTML).
Модель MTML набагато важча, ніж модель Two Towers. Але вона також може використовувати найпотужніші функції взаємодії користувача з елементами.
Застосування набагато важчої моделі MTML в години пік може бути проблематичним. Ось чому ми попередньо обчислюємо рекомендації для деяких користувачів у непікові години. Це допомагає забезпечити доступність наших рекомендацій для кожного користувача Explore.
Щоб отримати остаточну оцінку, яку ми можемо використовувати для впорядкування елементів рейтингу, прогнозні ймовірності P(натиснути), P(подобається), P(побачити менше) тощо можна об'єднати з вагами W_click, W_like і W_see_less за допомогою формули, яку ми називаємо моделлю значень (VM).
VM - це наше наближення цінності, яку кожне медіа приносить користувачеві.
Очікувана цінність = Wclick P(клік) + Wlike P(подобається) - Wseeless P(бачити менше) + тощо.
Налаштування ваг VM дозволяє нам досліджувати різні компроміси між метриками онлайн-залученості.
Наприклад, використовуючи більшу вагу W_like, фінальне ранжування приділятиме більше уваги ймовірності того, що користувач вподобав публікацію. Оскільки різні люди можуть мати різні інтереси щодо того, як вони взаємодіють з рекомендаціями, дуже важливо враховувати різні сигнали. Кінцева мета налаштування ваг полягає в тому, щоб знайти хороший компроміс, який максимізує наші цілі без шкоди для інших важливих показників.
Фінальне переранжування
Просто повертати результати, відсортовані за підсумковою оцінкою VM, не завжди є гарною ідеєю. Наприклад, ми можемо відфільтрувати/понизити рейтинг деяких матеріалів на основі оцінок, пов'язаних з доброчесністю (наприклад, видалити потенційно шкідливий контент).
Також, якщо ми хочемо збільшити різноманітність результатів, ми можемо перемішати матеріали на основі певних бізнес-правил (наприклад, "Не показувати матеріали від одних і тих же авторів у певній послідовності").
Застосування таких правил дозволяє нам набагато краще контролювати остаточні рекомендації, що сприяє кращому залученню користувачів в Інтернеті.
Налаштування параметрів
Як ви можете собі уявити, існують буквально сотні параметрів, які можна налаштовувати, щоб керувати поведінкою системи (наприклад, ваги ВМ, кількість статей для отримання з певного джерела, кількість статей для ранжування і т.д.).
Щоб досягти хороших результатів в Інтернеті, важливо визначити найважливіші параметри та зрозуміти, як їх налаштовувати.
Існує два популярних підходи до налаштування параметрів: Байєсівська оптимізація та офлайн-налаштування.
Байєсівська оптимізація
Байєсівська оптимізація (БО) дозволяє проводити налаштування параметрів в режимі онлайн.
Основна перевага цього підходу полягає в тому, що він вимагає від нас лише вказати набір параметрів для налаштування, мету оптимізації (тобто цільову метрику) та пороги регресії для деяких інших метрик, а решту ми залишаємо на розсуд БО.
Основний недолік полягає в тому, що процес оптимізації зазвичай вимагає багато часу для конвергенції (іноді більш ніж місяць), особливо коли ми маємо справу з великою кількістю параметрів і з низькочутливими онлайн метриками.
Ми можемо пришвидшити процес, дотримуючись наступного підходу.
Офлайн налаштування
Якщо у нас є доступ до достатньої кількості історичних даних у вигляді офлайн і онлайн метрик, ми можемо вивчити функції, які відображають зміни в офлайн метриках на зміни в онлайн метриках.
Після того, як ми вивчимо ці функції, ми можемо спробувати різні значення параметрів в офлайні та подивитися, як офлайнові метрики трансформуються в потенційні зміни в онлайн-метриках.
Щоб зробити цей офлайн-процес ефективнішим, ми можемо використовувати методи БО.
Основна перевага офлайн-налаштування порівняно з онлайн-налаштуванням полягає в тому, що воно вимагає набагато менше часу для проведення експерименту (години замість тижнів). Однак це вимагає сильної кореляції між офлайн і онлайн метриками.
Зростаюча складність ранжування для Explore
Робота, яку ми описали тут, далека від завершення. Зростаюча складність наших систем створить нові виклики з точки зору підтримки та зворотного зв'язку. Щоб розв'язувати ці проблеми, ми плануємо продовжувати вдосконалювати наші поточні моделі та впроваджувати нові моделі ранжування і джерела пошуку. Ми також досліджуємо, як об'єднати наші стратегії пошуку в меншу кількість алгоритмів машинного навчання, що легко налаштовуються.

Ще немає коментарів