Існує досить відомий скетч, в якому інженер пояснює керівнику проєкту, як працює надто складний лабіринт мікросервісів, щоб отримати повідомлення про день народження користувача - і все одно не може цього зробити. Ця сцена точно описує абсурдність стану сучасної технічної культури.
Ми сміємося, але згадувати про це в серйозній розмові рівнозначно професійній єресі, що ставить вас на межу безробіття.
Як ми дійшли до цього? Як наша мета стала не вирішенням поставленого завдання, а спалюванням купи грошей, розв'язуючи проблеми, яких у нас немає?
Ідеальний шторм
У новітній політиці є кілька моментів, які, можливо, вплинули на нинішній стан речей. По-перше, ціла армія розробників, які писали Javascript для браузерів, почала самоідентифікуватися як "full-stack", занурюючись у розробку серверів та асинхронний код. Але ж Javascript є Javascript, чи не так? Яка різниця, що ви створюєте з його допомогою - користувацькі інтерфейси, сервери, ігри чи вбудовані системи. Чи не так? Node все ще був навчальним проєктом однієї людини, і Javascript тоді був дуже сумнівним вибором для розробки серверів. Вказування на це все ще "зеленим" серверним розробникам зазвичай призводило до того, що вони починали бурчати та сопіти. Зрештою, це все, що вони знали. Світ за межами Node фактично не існував, шлях Node був єдиним відомим шляхом, і це стало причиною зародження впертого, догматичного мислення, з яким ми маємо справу донині.

А потім, постійний потік ветеранів FAANG почав вливатися в річку стартапів, наставляючи новоспечених і дуже вразливих молодих серверних Javascript інженерів. Апостоли церкви складності наполегливо стверджували, що "те, як це робиться в Google", є беззаперечним і правильним - навіть якщо це не має сенсу в нинішньому контексті та розмірі компанії. Що ви маєте на увазі, коли кажете, що у вас немає окремого сервісу налаштувань користувача? Чувак, це не буде масштабуватися!
Але в усьому цьому легко звинуватити ветеранів і новачків. Але що ще відбувалося? Ах, так - легкі гроші.
Що ви робите, коли у вас закінчується венчурний капітал? Звісно ж, не гонитесь за прибутком! Неодноразово я отримував електронного листа від керівництва з проханням бути в офісі, прибрати на своїх столах і виглядати зайнятими, оскільки хмара жилетів Patagonia ось-ось пройде через офіс. Інвесторам потрібно було побачити вибухове зростання, але не в прибутковості, ні. Вони просто хотіли побачити, як швидко компанія може найняти наддорогих інженерів-програмістів, щоб зробити... щось.
І тепер, коли у вас є ці розробники, що ви з ними робите? Ну, вони можуть створити простішу систему, яку легше розвивати та підтримувати, а можуть створити жахливе сузір'я "мікросервісів", яке ніхто не розуміє. Мікросервіси - новий спосіб написання масштабованого програмного забезпечення! Невже ми просто будемо вдавати, що поняття "розподілені системи" ніколи не існувало? (Опустимо розбір нюансів про те, що мікросервіси не є справжніми розподіленими системами).
У ті часи, коли технологічна індустрія не була таким роздутим фарсом, розподілені системи поважали, боялися і взагалі уникали - їх використовували лише як зброю останньої інстанції для вирішення особливо складних проблем. Все, що пов'язано з розподіленою системою, стає складнішим і трудомісткішим - розробка, налагодження, розгортання, тестування, відмовостійкість. Але я не знаю - можливо, зараз це все дуже просто, тому що занадто складно.
Не існує стандартного інструментарію для розробки на основі мікросервісів - немає єдиного фреймворку. Працювати над розподіленими системами стало лише трохи легше у 2020-х роках. Докери та Кубернети не змогли чарівним чином усунути складність, притаманну розподіленим системам.
Я люблю посилатися на цей підсумок 5-річного аудиту стартапів, оскільки він наповнений висновками, що базуються на здоровому глузді та переконливих доказах (і платних інсайтах):
... стартапи, які ми перевіряли і які зараз досягли найкращих результатів, зазвичай мали майже нахабний підхід до інженерії за принципом "не ускладнюй". Хитрощі заради хитрощів викликали огиду. З іншого боку, компанії, про які ми говорили: "Вау, ці люди до біса розумні", здебільшого зникали.
Буквально - "складність вбиває".
Аудит виявив цікаву закономірність: багато стартапів відчували своєрідний синдром колективного самозванця, будуючи прості, зрозумілі та ефективні системи. Існує догма, що не можна починати з мікросервісів у перший день - незалежно від проблеми. "Всі роблять мікросервіси, але у нас є єдиний моноліт Django, який підтримується лише кількома інженерами, і екземпляр MySQL - що ми робимо не так?". Відповідь майже завжди "нічого".
Так само і досвідчені інженери часто відчувають вагання та неадекватність у сучасному світі технологій, і хороша новина полягає в тому, що ні - це, швидше за все, не про вас. Команди часто вдають, що вони займаються "веб-розробкою", ховаючись за бібліотеками, ORM та кешем - впевнені у своїй експертизі (вони розгромили цей Leetcode!), але при цьому можуть навіть не знати основ індексування баз даних. Ви працюєте в морі невиправданої самовпевненості, марнотратства і Даннінга-Крюгера, тож хто тут насправді самозванець?
У моноліті немає нічого поганого
Ідея про те, що ви не можете розвиватися без системи, схожої на сумнозвісну схему військової стратегії Афганістану, значною мірою є міфом.
Dropbox, Twitter, Facebook, Instagram, Shopify, Stack Overflow - ці та інші компанії починали як монолітні кодові бази. Багато з них мають монолітну основу і донині. Stack Overflow пишається тим, як мало обладнання їм потрібно для запуску величезного сайту. Shopify все ще залишається монолітом Rails, використовуючи перевірений часом Resque для обробки мільярдів завдань.
WhatsApp став надновою зі своїм монолітом Erlang та 50 інженерами. Як це сталося?
WhatsApp свідомо тримає штат інженерів невеликим - лише близько 50 інженерів.Окремі інженерні команди також невеликі, складаються з 1 - 3 інженерів, і кожна з них має значну автономію.
Що стосується серверів, WhatsApp вважає за краще використовувати меншу кількість серверів і вертикально масштабувати кожен сервер до максимально можливого рівня.
Instagram був придбаний за мільярди - з командою з 12 осіб.
А ви уявляєте Threads як роботу цілого кампусу Meta? Ні. Вони пішли за моделлю Instagram, і це вся команда Threads:

Можливо, стверджувати, що ваша конкретна проблемна область вимагає надзвичайно складної розподіленої системи та відкритого офісу, вщерть набитого турбо-геніями, - це просто зарозумілість, а не геніальність?
Не намагайтеся розв'язувати проблеми, яких у вас немає
Це просте запитання - яку проблему ви вирішуєте? Масштабування? Звідки ви знаєте, як все це розбити для масштабування та продуктивності? Чи є у вас достатньо даних, щоб показати, що має бути окремим сервісом і чому? Розподілені системи будуються з урахуванням розміру та відмовостійкості. Чи може ваша система масштабуватися і бути відмовостійкою одночасно? Що станеться, якщо один із сервісів вийде з ладу або почне повільно працювати? Просто масштабувати його? А як щодо інших сервісів, на які вплине трафік? Чи змоделювали ви нескінченні сценарії того, що може і що піде не так? Чи є протидія потокам даних? Захисні вимикачі? Черги? Джиттер? Розумні тайм-аути на кожній кінцевій точці? Чи є захист від дурня, щоб переконатися, що проста зміна не зруйнує все? Регулятори, про які вам потрібно знати і які потрібно налаштувати, нескінченні, і всі вони залежать від особливостей використання та навантаження вашої системи.
Правда полягає в тому, що більшість компаній ніколи не досягнуть таких масштабів, які вимагатимуть побудови справжньої системи дистрибуції. Намагання наслідувати Amazon та Google - без їхнього масштабу, досвіду та нескінченних ресурсів - скоріш за все, буде просто кричущою тратою грошей та часу. Релігійне виконання всіх кроків зі статті "Десять ранкових звичок дуже успішних людей" не зробить вас мільярдером.
Єдине, що складніше за розподілену систему - це ПОГАНА розподілена система.
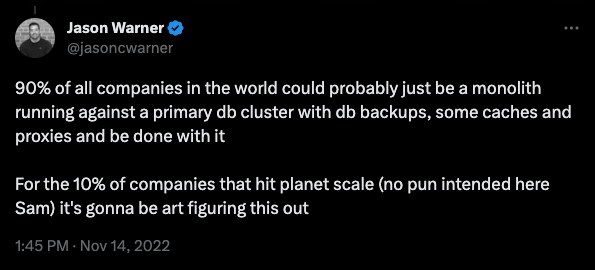
"Але окрема команда... але окремий... але API"
Спроба впровадити розподілену топологію в структуру вашої компанії - це благородне зусилля, але воно майже завжди призводить до зворотного результату. Це звичайний підхід - розбити проблему на менші частини, а потім вирішувати їх одну за одною. Існує думка, що якщо розбити одну послугу на кілька, то все стане простіше.
В теорії все просто та елегантно - кожен мікросервіс ретельно підтримується спеціальною командою, відгородженою гарним, сумісним з попередніми версіями API з багатьма версіями. Насправді, це настільки надійно, що вам навіть рідко доводиться спілкуватися з цією командою - так, ніби мікросервіс підтримується стороннім постачальником. Це дуже просто!
Якщо це не звучить знайомо, це тому, що таке рідко трапляється. В реальності, наші канали Slack переповнені повідомленнями від команд, які спілкуються про релізи, помилки, оновлення конфігурації, зміни, що порушують безпеку, та PSA. Кожен повинен бути в курсі всього і завжди. І якщо це не дуже добре, то це нормально, коли одна вже виснажена команда працює над кількома мікросервісами, замість того, щоб робити хорошу роботу над одним, часто змінюючи команду, оскільки люди приходять і йдуть.
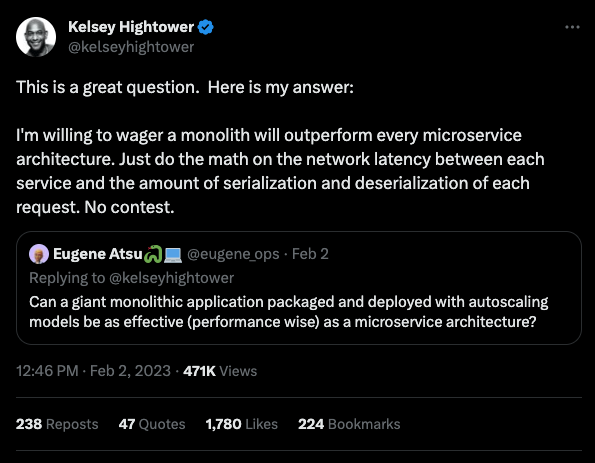
Щоб виграти перегони, ми не будуємо один хороший болід - ми будуємо парк гівняних гольф-карів.
Що ви втрачаєте
У побудові з використанням мікросервісів є багато пасток, і часто це мінне поле або не усвідомлюють, або просто ігнорують. Команди витрачають місяці на написання вузькоспеціалізованого інструментарію та вивчення уроків, які зовсім не пов'язані з основним продуктом. Ось лише деякі аспекти, які часто залишаються поза увагою...
- Маєте спільну бібліотеку?
- Як оновлюється спільна бібліотека? Всюди зберігати різні версії?
- Регулярно примусово оновлювати, створюючи десятки pull-запитів у всіх сховищах?
- Зберігати все це в монорепозиторії? Це призводить до певних проблем.
- Допускати дублювання коду?
- Забудьте про це, кожній команді доведеться щоразу винаходити велосипед.
Кожна компанія, що йде цим шляхом, стикається з цим вибором, і немає хороших "ергономічних" варіантів - ви повинні вибрати свою версію болю.
Попрощайтеся з DRY
Після десятиліть навчання розробників писати код за принципом Don't Repeat Yourself, здається, ми просто забули про нього. Мікросервіси за замовчуванням не є DRY, кожен сервіс наповнений надлишковими шаблонами. Дуже часто накладні витрати на таку "сантехніку" настільки великі, а розмір мікросервісів настільки малий, що в середньому екземплярі сервісу більше "сервісу", ніж "продукту". То як же бути зі спільним кодом, який можна винести за дужки?
Ергономіка розробника впаде в прірву
"Ергономіка розробника" - це тертя, кількість зусиль, через які повинен пройти розробник, щоб щось зробити, будь то робота над новою функцією або виправлення помилки.
У мікросервісах інженер повинен мати ментальну карту всієї системи, щоб знати, які сервіси підняти для того чи іншого завдання, з якими командами поговорити, з ким поговорити й про що поговорити. Принцип "ти повинен знати все, перш ніж щось робити". Як вам вдається тримати руку на пульсі? Spotify, багатомільярдна компанія, витратила, мабуть, чималі внутрішні ресурси на створення Backstage, програмного забезпечення для каталогізації своїх нескінченних систем і сервісів.
Це повинно принаймні дати вам зрозуміти, що ця гра не для всіх, і ціна за участь у ній висока. А як щодо інструментів? Не Spotify залишаються зі своїми власними рішеннями, про надійність та портативність яких ви, напевно, здогадуєтесь.
А скільки команд насправді спрощують процес запуску - "ще одного дурного сервісу"? У тому числі:
- Привілеї розробника в GitHub/GitLab
- Змінні оточення за замовчуванням та конфігурація
- CI/CD
- Перевірка якості коду
- Налаштування перегляду коду
- Правила та захист гілок
- Моніторинг та спостереження
- Інструменти для тестування
- Інфраструктура як код
І, звичайно, помножте цей список на кількість мов програмування, які використовуються в компанії. Можливо, у вас є зручний шаблон або посібник? А може, безпроблемна система запуску нового сервісу з нуля в один клік? На те, щоб виправити всі недоліки такої автоматизації, підуть місяці. Отже, ви можете або працювати над своїм продуктом, або над тим, як його автоматизувати.
Інтеграційні тести - LOL
Наче повсякденної роботи з мікросервісами було недостатньо, ви також втрачаєте душевний спокій, який дарують надійні інтеграційні тести. Ви проходите односервісні та модульні тести, але чи залишаються ваші критичні шляхи недоторканими після кожного коміту? Хто відповідає за загальний набір інтеграційних тестів, в Postman чи деінде? Чи є така особа?

Інтеграційне тестування розподіленої системи є майже нездійсненною проблемою, тому ми практично відмовилися від неї та замінили її на іншу - спостережуваність (Observability). Так само як "мікросервіси" - це нові "розподілені системи", "спостережуваність" - це нове "налагодження у виробництві". Безумовно, ви не пишете справжнє програмне забезпечення, якщо ви не робите.... спостережуваність!
Спостережуваність стала окремою галуззю, і ви заплатите за неї як грошима, так і часом розробника. Це також не приходить як plug-and-pay - вам потрібно розуміти та впроваджувати канаркові релізи, прапорці можливостей і т.д. Хто цим займається? Один і без того перевантажений інженер?
Як бачите, розбиття проблеми на частини не полегшує її вирішення - все, що ви отримуєте, це ще один набір ще складніших проблем.
А як щодо просто "сервісів"?
Чому ваші послуги мають бути "мікро"? Що не так з простими сервісами? Деякі стартапи зайшли так далеко, що створили сервіс для кожної функції, і так, "хіба це не те саме, що Lambda?" - це слушне запитання. Це дає вам уявлення про те, наскільки далеко зайшов цей неконтрольований культ карго.
Так що ж нам робити? Почати з моноліту - це один з очевидних варіантів. Модель, яка також може спрацювати в багатьох випадках, - це "стовбур і гілки", де головному моноліту "м'яса і картоплі" допомагають "гілки" послуг. Відгалуженням може бути служба, яка піклується про чітко ідентифіковане та окремо масштабоване навантаження. Вимогливий до процесора сервіс зміни розміру зображень має набагато більше сенсу, ніж сервіс реєстрації користувачів. Або ви отримуєте так багато реєстрацій в секунду, що це вимагає незалежного горизонтального масштабування?

Примітка: У контролі версій, ще за часів CVS і Subversion, ми рідко використовували "master" гілки. У нас був "trunk і branches", тому що, знаєте - дерева. "Master" гілки з'явилися десь по дорозі, і коли GitHub вирішив покінчити з досить невдалою конвенцією іменування, середньостатистичний інженер був занадто молодий, щоб пам'ятати про "trunk" - і так з'явилася загальна "main" за замовчуванням.

Маятник повертається назад
Ажіотаж, однак, здається, вщухає. Кран для венчурних інвестицій закручується, і тому бізнес змушений приймати рішення на основі здорового глузду, визнаючи, що, можливо, витрачатися на архітектуру веб-масштабування, коли у них немає проблем з веб-масштабуванням, не є раціональним рішенням.
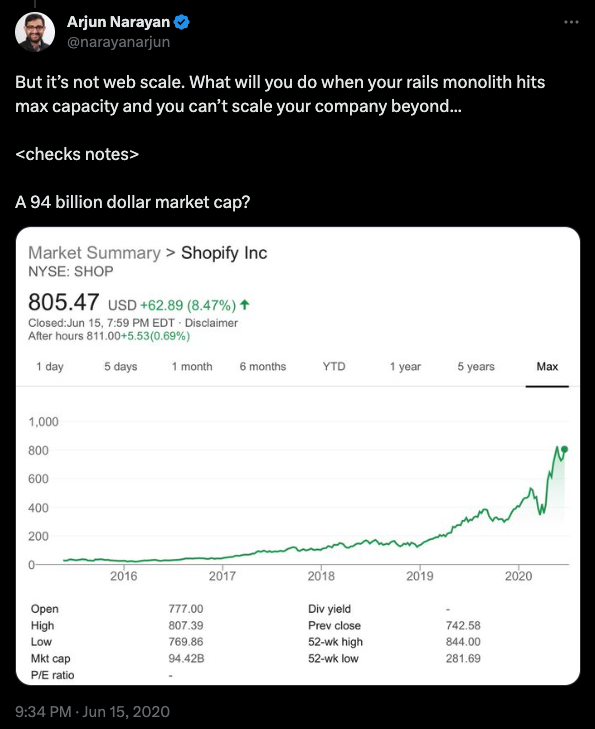
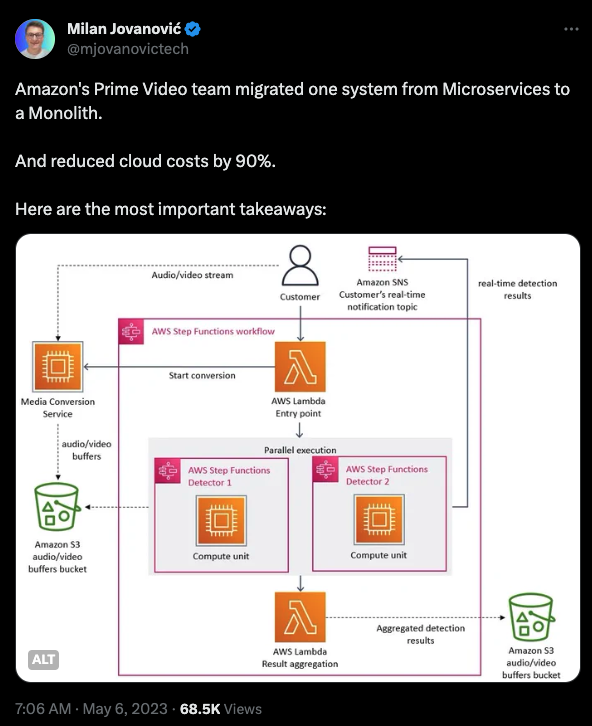
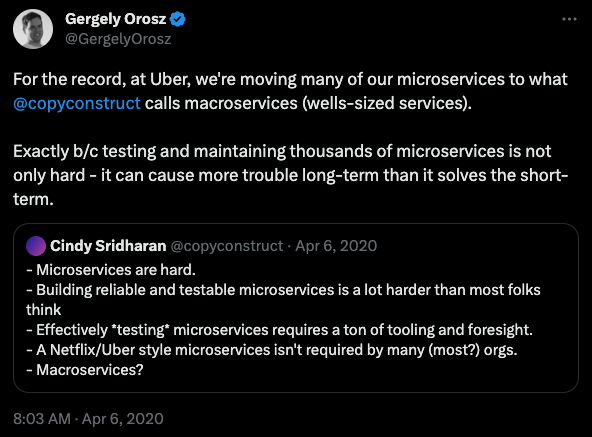
Зрештою, коли вам потрібно дістатися з Нью-Йорка до Філадельфії, у вас є два варіанти. Ви можете спробувати побудувати дуже складний космічний корабель для орбітального спуску до місця призначення, або ви можете просто купити квиток на потяг Amtrak для 90-хвилинної подорожі. Це і є проблема, про яку ми говоримо.

Ще немає коментарів