Керівництво розраховане на розробників, які добре знайомі із JavaScript, але ще не дуже добре володіють Node.js. У статті не буде детально розглянуто питання синтаксису: Node.js використовує V8 — той же інтерпретатор, що і Google Chrome (втім, можна запускати скрипти на віртуальних машинах, ознайомтеся з node-chakracore).
Node.js популярний навіть серед фронтенд розробників. Npm скрипти, конфігурація webpack, gulp задачі, програмний запуск пакетів, автоматичні тести — задачі, в яких Node.js незмінний помічник. Навіть якщо ви не маєте справи із серверною частиною, знання ключових концепцій Node.js все рівно будуть корисними, тому що допоможуть автоматизувати те, що ви робите вручну. Цей посібник дозволить вам почуватися впевненіше із серверною частиною та писати більш складні скрипти.
Версії Node
Фронтенд розробника найбільше вразить можливість обирати середовище виконання і бути абсолютно впевненим щодо підтримуваних функцій. Ви самостійно зазначаєте яку версію фреймворку використовувати, в залежності від потреб та доступних серверів.
Node.js надає публічний графік оновлень, який демонструє, що LTS-версія (з довгостроковою підтримкою) буде випущена до квітня 2019, а важливими оновленнями буде підтримуватись до 31 грудня 2019. Нові версії Node активно вдосконалюються: вноситься багато нових функцій, поліпшується безпека та продуктивність. Тож існує безліч переваг у використанні останньої активної версії фреймворку. Однак, якщо вам комфортніше працювати зі старішою версією, і це не шкодить роботі, — можете сміливо її застосовувати.
Node.js широко використовується у сучасних фронтенд пакетах програм. Сьогодні складно уявити проект, в якому немає обробки коду із використанням інструментів node, тому ви, можливо, вже знайомі з nvm (node version manager), який дозволяє встановлювати одразу декілька версій node. З його допомогою можна використовувати для кожного проекту різні версії Node, не виконуючи синхронізації, а лише зберігати середовище, в якому проект було створено і протестовано. Подібні інструменти існують і в багатьох інших мовах програмування: virtualenv для Python, rbenv для Ruby тощо.
Babel не потрібен
Скоріш за все ви використовуєте саме LTS (довгостроково підтримувану) версію Node, яка, на момент написання статті, підтримує майже всі специфікації ECMAScript 2015, окрім хвостової рекурсії.
У вас немає потреби в Babel, якщо, звичайно, ви не використовуєте дуже стару версію Node.js, де не обійтися без перетворення JSX. На практиці, можна запускати код одразу після написання, не виконуючи транспіляцію, і це перевага, якої немає на стороні клієнта.
Вам не потрібні webpack або browserify, тому якщо ви створюєте щось на зразок веб-сервера, можете використовувати nodemon для оновлення вашого застосунку після змін у файлах.
Ще одна важлива перевага: нема потреби мінімізувати код, тому що ми не відправляємо його нікуди після написання.
Особливості застосування callback-функцій
Асинхронні функції у Node.js приймають колбеки з параметрами (err, data), де перший аргумент сповіщає про наявність помилки (або null, якщо все добре). Обробники викликаються після повернення результату. Наприклад, прочитаємо файл:
const fs = require('fs');
fs.readFile('myFile.js', (err, file) => {
if (err) {
console.error('Помилка читання файлу :(');
// процес — глобальний об'єкт у Node
// https://nodejs.org/api/process.html#process_process_exit_code
process.exit(1);
}
// опрацювання вмісту файлу
});
Пізніше з'ясувалося, що такий стиль написання коду значно ускладнює процес налагодження та читабельність коду, тому існує навіть поняття «callback hell». Було винайдено більш зручний механізм для організації асинхронного коду — Promise, що був стандартизований в ECMAScript 2015. Він являє собою спеціальний об'єкт, що містить свій стан і є глобальним як для браузера, так і для Node.js. Нещодавно async/await були стандартизовані в ECMAScript 2017, і стали доступними у Node.js 7.6+ і LTS версії.
З promises ми уникаємо «колбек пекла», але старий код та багато вбудованих модулів досі підтримують цю техніку. Однак, перетворити fs.readFile у promises не дуже складно.
const fs = require('fs');
function readFile(...arguments) {
return new Promise((resolve, reject) => {
fs.readFile(...arguments, (err, data) => {
if (err) {
reject(err);
} else {
resolve(data);
}
});
});
}
Наведений шаблон можна з легкістю розширити для будь-якої функції: існує спеціальний метод у вбудованому модулі utils — utils.promisify.
Розглянемо приклад з офіційної документації:
const util = require('util');
const fs = require('fs');
const stat = util.promisify(fs.stat);
stat('.').then((stats) => {
// Дії зі `stats`
}).catch((error) => {
// Обробити помилку
});
Розробники Node.js розуміють необхідність відходу від старого стилю, тому намагаються представити версію вбудованих модулів на промісах. На момент написання статті існує вже експериментальний модуль.
Все ще можна зустріти багато «старомодного» коду Node.js з колбеками, тому рекомендовано змінювати його, застосовуючи utils.promisify заради однорідності коду.
Цикл подій
В цілому, цикл подій у Node.js такий самий, як і у браузері, за винятком деяких відмінностей, на яких я буду наголошувати, щоб ви знали, яка частина стосується винятково Node.js.
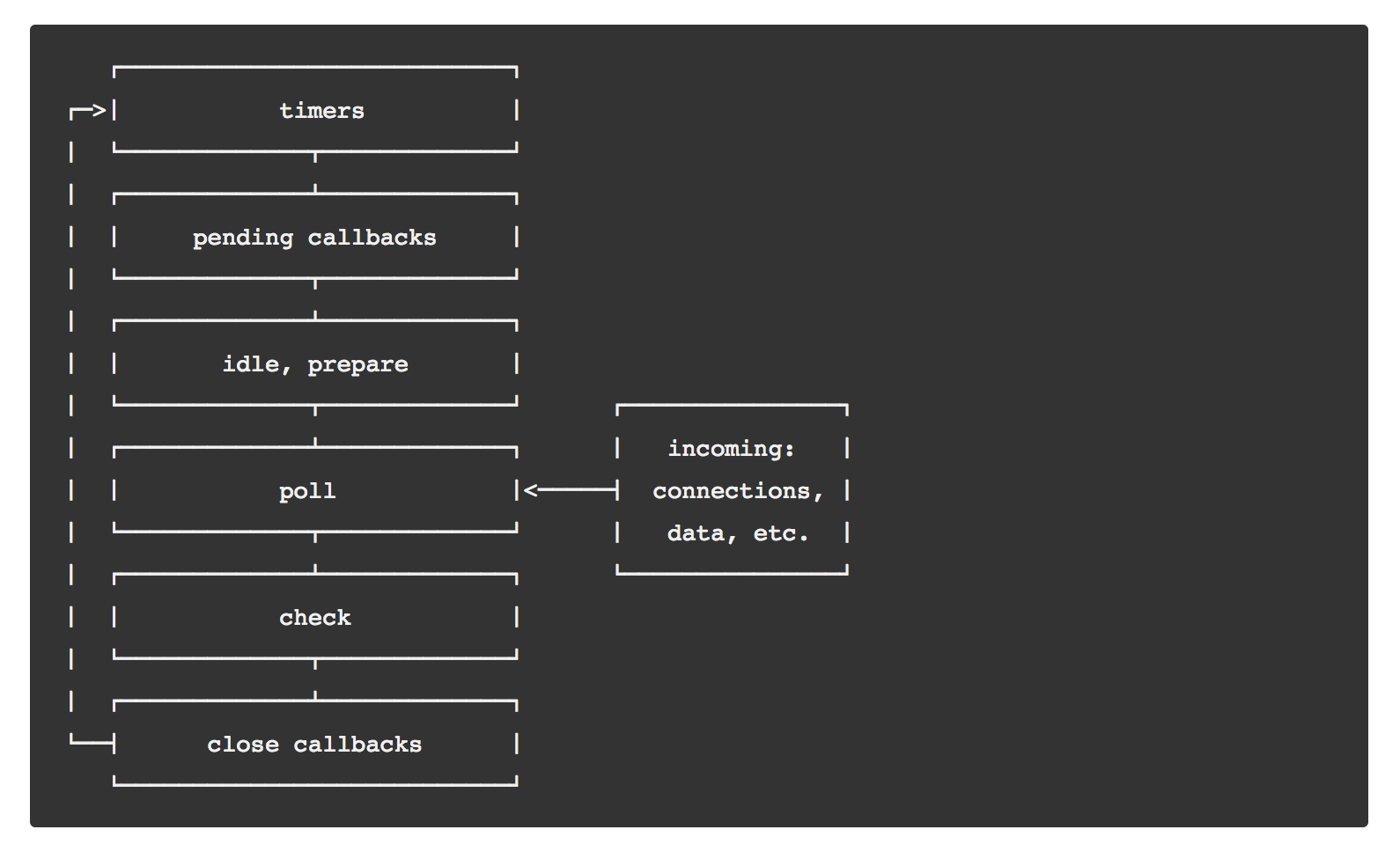
JavaScript має асинхронну поведінку, тому часто ми не виконуємо все в один момент. Не будуть виконані одразу після виклику:
Наприклад, Promise.resolve для негайної обробки promises. Таким чином, код буде виконано у тій же ітерації циклу обробки подій, але після синхронного коду.
Специфічний метод Node.js, який не існує в жодному браузері (так само, як і об'єкт process). Він має подібну до microtask поведінку, але має пріоритетність, а це означає, що виконується одразу після синхронного коду, навіть якщо раніше було введено інший microtask. Така поведінка є небезпечною, бо призводить до нескінченних циклів. Назва методу трохи невдала, адже він виконується під час тієї ж ітерації циклу, а не наступній (next tick).
Існує у деяких браузерах, але поведінка методу непослідовна, тому треба бути дуже обережним із його застосуванням. Схожий на setTimeout(0), але має більшу пріоритетність. Назва тут також не найкраща: мова йде про наступну ітерацію циклу, а вона не зовсім негайна (immediate).
Таймери поводяться однаково як у Node, так і у браузері. Важливо враховувати, що після часу затримки, який ми вказуємо, колбек функція не гарантовано буде виконана. Насправді Node.js виконає колбек після закінчення цього часу, як тільки основний цикл завершить всі операції (враховуючи microtasks), і не буде інших таймерів з вищими пріоритетами.
Розглянемо приклад застосування перелічених методів:
const fs = require('fs');
console.log('початок програми');
const promise = new Promise(resolve => {
// Функція, передана конструктору Promise
// виконується синхронно!
console.log('Я у promise-функції!');
resolve('resolved-повідомлення');
});
promise.then(() => {
console.log('Я у першому виконаному promise');
}).then(() => {
console.log('Я у другому виконаному promise');
});
process.nextTick(() => {
console.log('Я зараз перебуваю у процесі nextTick');
});
fs.readFile('index.html', () => {
console.log('==================');
setTimeout(() => {
console.log('Я знаходжуся у колбеку setTimeout із затримкою 0 мс');
}, 0);
setImmediate(() => {
console.log('Я від колбеку setImmediate');
});
});
setTimeout(() => {
console.log('Я знаходжуся у колбеку setTimeout із затримкою 0 мс');
}, 0);
setImmediate(() => {
console.log('Я від колбеку setImmediate');
});
Правильний порядок виконання наступний:
> node event-loop.js
початок програми
Я у promise-функції!
Я зараз перебуваю у процесі nextTick
Я у першому виконаному promise
Я у другому виконаному promise
Я знаходжуся у колбеку setTimeout із затримкою 0 мс
Я від колбеку setImmediate
==================
Я від колбеку setImmediate
Я знаходжуся у колбеку setTimeout із затримкою 0 мс
Ви можете дізнатися більше про цикл подій та метод process.nextTick в офіційній документації Node.js.
Прослуховувачі подій
Багато основних модулів у Node.js генерують або отримують різні події. В Node.js є поняття EventEmitter, який є шаблоном проектування «публікації-підписки». Принцип дуже схожий на події DOM у браузері, але з деякою різницею у синтаксисі. Для розуміння поняття Event Emitter, реалізуємо його самостійно:
class EventEmitter {
constructor() {
this.events = {};
}
checkExistence(event) {
if (!this.events[event]) {
this.events[event] = [];
}
}
once(event, cb) {
this.checkExistence(event);
const cbWithRemove = (...args) => {
cb(...args);
this.off(event, cbWithRemove);
};
this.events[event].push(cbWithRemove);
}
on(event, cb) {
this.checkExistence(event);
this.events[event].push(cb);
}
off(event, cb) {
this.checkExistence(event);
this.events[event] = this.events[event].filter(
registeredCallback => registeredCallback !== cb
);
}
emit(event, ...args) {
this.checkExistence(event);
this.events[event].forEach(cb => cb(...args));
}
}
( Реалізація просто показує сам шаблон і не націлена на певну функціональність)
Наведений код дозволяє генерувати події, підписуватися на них та відписуватися пізніше. Наприклад, response object, request object, stream реалізують або розширюють механізм Event Emitter.
Зважаючи на простоту концепції, вона реалізована у багатьох пакетах npm:1,2,3 та у інших. Тому, якщо хочете використовувати один і той же Event Emitter у браузері — спокійно використовуйте.
Потоки
Потоки — найкорисніше і, у той же час, найбільш складне для розуміння поняття Node.js.
Потоки дозволяють обробляти дані частинами, а не суцільно, як результат повної операції (наприклад, читання файлу). Щоб зрозуміти навіщо вони потрібні, приведу простий приклад: припустимо, необхідно на запит користувача повернути файл довільного розміру. Код буде виглядати так:
function (req, res) {
const filename = req.url.slice(1);
fs.readFile(filename, (err, data) => {
if (err) {
res.statusCode = 500;
res.end('Щось пішло не так');
} else {
res.end(data);
}
});
}
Наведений код буде працювати, але все ж є важливі недоліки. У нас можуть виникнути проблеми у разі, якщо файл занадто великий: коли ми читаємо файл, ми розміщуємо все в пам'яті, і якщо у нас недостатньо ресурсів, код не буде працювати коректно. У разі великої кількості паралельних запитів також виникне помилка, оскільки нам необхідно зберігати об'єкт data у пам'яті, доки вся інформація не буде відправлена.
Виявляється файл нам зовсім не потрібен, ми просто повертаємо його з файлової системи, при цьому не оглядаючи вміст самостійно. Тож можемо прочитати якусь частину файлу, повернути негайно, звільнити пам'ять і повторити усі дії знову, поки не закінчимо. Простіше кажучи, у нас є механізм отримання даних шматками, а ми вже самі вирішуємо, що робити з цими даними. Наприклад, можемо зробити щось на зразок:
function (req, res) {
const filename = req.url.slice(1);
const filestream = fs.createReadStream(filename, { encoding: 'utf-8' });
let result = '';
filestream.on('data', chunk => {
result += chunk;
});
filestream.on('end', () => {
res.end(result);
});
// якщо файл не існує, буде передано помилку у колбек
filestream.on('error', () => {
res.statusCode = 500;
res.end('Щось пішло не так');
});
}
Тут ми створюємо потік для читання з файлу, який реалізує клас EventEmitter. При здійсненні події data ми отримуємо наступний шматок, а при здійсненні end — отримуємо сигнал, що потік закінчився, а увесь файл було прочитано. Така реалізація працює подібно до вже наведених: ми чекаємо, поки весь файл буде прочитано, а потім повертаємо його у відповіді. Крім того, проблем не уникаємо: нам необхідно утримувати увесь файл у пам'яті до моменту його повернення. Для вирішення проблеми необхідно знати, що об'єкт відповіді самостійно впроваджує потік для запису даних, а ми можемо записувати інформацію в цей потік, не тримаючи її в пам'яті:
function (req, res) {
const filename = req.url.slice(1);
const filestream = fs.createReadStream(filename, { encoding: 'utf-8' });
filestream.on('data', chunk => {
res.write(chunk);
});
filestream.on('end', () => {
res.end();
});
// якщо файл не існує, буде передано помилку у колбек
filestream.on('error', () => {
res.statusCode = 500;
res.end('Щось пішло не так');
});
}
Об'єкт відповіді відкриває потік для запису, а fs.createReadStream створює потік для читання, а також дуплексні та трансформаційні потоки. Різниця між принципами їхньої роботи виходить за рамки цього керівництва, але непогано знати про існування таких потоків.
Тепер зовсім нема потреби у змінній result. Ми вже записали блоки даних у відповідь, а тому не зберігаємо їх у пам'яті. Можемо читати навіть великі файли та не турбуватися про велику кількість паралельних запитів — ми все одно не вичерпаємо нашу пам'ять. Однак, існує проблема. В наведеній реалізації ми читаємо з одного потоку (файлова система читає з файлу) та пишемо в інший потік (запит мережі), а ці процеси мають різні затримки. Таким чином, через певний час потік відповідей буде перевантажено, тому що він повільніший. Node знає як це виправити. У кожного потоку читання є pipe-метод, який перенаправляє усі дані у потік з урахуванням його навантаження: якщо він зайнятий, метод тимчасово зупинить вихідний потік, а потім відновить його. З таким методом можна спростити наш код:
function (req, res) {
const filename = req.url.slice(1);
const filestream = fs.createReadStream(filename, { encoding: 'utf-8' });
filestream.pipe(res);
// якщо файл не існує, буде передано помилку у колбек
filestream.on('error', () => {
res.statusCode = 500;
res.end('Щось пішло не так');
});
}
Механізм роботи потоків змінювався декілька разів протягом розвитку Node, тому треба бути дуже обережним із читанням старих посібників та завжди узгоджувати інформацію з офіційною документацією.
Модульна система
В Node.js використовуються commonjs модулі. Напевно, ви вже мали справу з ними кожен раз, використовуючи require для розміщення модуля у webpack конфігурації. Або ви бачили щось на зразок exports.some = {} без module. Тому розглянемо детальніше як це працює.
Спочатку поговоримо про commonjs модулі зі звичним розширенням .js, а не .esm/.mjs файли (ECMAScript modules), що дають можливість використовувати синтаксис import/export. Також важливо розуміти, що webpack та browserify (а також інші інструменти для збірки проекту) використовують власну функцію require, тому не плутайте її з require у Node, хоч вони й мають спільні риси.
Тож де ми насправді зустрічаємо «глобальні» об'єкти на зразок module, require та exports? Node.js додає їх — замість того, щоб просто виконувати наданий js-файл, він тобто обгортає його у функцію зі всіма цими змінними:
function (exports, require, module, __filename, __dirname) {
// ваш модуль
}
Можна продемонструвати у командному рядку:
node -e "console.log(require('module').wrapper)"
Змінні, які вводяться в модуль, доступні як «глобальні», навіть якщо такими не є насправді. Корисним буде більш детальне ознайомлення з цими змінними, особливо із module. Достатньо лише виконати console.log(module) у js-файлі. Потім спробуйте порівняти результати
при виводі інформації з «основного» файлу, а потім з необхідного.
Далі розглянемо об'єкт exports. У наведеному нижче прикладі охоплено особливості обробки об'єкта:
exports.name = 'our name'; // працює
exports = { name: 'our name' }; // не працює
module.exports = { name: 'our name' }; //працює
Приклад вище може спантеличити вас. Чому саме так? Відповідь у природі об'єкта exports. Це просто аргумент, який передається функції, тому у разі присвоєння нового об'єкту, ми лише перевизначаємо змінну, а старе значення зникає, але не повністю. module.exports — той самий об'єкт. Тобто, фактично, module.exports і exports — посилання на єдиний об'єкт:
module.exports === exports; // true
Наостанок розглянемо require — функцію, що приймає ім'я модуля і повертає об'єкт exports цього модуля. Як насправді приєднати модуль? Існують досить прості правила:
-
перевірте основні модулі на відповідність вказаному імені;
-
якщо шлях починається з ./ або ../, спробуйте приєднати файл;
-
якщо відповідного файлу знайдено не було, спробуйте знайти директорію із файлом
index.js; -
якщо шлях не починається з ./ або ../, перейдіть у
node_modules/та перевірте там директорію/файл:-
у директорії, де запускаються скрипти;
-
на рівень вище, поки не знайдемо
node_modules/;
-
Існують також інші сумісні місця, і ви можете також вказати свій шлях, застосувавши для пошуку спеціальну змінну NODE_PATH. Якщо ж ви хочете бачити точний порядок, в якому підключаються node_modules, вкажіть об'єкт module у вашому скрипті та шукайте властивість paths. У мене результат наступний:
➜ tmp node test.js
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/seva.zaikov/tmp/test.js',
loaded: false,
children: [],
paths:
[ '/Users/seva.zaikov/tmp/node_modules',
'/Users/seva.zaikov/node_modules',
'/Users/node_modules',
'/node_modules' ] }
Цікаво, що після першого виклику require модуль кешується і не виконується знову. Ми лише повертаємось до кешованого об'єкта exports, тобто ви можете організовувати певну логіку і бути впевненими, що вона виконається лише один раз, після першого виклику require (але можна видалити id модуля з require.cache, тоді модуль буде перезавантажено).
Змінні середовища
Як зазначено у the twelve-factor app, хорошим тоном є зберігання конфігурації у змінних середовища. Ви можете налаштувати змінні для сесії shell:
export MY_VARIABLE="якесь значення змінної"
Node є кросплатформеним механізмом, тому, в ідеалі, ваш застосунок повинен запускатися на будь-якій платформі (наприклад, ви обираєте середовище для виконання коду, і, як правило, це якийсь дистрибутив Linux). Наведені приклади охоплюють лише MacOS/Linux і не будуть працювати для Windows. Синтаксис змінних оточення у Windows інший. Звичайно, можна використовувати щось на зразок cross-env.
Додайте наведений рядок до вашого bash/zsh профілю. Налаштування виконається при запуску нової сесії терміналу. Однак, зазвичай ви запускаєте застосунок, використовуючи змінні з наведеного прикладу:
APP_DB_URI="....." SECRET_KEY="секретний ключ" node server.js
Можна отримати доступ до цих змінних у застосунку, використовуючи об'єкт process.env:
const CONFIG = {
db: process.env.APP_DB_URI,
secret: process.env.SECRET_KEY
}
Об'єднаємо все
У наведеному нижче прикладі ми створимо простий http сервер, який буде повертати файл з ім'ям, що містить рядок url після /. Якщо файлу не існує, ми повертаємо 404 Not Found, а якщо користувач намагається використати відносний або вкладений шлях, повернемо помилку 403. Деякі функції ми вже використовували, але не коментували, тому у наведеному фрагменті буде багато пояснень:
// Нам необхідні лише вбудовані модулі, тому Node.js
// не перешкоджає нашим `node_modules` директоріям
// https://nodejs.org/api/http.html#http_http_createserver_options_requestlistener
const { createServer } = require("http");
const fs = require("fs");
const url = require("url");
const path = require("path");
// ми передаємо ім'я директорії з файлами як змінну середовища
// тому можемо використовувати різні директорії локально
const FOLDER_NAME = process.env.FOLDER_NAME;
const PORT = process.env.PORT || 8080;
const server = createServer((req, res) => {
// req.url зберігає повний url, із рядком-запитом
// раніше це ігнорувалося, але зараз необхідно впевнитися
// що ми отримуємо лише назву шляху без рядка-запита
// https://nodejs.org/api/http.html#http_message_url
const parsedURL = url.parse(req.url);
// нам не потрібен перший `/` символ
const pathname = parsedURL.pathname.slice(1);
// для повернення відповіді необхідно викликати `res.end()`
// https://nodejs.org/api/http.html#http_response_end_data_encoding_callback
//
// > Метод response.end(), НЕОБХІДНО викликати для кожної відповіді.
// Якщо ж уникати виклику, зв'язок не припиниться, a запит
// буде очікуватися аж після таймауту
//
// за замовчуванням, ми повертаємо відповідь з кодом 200
// якщо щось пішло не так, існує можливість повернути
// коректний код статусу, використовуючи властивість `res.statusCode = ...`:
// https://nodejs.org/api/http.html#http_response_statuscode
if (pathname.startsWith(".")) {
res.statusCode = 403;
res.end("Відносні шляхи не дозволені");
} else if (pathname.includes("/")) {
res.statusCode = 403;
res.end("Вкладені шляхи не дозволені");
} else {
// https://nodejs.org/en/docs/guides/working-with-different-filesystems/
// щоб зберегти кросплатформеність, можемо самостійно створити шлях
// необхідно використовувати роздільник, специфічний для платформи
// path.join() робить це за нас:
// https://nodejs.org/api/path.html#path_path_join_paths
const filePath = path.join(__dirname, FOLDER_NAME, pathname);
const fileStream = fs.createReadStream(filePath);
fileStream.pipe(res);
fileStream.on("error", e => {
// ми обробляємо лише помилку, пов'язану з файлами, що не існують, але є безліч
// можливих помилок. Усі можливі коди помилок можна знайти в документації:
// https://nodejs.org/api/errors.html#errors_common_system_errors
if (e.code === "ENOENT") {
res.statusCode = 404;
res.end("Файл не існує.");
} else {
res.statusCode = 500;
res.end("Внутрішня помилка сервера");
}
});
}
});
server.listen(PORT, () => {
console.log(`застосунок слухає за портом ${PORT}`);
});
Висновок
Керівництво охоплює багато фундаментальних принципів Node.js. Хоч ми не заглиблювалися в конкретні API, упускали багато моментів, але стаття неодмінно повинна додати впевненості у створенні та редагуванні скриптів. Тепер ви можете аналізувати помилки, розуміти які інтерфейси використовують вбудовані модулі та що очікувати від звичних об'єктів та інтерфейсів в Node.js.

Ще немає коментарів