
Повнотекстовий пошук - один з тих інструментів, які ми використовуємо практично кожен день, коли шукаємо якусь інформацію в інтернеті. Full-Text Search (FTS) - це метод пошуку тексту в колекції документів. Документ може посилатися на веб-сторінку, газетну статтю, повідомлення електронної пошти або будь-який структурований текст.
Сьогодні ми збираємося написати власний рушій FTS. До кінця цієї статті він зможе виконувати пошук по мільйонах документів менш ніж за мілісекунду. Почнемо з простих пошукових запитів, таких як «Видати всі документи зі словом cat», а потім розширимо рушій для підтримки складніших логічних запитів.
Примітка: найвідомішим рушієм повнотекстового пошуку є Lucene (а також Elasticsearch і Solr, побудовані на його основі).
Навіщо потрібен FTS
Перед тим, як писати код, ви можете запитати: «А чи не можна просто використовувати grep або цикл з перевіркою кожного документа на входження шуканого слова?» Так можна. Але це не завжди найкраща ідея.
Колекція даних
Будемо шукати фрагменти анотацій з англомовної Вікіпедії. Останній дамп доступний за адресою dumps.wikimedia.org . На сьогоднішній день розмір файлу після розпакування становить 913 МБ. У XML-файлі більше 600 тис. Документів.
Приклад документа:
<title>Wikipedia: Kit-Cat Klock</title> <url>https://en.wikipedia.org/wiki/Kit-Cat_Klock</url> <abstract>The Kit-Cat Klock is an art deco novelty wall clock shaped like a grinning cat with cartoon eyes that swivel in time with its pendulum tail.</abstract>
Завантаження документів
Спочатку потрібно завантажити всі документи з дампа, використовуючи дуже зручний вбудований пакет encoding/xml:
import (
"encoding/xml"
"os"
)
type document struct {
Title string `xml:"title"`
URL string `xml:"url"`
Text string `xml:"abstract"`
ID int
}
func loadDocuments(path string) ([]document, error) {
f, err := os.Open(path)
if err != nil {
return nil, err
}
defer f.Close()
dec := xml.NewDecoder(f)
dump := struct {
Documents []document `xml:"doc"`
}{}
if err := dec.Decode(&dump); err != nil {
return nil, err
}
docs := dump.Documents
for i := range docs {
docs[i].ID = i
}
return docs, nil
}
Кожному документу присвоюється унікальний ID. Для простоти першому завантаженому документу присвоюється ID = 0, другому ID = 1 і так далі.
Перша спроба
Пошук контенту
Тепер у нас всі документи завантажені в пам'ять, спробуємо знайти ті, в яких згадуються коти. Спочатку пройдемося по всіх документах і перевіримо їх на рядок cat:
func search(docs []document, term string) []document {
var r []document
for _, doc := range docs {
if strings.Contains(doc.Text, term) {
r = append(r, doc)
}
}
return r
}
На моєму ноутбуці пошук займає 103 мс - не так уже й погано. Якщо вибірково перевірити кілька документів з видачі, то можна помітити, що функція видає відповідність на слова caterpillar і category , але не на Cat з великою літерою C. Це не зовсім те, що ми шукаємо.
Перш ніж продовжувати, потрібно виправити дві речі:
- Зробити пошук нечутливим до регістру (щоб видача включала і Cat ).
- Врахувати кордон слів, а не підрядка (щоб у видачі не було слів на кшталт caterpillar і category ).
Пошук за допомогою регулярних виразів
Одне з очевидних рішень, яке вирішує обидві проблеми - регулярні вирази .
В даному випадку нам потрібно (?i)\bcat\b:
(?i)означає нечутливість регулярного виразу до регістру\bвказує на відповідність кордонів слів (місце, де з одного боку є символ, а з іншого боку немає)
func search(docs []document, term string) []document {
re := regexp.MustCompile(`(?i)\b` + term + `\b`) // Don't do this in production, it's a security risk. term needs to be sanitized.
var r []document
for _, doc := range docs {
if re.MatchString(doc.Text) {
r = append(r, doc)
}
}
return r
}
Але тепер пошук зайняв більше двох секунд. Як бачите, система почала гальмувати навіть на скромному корпусі з 600 тис. документів. Хоча такий підхід легко реалізувати, він не дуже добре масштабується. В міру збільшення набору даних потрібно сканувати все більше документів. Часова складність такого алгоритму лінійна, тобто кількість документів для сканування дорівнює загальній кількості документів. Якби у нас було 6 мільйонів документів замість 600 тисяч, пошук зайняв би 20 секунд. Доведеться придумати щось краще.
Інвертований індекс
Щоб прискорити пошукові запити, ми попередньо опрацюємо текст і побудуємо індекс.
Ядром FTS є структура даних, яка називається інвертований індекс . Він пов'язує кожне слово з документами, що містять це слово.
Приклад:
documents = {
1: "a donut on a glass plate",
2: "only the donut",
3: "listen to the drum machine",
}
index = {
"a": [1],
"donut": [1, 2],
"on": [1],
"glass": [1],
"plate": [1],
"only": [2],
"the": [2, 3],
"listen": [3],
"to": [3],
"drum": [3],
"machine": [3],
}
Нижче наведено реальний приклад інвертованого індексу. Це покажчик в книзі, де термін супроводжується номерами сторінок:
Аналіз тексту
Перш ніж взятися за побудову індексу, потрібно розбити вихідний текст на список слів (токенів), придатних для індексації та пошуку.
Аналізатор тексту складається з токенізатора і декількох фільтрів.
Токенізатор
Токенізатор - це перший крок в аналізі тексту. Його завдання - перетворити текст в список токенов. Наша реалізація розбиває текст на кордонах слів і видаляє знаки пунктуації:
func tokenize(text string) []string {
return strings.FieldsFunc(text, func(r rune) bool {
// Split on any character that is not a letter or a number.
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
})
}
> tokenize("A donut on a glass plate. Only the donuts.")
["A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"]
Фільтри
У більшості випадків недостатньо простого перетворення тексту в список токенов. Щоб полегшити індексацію і пошук, потрібна додаткова нормалізація.
Малі літери
Щоб пошук був нечутливий до регістру, фільтр малих літер перетворює токени в нижній регістр. Слова cAt , Cat і caT нормалізуються до форми cat . Пізніше при зверненні до індексу ми також нормалізуємо в нижній регістр і пошукові запити, так що пошуковий запит cAt знайде слово Cat .
func lowercaseFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = strings.ToLower(token)
}
return r
}
> lowercaseFilter([]string{"A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"})
["a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"]
Видалення загальновживаних слів
Майже будь-який англомовний текст містить загальновживані слова, такі як a, I, The або be . Вони називаються стоп-словами і присутні майже в усіх документах, так що їх слід видалити.
Немає ніякого «офіційного» списку стоп-слів. Давайте виключимо топ-10 по списку OEC . Не соромтеся доповнювати його:
var stopwords = map[string]struct{}{ // I wish Go had built-in sets.
"a": {}, "and": {}, "be": {}, "have": {}, "i": {},
"in": {}, "of": {}, "that": {}, "the": {}, "to": {},
}
func stopwordFilter(tokens []string) []string {
r := make([]string, 0, len(tokens))
for _, token := range tokens {
if _, ok := stopwords[token]; !ok {
r = append(r, token)
}
}
return r
}
> stopwordFilter([]string{"a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"})
["donut", "on", "glass", "plate", "only", "donuts"]
Стемінг
Через граматичні правила в документах зустрічаються різні форми слів. Стемінг зводить їх до основної форми. Наприклад, fishing , fished і fisher зводяться до основної форми fish .
Реалізація стемінгу - нетривіальне завдання, вона не розглядається в цій статті. Візьмемо один з існуючих модулів:
import snowballeng "github.com/kljensen/snowball/english"
func stemmerFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = snowballeng.Stem(token, false)
}
return r
}
> stemmerFilter([]string{"donut", "on", "glass", "plate", "only", "donuts"})
["donut", "on", "glass", "plate", "only", "donut"]
Примітка: Стемер не завжди працюює коректно. Наприклад, деякі можуть скоротити airline до airlin .
Збірка аналізатора
func analyze(text string) []string {
tokens := tokenize(text)
tokens = lowercaseFilter(tokens)
tokens = stopwordFilter(tokens)
tokens = stemmerFilter(tokens)
return tokens
}
Токенізатор і фільтри перетворять речення в список токенов:
> analyze("A donut on a glass plate. Only the donuts.")
["donut", "on", "glass", "plate", "only", "donut"]
Токени готові до індексації.
Побудова індексу
Повернемося до інвертованого індексу. Він зіставляє кожне слово з ідентифікаторами документів. Для зберігання карти добре підходить вбудований тип даних map. Ключем буде токен (рядок), а значенням - список ідентифікаторів документів:
type index map[string][]int
В процесі побудови індексу відбувається аналіз документів і додавання їх ідентифікаторів в карту:
func (idx index) add(docs []document) {
for _, doc := range docs {
for _, token := range analyze(doc.Text) {
ids := idx[token]
if ids != nil && ids[len(ids)-1] == doc.ID {
// Don't add same ID twice.
continue
}
idx[token] = append(ids, doc.ID)
}
}
}
func main() {
idx := make(index)
idx.add([]document{{ID: 1, Text: "A donut on a glass plate. Only the donuts."}})
idx.add([]document{{ID: 2, Text: "donut is a donut"}})
fmt.Println(idx)
}
Все працює! Кожен токен в карті посилається на ідентифікатори документів, що містять цей токен:
map[donut:[1 2] glass:[1] is:[2] on:[1] only:[1] plate:[1]]
Запити
Для запитів до індексу застосуємо той же токенізатор і фільтри, які використовували для індексації:
func (idx index) search(text string) [][]int {
var r [][]int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
r = append(r, ids)
}
}
return r
}
> idx.search("Small wild cat")
[[24, 173, 303, ...], [98, 173, 765, ...], [[24, 51, 173, ...]]
І тепер, нарешті, ми можемо знайти всі документи, в яких згадуються кішки. Пошук по 600 тис. Документів зайняв менше мілісекунди (18 мкс)!
При використанні інвертованого індексу часова складність пошукового запиту лінійна по відношенню до числа пошукових токенов. У наведеному вище прикладі запиту, крім аналізу вхідного тексту, виконується всього три пошуки по карті.
Логічні запити
Попередній запит повернув непов'язаний список документів для кожного токена. Але ми зазвичай очікуємо, що пошук по фразі small wild cat видає список результатів, які містять одночасно small, wild і cat . Наступний крок - обчислити перетин між списками. Таким чином, ми отримаємо список документів, які відповідають усім токенам.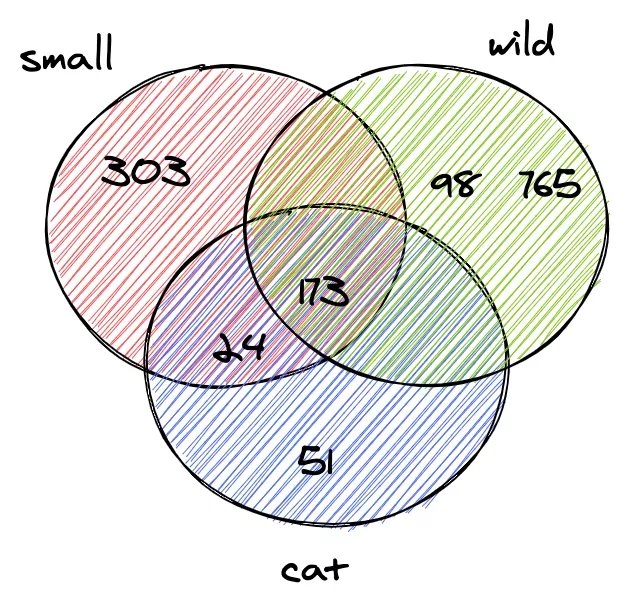
На щастя, ідентифікатори в нашому інвертованому індексі вставляються в порядку зростання. Оскільки ID відсортовані, можна обчислити перетин між списками в лінійному часі. Функція intersection одночасно виконує обхід двох списків і збирає ідентифікатори, які присутні в обох:
func intersection(a []int, b []int) []int {
maxLen := len(a)
if len(b) > maxLen {
maxLen = len(b)
}
r := make([]int, 0, maxLen)
var i, j int
for i < len(a) && j < len(b) {
if a[i] < b[j] {
i++
} else if a[i] > b[j] {
j++
} else {
r = append(r, a[i])
i++
j++
}
}
return r
}
Оновлений search аналізує пошуковий запит, шукає токени і обчислює перетин між списками ID:
func (idx index) search(text string) []int {
var r []int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
if r == nil {
r = ids
} else {
r = intersection(r, ids)
}
} else {
// Token doesn't exist.
return nil
}
}
return r
}
У дампі Вікіпедії лише два документи, які одночасно містять слова small, wild і cat :
> idx.search("Small wild cat")
130764 The wildcat is a species complex comprising two small wild cat species, the European wildcat (Felis silvestris) and the African wildcat (F. lybica).
131692 Catopuma is a genus containing two Asian small wild cat species, the Asian golden cat (C. temminckii) and the bay cat.
Пошук працює як належить!
Висновки
Отже, ми зробили рушій для повнотекстового пошуку. Незважаючи на свою простоту, він може стати міцною основою для просунутіших проєктів.
Я не згадав про багато аспектів, які можуть значно поліпшити продуктивність і зробити пошук зручніше. Ось деякі ідеї для подальших поліпшень:
- Додати логічні оператори OR і NOT .
- Зберігати індекс на диску:
- Відновлення індексу при кожному перезапуску програми займає деякий час.
- Великі індекси можуть не поміститися в пам'яті.
- Поекспериментувати з пам'яттю і оптимізованими для CPU форматами даних для зберігання наборів ID. Поглянути на Roaring Bitmaps .
- Індексація декількох полів документа.
- Сортувати результати за релевантністю.
Весь вихідний код опубліковано на GitHub .
Джерело: artem.krylysov.com

Ще немає коментарів