Пакет logging в Python — легке та розширюване рішення для відстеження роботи вашого коду. Якщо ви досі розкидуєте print() після кожного рядка, зверніть увагу на гнучкі можливості logging.
Однак при глибшому зануренні в logging можуть виникнути певні труднощі. Обробники, логери, рівні, простори імен, фільтри: не так вже і легко зрозуміти, як всі ці компоненти взаємодіють.
Один зі способів остаточно розібратися, як працює logging — зазирнути «під капот» його CPython сирцевого коду. Враховуючи його стислість та модульність, ви легко зрозумієте усі тонкощі роботи пакету.
Цей матеріал є продовженням документацій HOWTO та статті Логування в Python для logging.
Після прочитання статті ви будете розуміти:
- рівні в
loggingта принцип їх роботи; - thread-safety проти process-safety;
-
loggingз погляду концепцій ООП; -
loggingв бібліотеках та застосунках; - найкращі практики та патерни проектування для
logging.
Як працювати з матеріалом
Основну увагу в статті приділено сирцевому коду logging, тож вважатимем, що будь-який блок коду чи посилання базується на певному коміті з репозиторію Python 3.7 CPython, а саме commit d730719. Сам пакет logging можна знайти в директорії Lib/.
Всередині пакету logging основну увагу приділимо файлу logging/__init__.py.
cpython/
│
├── Lib/
│ ├── logging/
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── handlers.py
│ ├── ...
├── Modules/
├── Include/
...
... [truncated]
Почнемо!
Підготовка
Перш ніж перейдемо до основних класів, оглянемо десь перші сто рядків __init__.py, які дають уявлення про деякі важливі поняття.
Поняття №1: Рівень — це просто int
Об'єкти на зразок logging.INFO чи logging.DEBUG здаються незрозумілими на перший погляд. Постає питання: що вони утворюють \ на внутрішньому рівні і який вигляд мають у коді?
Насправді константи з logging — просто цілочислові значення, що формують колекцію рівнів на зразок переліку:
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
Але чому б просто не використовувати рядки, наприклад INFO або DEBUG? Усе тому, що тип int дозволяє порівнювати рівні просто та однозначно. Назви рівнів обрані відповідно до їхнього семантичного значення. Тобто «повідомлення з рівнем серйозності 50» — це не так очевидно, як CRITICAL-повідомлення. Так ви одразу дізнаєтесь, коли у вашій програмі щось пішло не так.
Технічно, ви можете передати лише str-форму рівня у деякі місця коду, такі як logger.setLevel("DEBUG"). Внутрішньо відбудеться виклик _checkLevel(), який здійснить пошук в словнику відповідного int:
_nameToLevel = {
'CRITICAL': CRITICAL,
'FATAL': FATAL,
'ERROR': ERROR,
'WARN': WARNING,
'WARNING': WARNING,
'INFO': INFO,
'DEBUG': DEBUG,
'NOTSET': NOTSET,
}
def _checkLevel(level):
if isinstance(level, int):
rv = level
elif str(level) == level:
if level not in _nameToLevel:
raise ValueError("Unknown level: %r" % level)
rv = _nameToLevel[level]
else:
raise TypeError("Level not an integer or a valid string: %r" % level)
return rv
Якому способу слід віддати перевагу? Точної відповіді немає, проте слід зважати, що в документації logging використовується форма logging.DEBUG, а не "DEBUG" чи 10. До того ж str форма не підходить для Python 2 і деякі методи logging (на зразок logger.isEnabledFor()) працюють лише з int.
Поняття №2: logging — потокобезпечний, але не процесобезпечний
Нижче ви знайдете короткий блок коду, критично важливий для всього пакету:
import threading
_lock = threading.RLock()
def _acquireLock():
if _lock:
_lock.acquire()
def _releaseLock():
if _lock:
_lock.release()
Об'єкт _lock — reentrant lock, розташований в глобальному просторі імен модуля logging/__init__.py. Він робить практично кожен об'єкт та операцію в усьому пакеті logging потокобезпечними, дозволяючи потокам виконувати операції читання та запису, не турбуючись про стан перегонів. В сирцевому коді модуля можна побачити, що _acquireLock() та _releaseLock() поширюються на модуль та його класи.
Однак чогось тут не вистачає: як щодо безпеки процесів? Як вже можна здогадатися, модуль logging не є процесобезпечним. І logging тут не винен: як правило, два процеси не можуть писати в один і той самий файл без участі розробника.
Тобто треба бути обережним перед використанням класів на зразок logging.FileHandler, що працюють з декількома процесами. Якщо два процеси захочуть виконувати певні операції з тим самим файлом, ви отримаєте неприємний баг.
Якщо хочете обійти ці обмеження, є чудове рішення з офіційної Logging Cookbook. Однак там багато налаштувань, тому розгляньте і альтернативний варіант: щоб кожен процес писав логи в окремий файл, визначений ID процесу, який можна отримати за допомогою os.getpid().
Архітектура пакету: порядок вирішення методів (MRO) для Logging
Ми вже визначились з деякими поняттями і готові перейти до глибшого ознайомлення з logging. Він базується на принципах ООП.
Оглянемо порядок вирішення модулів (MRO) для деяких найбільш важливих методів пакету:
object
│
├── LogRecord
├── Filterer
│ ├── Logger
│ │ └── RootLogger
│ └── Handler
│ ├── StreamHandler
│ └── NullHandler
├── Filter
└── Manager
Ця структура охоплює лише найбільш важливі класи модуля.
Помітьте: ви можете використовувати dunder-атрибут logging.StreamHandler.mro, щоб побачити ланцюжок наслідування. Повний посібник з MRO можна знайти в документації до Python 2, хоч він підійде і до Python 3.
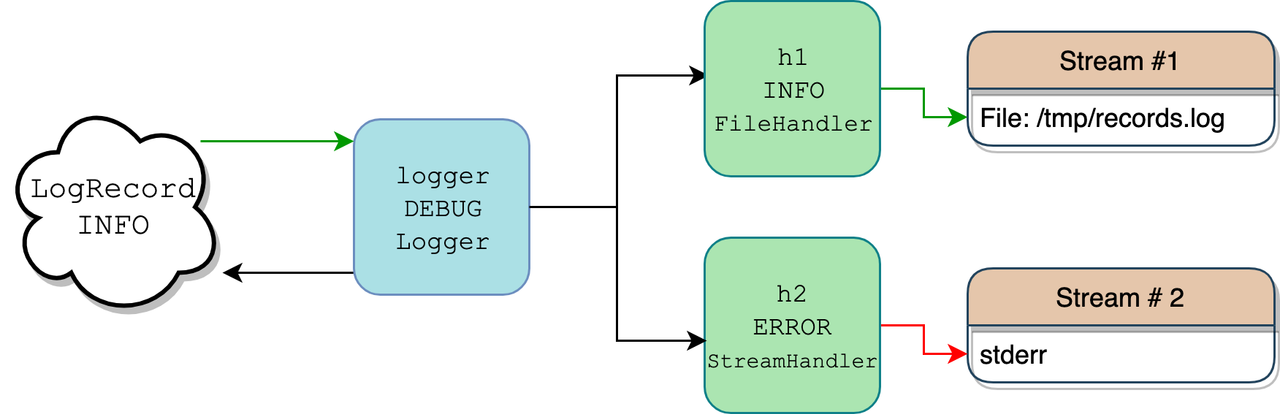
Класи заплутані та збивають з пантелику. Filter чи Filterer? Logger чи Handler? Це складно відстежувати без розуміння того, як класи взаємодіють на практиці. Тут допоможе діаграма сценарію, коли один логер з двома обробниками записує повідомлення з рівнем logging.INFO:
В коді на Python це реалізовано так:
import logging
import sys
logger = logging.getLogger("pylog")
logger.setLevel(logging.DEBUG)
h1 = logging.FileHandler(filename="/tmp/records.log")
h1.setLevel(logging.INFO)
h2 = logging.StreamHandler(sys.stderr)
h2.setLevel(logging.ERROR)
logger.addHandler(h1)
logger.addHandler(h2)
logger.info("testing %d.. %d.. %d..", 1, 2, 3)
Більш детальне пояснення процесу можна знайти в Logging HOWTO. Вище — лише полегшений сценарій.
В коді створюється лише один екземпляр Logger — logger, а також два екземпляри Handler — h1 та h2.
Коли ви викликаєте logger.info("testing %d.. %d.. %d..", 1, 2, 3), об'єкт logger поводиться як фільтр, відповідно до визначеного level. Тільки якщо рівень повідомлення достатньо високий, логер може з ним щось робити. Оскільки наш логер має рівень DEBUG, а повідомлення має вищий рівень, INFO, він рухається далі.
Внутрішньо logger викликає logger.makeRecord() , щоб передати рядок повідомлення "testing %d.. %d.. %d.." та його аргументи (1,2,3) в екземпляр класу LogRecord, який є контейнером для повідомлення та метаданих.
Об'єкт logger знаходить своїх обробників (екземпляри Handler), які можуть приєднатись безпосередньо до logger або до його батьків (оглянемо цю концепцію пізніше). В наведеному прикладі він знаходить два обробники:
- Один з рівнем
INFO, що закидує дані до файлу/tmp/records.log. - Інший записує до
sys.stderr, але лише якщо повідомлення надходить з рівнем серйозностіERRORта вище.
Оскільки для LogRecord та його повідомлень визначено рівень INFO, то результат записується до Handler 1 (зелена стрілка), а не в stderr Handler 2 (червона стрілка). Для обробників процес запису LogRecord в певний потік називається випускання (emitting), що видно з назви методу .emit().
Продовжимо аналізувати код.
Клас LogRecord
Екземпляр класу LogRecord є саме тим об'єктом, який ви логуєте. Він створюється автоматично об'єктом Logger та інкапсулює інформацію про подію. Внутрішньо він є обгорткою над dict, що містить атрибути для запису. Екземпляр Logger відправляє LogRecord обробникам.
LogRecord містить метадані, серед яких:
- назва;
- час створення за UNIX-форматом;
- повідомлення;
- інформація про функцію, яка викликає запис логів.
Оглянемо, як це все відбувається в коді, викликавши logging.error() з pdb module:
>>> import logging
>>> import pdb
>>> def f(x):
... logging.error("bad vibes")
... return x / 0
...
>>> pdb.run("f(1)")
Пройшовшись деякими функціями вищого рівня, ви опинитесь на 1517-ому рядку:
(Pdb) l
1514 exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
1515 elif not isinstance(exc_info, tuple):
1516 exc_info = sys.exc_info()
1517 record = self.makeRecord(self.name, level, fn, lno, msg, args,
1518 exc_info, func, extra, sinfo)
1519 -> self.handle(record)
1520
1521 def handle(self, record):
1522 """
1523 Call the handlers for the specified record.
1524
(Pdb) from pprint import pprint
(Pdb) pprint(vars(record))
{'args': (),
'created': 1550671851.660067,
'exc_info': None,
'exc_text': None,
'filename': '<stdin>',
'funcName': 'f',
'levelname': 'ERROR',
'levelno': 40,
'lineno': 2,
'module': '<stdin>',
'msecs': 660.067081451416,
'msg': 'bad vibes',
'name': 'root',
'pathname': '<stdin>',
'process': 2360,
'processName': 'MainProcess',
'relativeCreated': 295145.5490589142,
'stack_info': None,
'thread': 4372293056,
'threadName': 'MainThread'}
Вам рідко доведеться мати праву з LogRecord напряму, оскільки Logger та Handler все зроблять за вас. Однак варто знати про вміст LogRecord, оскільки тут саме та корисна інформація (як от дата та час), яку ви бачите в повідомленні.
Помітьте: нижче класу LogRecord ви також знайдете фабричні функції setLogRecordFactory(), getLogRecordFactory() та makeLogRecord(). Вони не знадобляться вам, допоки ви не вирішите використовувати замість LogRecord користувацький клас, щоб інкапсулювати повідомлення та їх метадані.
Класи Logger та Handler
Класи Logger та Handler відіграють основну роль в роботі logging і безпосередньо взаємодіють один з одним. Logger, Handler та LogRecord мають відповідний .level.
Logger приймає LogRecord та передає його далі в Handler, але лише якщо значення його рівня таке ж саме чи вище. Фільтрація на основі рівнів відбувається також між LogRecord та Handler. Однак Logger та Handler реалізують цей процес по-різному.
Іншими словами, перед тим як повідомлення логу кудись надішлеться, воно проходить (як мінімум) два кроки тестування. Щоб LogRecord пройшов від логера до обробника, а потім в певний потік (яким може бути sys.stdout, файл, або імейл через SMTP), він повинен мати рівень, як мінімум такий самий, як логер та обробник.
Що з цього приводу каже PEP 282:
Кожен об'єкт Logger відстежує рівень логів, які його цікавлять, а все, що нижче заданого рівня — відхиляється.
python.org/dev/peps/pep-0282/
Тож де насправді відбувається фільтрація рівнів для Logger та Handler?
Для класу Logger є підстави вважати, що логер порівнює свій атрибут .level з рівнем LogRecord. Однак все дещо заплутаніше.
Фільтрація рівнів для логерів відбувається в .isEnabledFor(), який натомість викликає .getEffectiveLevel(). Завжди використовуйте logger.getEffectiveLevel(), а не просто logger.level. Причина в організації об'єктів Logger в ієрархічному просторі імен (детальніше про це далі).
За замовчуванням екземпляр Logger має рівень 0 (NOTSET). Однак логери також мають батьків, один з яких є кореневим логером (батьківським для всіх інших логерів). Logger піднімається своєю ієрархією та отримує рівень відносно батьківського логера (який в кінцевому може бути root, якщо інших батьківських логерів не знайдено).
Розглянемо, де саме відбувається фільтрація в класі Logger:
class Logger(Filterer):
# ...
def getEffectiveLevel(self):
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
try:
return self._cache[level]
except KeyError:
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
Ось наведений код у дії:
>>> import logging
>>> logger = logging.getLogger("app")
>>> logger.level # No!
0
>>> logger.getEffectiveLevel()
30
>>> logger.parent
<RootLogger root (WARNING)>
>>> logger.parent.level
30
Пам'ятайте, що не варто покладатися на .level. Якщо ви не встановили .level для свого об'єкта logger і з якоїсь причини звертаєтесь до атрибута, то поведінка логування може стати неочікуваною.
Як щодо Handler? В обробниках порівняння рівнів відбувається простіше, однак воно відбувається в .callHandlers() з класу Logger.
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
В екземплярі LogRecord (record в сирцевому коді вище) логер порівнює атрибут .level з обробниками. Тільки якщо .levelno в LogRecord більше або дорівнює тому ж атрибуту обробника, запис проходить перевірку. docstring в logging визначає такий процес як «умовне випускання визначеного логу».
Детальніше про Handlers
Найбільш важливий атрибут екземпляру підкласу Handler — .stream. Це кінцеве місце, куди записуються логи, тому його можна розглядати як своєрідний файл.
Розглянемо приклад з io.StringIO, вбудованим потоком (буфером) для вводу/виводу текстової інформації.
Спочатку визначаємо рівень DEBUG для екземпляра Logger. Можна побачити, що за замовчуванням він не має обробників:
>>> import io
>>> import logging
>>> logger = logging.getLogger("abc")
>>> logger.setLevel(logging.DEBUG)
>>> print(logger.handlers)
[]
Далі створюємо підклас logging.StreamHandle, щоб зробити виклик .flush() як no-op. Ми хотіли б очистити sys.stderr або sys.stdout, але не буфер в пам'яті в цьому випадку:
class IOHandler(logging.StreamHandler):
def flush(self):
pass # No-op
Тепер оголошуємо сам об'єкт буфера та визначаємо його як .stream для користувацького обробника з рівнем INFO, а потім приєднуємо обробник до логера:
>>> stream = io.StringIO()
>>> h = IOHandler(stream)
>>> h.setLevel(logging.INFO)
>>> logger.addHandler(h)
>>> logger.debug("extraneous info")
>>> logger.warning("you've been warned")
>>> logger.critical("SOS")
>>> try:
... print(stream.getvalue())
... finally:
... stream.close()
...
you've been warned
SOS
Наведений фрагмент — чергова демонстрація фільтрації рівнів. Повідомлення з рівнями DEBUG, WARNING та CRITICAL передаються ланцюжком. Однак в результаті ми бачимо, що працюють лише два логера. Все тому, що обробник має рівень INFO, який переважає DEBUG. Зрештою ви отримуєте вміст буфера як str та звільнюєте системні ресурси.
Filter та Filterer класи
Вище ми вже намагалися розповісти, де відбувається фільтрація рівнів. Тут важко не відволіктись на класи Filter та Filterer. Як не дивно, але фільтрація рівнів в екземплярах Logger та Handler відбувається без допомоги зазначених класів.
Filter та Filterer створені, щоб ви могли приєднати додаткові функціональні фільтри до фільтрації за замовчуванням.
Filterer є базовим класом для Logger та Handler, які можуть приймати додаткові користувацькі фільтри. Ви створюєте екземпляри Filter, викликаючи logger.addFilter() або handler.addFilter(), на які посилається self.filters:
class Filterer(object):
# ...
def filter(self, record):
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record)
if not result:
rv = False
break
return rv
Для заданого record (тобто екземпляру LogRecord) .filter() повертає True або False.
Розглянемо функцію .handle() для класів Logger та Handler:
class Logger(Filterer):
# ...
def handle(self, record):
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
# ...
class Handler(Filterer):
# ...
def handle(self, record):
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
Ані Logger, ані Handler за замовчуванням не мають додаткових фільтрів, тому розглянемо, як можна їх швидко додати:
>>> import logging
>>> logger = logging.getLogger("rp")
>>> logger.setLevel(logging.INFO)
>>> logger.addHandler(logging.StreamHandler())
>>> logger.filters # Початково пустий
[]
>>> class ShortMsgFilter(logging.Filter):
... """Only allow records that contain long messages (> 25 chars)."""
... def filter(self, record):
... msg = record.msg
... if isinstance(msg, str):
... return len(msg) > 25
... return False
...
>>> logger.addFilter(ShortMsgFilter())
>>> logger.filters
[<__main__.ShortMsgFilter object at 0x10c28b208>]
>>> logger.info("Reeeeaaaaallllllly long message") # Довжина: 31
Reeeeaaaaallllllly long message
>>> logger.info("Done") # Довжина: <25, немає виводу
Вище ми визначили клас ShortMsgFilter та перевизначили його метод .filter(). В .addHandler() ми також можемо передати функцію чи лямбду або клас, що визначає .__call__().
Клас Manager
Поза увагою залишився ще один учасник logging, на якого варто звернути увагу: клас Manager. Та нас турбує не стільки сам клас, скільки його єдиний екземпляр, який є контейнером для зростаючої ієрархії логерів, визначених у всьому пакеті.
Далі ви побачите, як єдиний екземпляр цього класу відіграє основну роль в об'єднанні модулів для взаємодії різних частин коду.
Найважливіший root-логер
Коли справа доходить до екземплярів Logger, з-поміж інших виокремлюється один — root-логер:
class RootLogger(Logger):
def __init__(self, level):
Logger.__init__(self, "root", level)
# ...
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
Зверніть особливу увагу на останні три рядки коду. Тут треба помітити кілька моментів.
- root-логер — звичайний об'єкт Python з ідентифікатором
root. Він має рівеньlogging.WARNINGта атрибут.nameзі значенням root. Щодо класуRootLogger, то з особливого в нього лише назва. - об'єкт
rootнатомість стає атрибутом класу дляLogger. Маємо справу з шаблоном, схожим на «Одинака» (Singleton); - екземпляр класу
Managerвстановлюється як атрибут.managerдляLogger. При викликуlogging.getLogger("name"),.managerробить усе можливе, щоб знайти логери з назвою"name"і створює їх, якщо вони ще не існують.
Ієрархія Logger
В просторі імен логера всі логери будуть дочірніми відносно root: як ті, що ви визначаєте самостійно, так і ті, що є складниками імпортованих сторонніх бібліотек.
Раніше .getEffectiveLevel() для наших екземплярів logger повертав 30 (WARNING), навіть попри те, що ми не встановлювали рівень явно. Тепер ми розуміємо, що все це через кореневий логер на вершині ієрархії. Тобто його рівень встановлюється для всіх дочірніх логерів без визначеного рівня або зі значенням NOTSET:
>>> root = logging.getLogger() # Або getLogger("")
>>> root
<RootLogger root (WARNING)>
>>> root.parent is None
True
>>> root.root is root # Перевірка самого себе
True
>>> root is logging.root
True
>>> root.getEffectiveLevel()
30
Така ж логіка з пошуком обробників логера. Фактично він відбувається у зворотному порядку деревом логерів.
Структура з декількома обробниками
В теорії ієрархія логерів чітка і акуратна, але яка користь від цього на практиці?
Зробимо перерву у вивченні сирцевого коду logging та спробуймо написати власний мінізастосунок, який використає усі переваги ієрархії логерів, зменшить кількість шаблонного коду та забезпечить масштабованість проекту.
Структура проекту матиме такий вигляд:
project/
│
└── project/
├── __init__.py
├── utils.py
└── base.py
Не звертайте увагу на основні функції застосунку в utils.py та base.py. Тут ми приділимо основну увагу взаємодії об'єктів logging між модулями в project/.
Припустімо, ви хочете спроектувати комплексне логування, тоді:
- Кожен модуль отримує
loggerз декількома обробниками; - Деякі обробники поширюються між екземплярами
loggerз різних модулів. Вони займаються лише фільтрацією рівнів, тому не важливо, де знаходиться запис. Маємо обробник для повідомлень рівняDEBUG,INFO,WARNINGі так далі. - Кожен логер також приєднаний до одного додаткового обробника, який лише отримує екземпляри
LogRecord. Можна вважати його модульним файловим обробником.
Отримаємо таку картину:
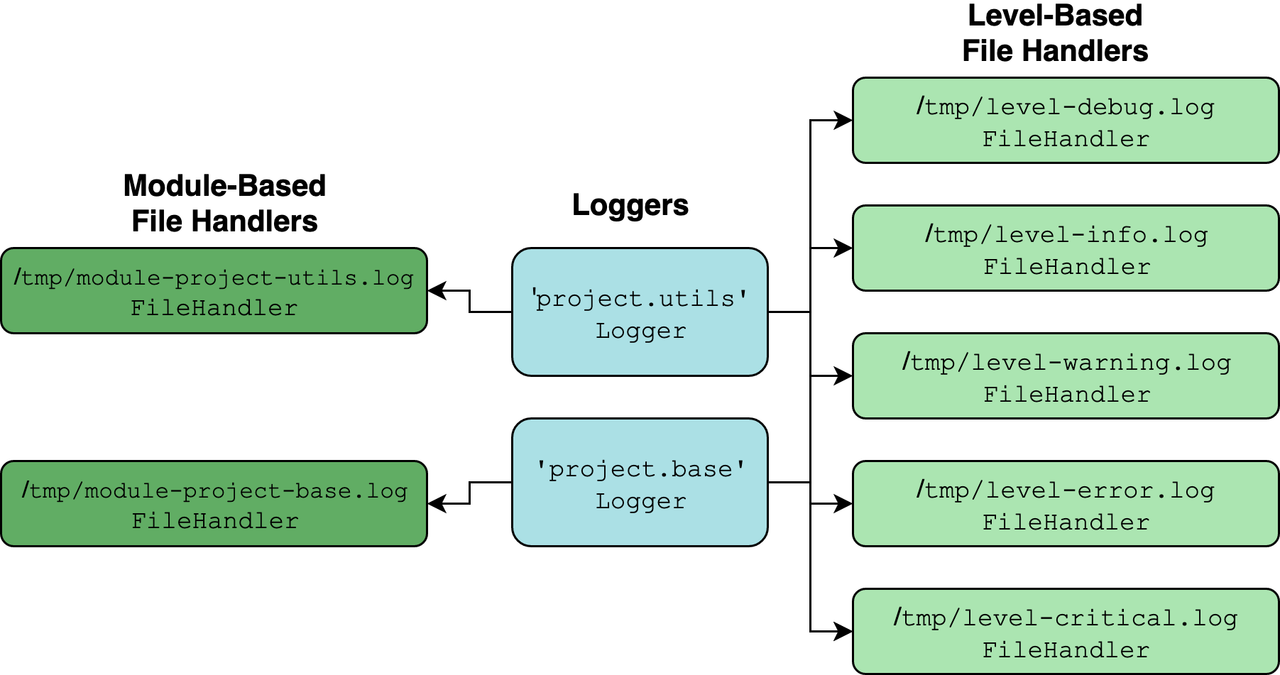
В блакитних прямокутниках бачимо екземпляри Logger, створені для кожного модуля в пакеті за допомогою logging.getLogger(__name__). Все інше — екземпляри Handler.
Основна перевага такої структури в тому, що вона добре розмежована. Зручно спостерігати за повідомленнями певного рівня та вище з будь-якого логера чи модуля. Все завдяки ієрархії логерів. Що це може означати? Звернемося до документації Django.
Можна налаштувати логери так, що виклики спливатимуть до їх батьків. В такому разу ви можете визначити простий набір обробників в корені дерева логерів та перехоплювати усі виклики в піддереві логерів. Обробник, визначений в просторі імен project відловить усі повідомлення, направлені логерам project.interesting та project.interesting.stuff.
docs.djangoproject.com
Термін спливання (propagation) означає процес підняття логера вверх ланцюжком батьків у пошуках обробника. Атрибут .propagate встановлюється як True для екземпляра Logger за замовчуванням:
>>> logger = logging.getLogger(__name__)
>>> logger.propagate
True
У наведеному нижче фрагменті коду, якщо в .callHandlers() значення propagate отримує True, кожен наступний батьківський елемент повторно присвоюється локальній змінній c, поки ієрархія не завершиться:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None
else:
c = c.parent
Оскільки dunder-змінна __name__ всередині модуля __init__.py приймає значення назви пакету, наш логер стає батьківським для будь-яких логерів з інших модулів одного пакету.
Подивимось, які значення прийматиме атрибут .name після виклику logging.getLogger(__name__):
| Модуль | Значення .name |
|---|---|
project/__init__.py |
project |
project/utils.py |
project.utils |
project/base.py |
project.base |
Оскільки логери project.utils та project.base є дочірніми для project, вони охоплюватимуть не лише власні, але будь-які обробники, приєднані до project.
Зосередимося на модулях. Першим оглянемо __init__.py:
# __init__.py
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
levels = ("DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL")
for level in levels:
handler = logging.FileHandler(f"/tmp/level-{level.lower()}.log")
handler.setLevel(getattr(logging, level))
logger.addHandler(handler)
def add_module_handler(logger, level=logging.DEBUG):
handler = logging.FileHandler(
f"/tmp/module-{logger.name.replace('.', '-')}.log"
)
handler.setLevel(level)
logger.addHandler(handler)
Він імпортується разом з project. Додаємо обробник для рівнів від DEBUG до CRITICAL, потім приєднуємо його до логера на вершині ієрархії.
Визначаємо також допоміжну функцію, яка додає ще FileHandler для логера. Значення filename обробника відповідає назві модуля, де знаходиться логер (тут передбачається, що логер створюється з __name__).
Далі можна додати трохи шаблонного коду для налаштувань в base.py та utils.py. Вам необхідно додати один додатковий обробник, використовуючи add_module_handler() з __init__.py. Тож не варто турбуватися щодо обробників, які орієнтовані на рівні, оскільки вони вже місяться в батьківському логері під назвою project.
# base.py
import logging
from project import add_module_handler
logger = logging.getLogger(__name__)
add_module_handler(logger)
def func1():
logger.debug("debug called from base.func1()")
logger.critical("critical called from base.func1()")
utils.py:
utils.py
import logging
from project import add_module_handler
logger = logging.getLogger(__name__)
add_module_handler(logger)
def func2():
logger.debug("debug called from utils.func2()")
logger.critical("critical called from utils.func2()")
Подивимось, як усе працює разом у свіжій сесії:
>>> from pprint import pprint
>>> import project
>>> from project import base, utils
>>> project.logger
<Logger project (DEBUG)>
>>> base.logger, utils.logger
(<Logger project.base (DEBUG)>, <Logger project.utils (DEBUG)>)
>>> base.logger.handlers
[<FileHandler /tmp/module-project-base.log (DEBUG)>]
>>> pprint(base.logger.parent.handlers)
[<FileHandler /tmp/level-debug.log (DEBUG)>,
<FileHandler /tmp/level-info.log (INFO)>,
<FileHandler /tmp/level-warning.log (WARNING)>,
<FileHandler /tmp/level-error.log (ERROR)>,
<FileHandler /tmp/level-critical.log (CRITICAL)>]
>>> base.func1()
>>> utils.func2()
В кінцевих файлах з логами бачимо, що фільтрація працює як треба. Модульні обробники направляють логер в певний файл, натомість обробники рівнів направляють декілька логерів в різні файли:
$ cat /tmp/level-debug.log
debug called from base.func1()
critical called from base.func1()
debug called from utils.func2()
critical called from utils.func2()
$ cat /tmp/level-critical.log
critical called from base.func1()
critical called from utils.func2()
$ cat /tmp/module-project-base.log
debug called from base.func1()
critical called from base.func1()
$ cat /tmp/module-project-utils.log
debug called from utils.func2()
critical called from utils.func2()
Не обійтися без недоліків: подібний код досить перевантажений. Один екземпляр LogRecord може опинитися не менш як в шести файлах. В застосунку, де критично важлива продуктивність, така кількість операцій вводу/виводу в файл може бути дуже суттєвою.
Ми ознайомились з практичним прикладом, тому перейдемо до можливих неясностей з logging.
Чому лог зникає
Є дві набільш поширені проблеми з logging:
- Ваше повідомлення кудись зникло.
- Ваше повідомлення опинилося в неочікуваному місці.
Оглянемо причини кожної проблеми детальніше.
1. Ваше повідомлення кудись зникло
Не забувайте, що фактичний рівень логера, для якого ви не визначили рівень — WARNING, тобто рівень root-логера за замовчуванням:
>>> import logging
>>> logger = logging.getLogger("xyz")
>>> logger.debug("mind numbing info here")
>>> logger.critical("storm is coming")
storm is coming
Враховуючи це, не дивно, що виклик .debug() не дає результату.
2. Ваше повідомлення опинилося в неочікуваному місці
Вище ми оголосили logger, проте не додали до нього жодних обробників. Як тоді ми бачимо результат в консолі?
Причина в тому, що logging за замовчуванням використовує обробник lastResort, який пише в sys.stderr, якщо жодних обробників більше не знайдено.
class _StderrHandler(StreamHandler):
# ...
@property
def stream(self):
return sys.stderr
_defaultLastResort = _StderrHandler(WARNING)
lastResort = _defaultLastResort
Його можна побачити у дії при пошуку логером своїх обробників:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
Якщо ж логер оминає цей етап, він отримує як обробника lastResort.
Варто звернути увагу на ще одну тонку деталь. Вище ми здебільшого мали справу з методами екземплярів (тобто тими, що визначаються в класах), а не функціями рівня модуля пакету logging.
Функції logging.info() та logger.info() відрізняються внутрішньою реалізацію, тому на це варто звернути увагу при їх виборі. Перша функція викликає logging.basicConfig(), що додає StreamHandler, який пише в sys.stderr. Зрештою поведінка буде однаковою:
>>> import logging
>>> root = logging.getLogger("")
>>> root.handlers
[]
>>> root.hasHandlers()
False
>>> logging.basicConfig()
>>> root.handlers
[<StreamHandler <stderr> (NOTSET)>]
>>> root.hasHandlers()
True
Отримуємо переваги від лінивого форматування
Час розглянути детальніше, як саме повідомлення пов'язуються з їхніми даними. Скоріш за все, до появи str.format() та f-string ви використовували такий стиль форматування:
>>> print("To iterate is %s, to recurse %s" % ("human", "divine"))
To iterate is human, to recurse divine
І у вас може виникнути бажання зробити те ж саме в logging:
>>> # Погано! Спробуйте більш ефективну альтернативну нижче.
>>> logging.warning("To iterate is %s, to recurse %s" % ("human", "divine"))
WARNING:root:To iterate is human, to recurse divine
Тут використовується рядок з аргументами як msg для logging.warning().
Рекомендована альтернатива — з документації logging.
>>> # Краще: форматування не відбувається без потреби.
>>> logging.warning("To iterate is %s, to recurse %s", "human", "divine")
WARNING:root:To iterate is human, to recurse divine
Так ми порушуємо угоду про стиль форматування з відсотками, але отримуємо більш ефективний варіант, оскільки рядок форматується ліниво, а не в жадібний спосіб. Розглянемо, що це означає.
Сигнатура метода для Logger.warning() має такий вигляд:
def warning(self, msg, *args, **kwargs)
Те ж саме стосується інших методів, як от .debug(). Коли ви викликаєте warning("To iterate is %s, to recurse %s", "human", "divine"), значення "human" та "divine" сприймаються як *args, а всередині області видимості методу args еквівалентно ("human", "divine").
Порівняємо з першим варіантом:
logging.warning("To iterate is %s, to recurse %s" % ("human", "divine"))
З таким варіантом всі параметри в дужках займають відповідні місця і ми отримуємо рядок "To iterate is human, to recurse divine", який потім передаємо як msg, а кортеж args залишиться пустим.
Чому це так важливо? Пакет logging робить все, аби не знизити продуктивність застосунку. Якщо ви не будете одразу об'єднувати рядок з відповідними аргументами, logging відстрочить форматування рядка, допоки Handler не захоче отримати LogRecord. Все описане відбувається в LogRecord.getMessage().
Тож можна помітити, як logging робить усі можливі оптимізації для покращення продуктивності. Вам може здатися це дрібницями, однак якщо ви робите той самий виклик logging.debug() мільйон разів в циклі, а args представляє виклики функцій, тоді ліниве форматування повідомлень дійсно має ефект.
Перед тим як робити будь-які об'єднання msg та args, екземпляр Logger викличе .isEnabledFor(), щоб переконатися, що це слід робити в першу чергу.
Функції vs Методи
Наприкінці logging/__init__.py є функції рівня модуля, найбільш значущі для публічного API logging. Ви вже неодноразово мали справу методами .debug(), .info() та .warning(). Функції верхнього рівня є обгортками навколо відповідних методів, але мають дві важливі особливості:
- Вони завжди викликають відповідний метод з root-логера.
- Перед викликом методів root-логера, вони викликають
logging.basicConfig()без аргументів, якщо вrootнемає обробників. Як ми бачили раніше, завдяки такому викликуsys.stdoutвстановлюється як обробник для root-логера.
Продемонструємо все на logging.error():
def error(msg, *args, **kwargs):
if len(root.handlers) == 0:
basicConfig()
root.error(msg, *args, **kwargs)
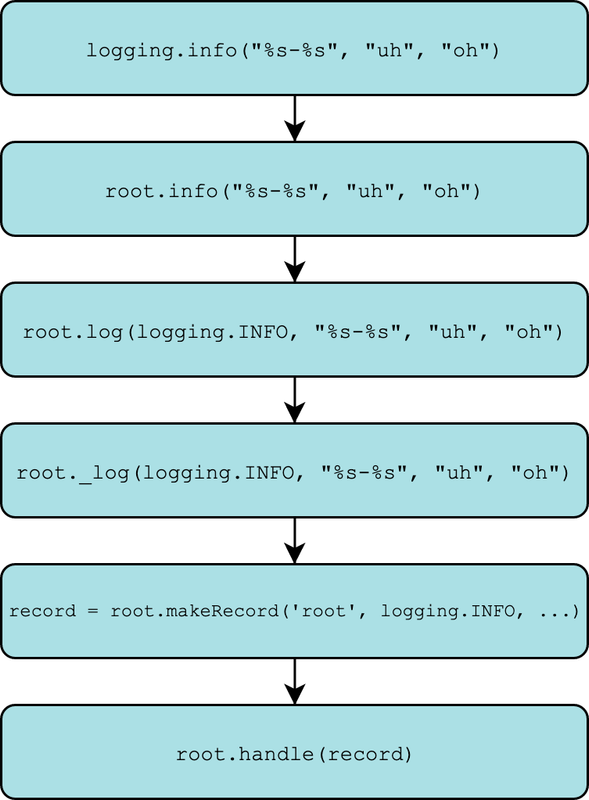
Те ж саме працює і для методів logging.debug(), logging.info() тощо. Якщо ви відстежите ланцюжок викликів команд, то опинитесь на моменті виклику Logger._log(). Тут є дві мети:
- Виклик
self.makeRecord(): створює екземплярLogRecordзmsgта інших переданих аргументів. - Виклик
self.handle(): визначає безпосередньо дії з записом. Що відбувається далі?
Все описує ця діаграма:
Ви також можете отримати стек-трейс, викликавши pdb. Продемонструємо на виклику logging.warning():
>>> import logging
>>> import pdb
>>> pdb.run('logging.warning("%s-%s", "uh", "oh")')
> <string>(1)<module>()
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1971)warning()
-> def warning(msg, *args, **kwargs):
(Pdb) s
> lib/python3.7/logging/__init__.py(1977)warning()
-> if len(root.handlers) == 0:
(Pdb) unt
> lib/python3.7/logging/__init__.py(1978)warning()
-> basicConfig()
(Pdb) unt
> lib/python3.7/logging/__init__.py(1979)warning()
-> root.warning(msg, *args, **kwargs)
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1385)warning()
-> def warning(self, msg, *args, **kwargs):
(Pdb) l
1380 logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
1381 """
1382 if self.isEnabledFor(INFO):
1383 self._log(INFO, msg, args, **kwargs)
1384
1385 -> def warning(self, msg, *args, **kwargs):
1386 """
1387 Log 'msg % args' with severity 'WARNING'.
1388
1389 To pass exception information, use the keyword argument exc_info with
1390 a true value, e.g.
(Pdb) s
> lib/python3.7/logging/__init__.py(1394)warning()
-> if self.isEnabledFor(WARNING):
(Pdb) unt
> lib/python3.7/logging/__init__.py(1395)warning()
-> self._log(WARNING, msg, args, **kwargs)
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1496)_log()
-> def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
(Pdb) s
> lib/python3.7/logging/__init__.py(1501)_log()
-> sinfo = None
(Pdb) unt 1517
> lib/python3.7/logging/__init__.py(1517)_log()
-> record = self.makeRecord(self.name, level, fn, lno, msg, args,
(Pdb) s
> lib/python3.7/logging/__init__.py(1518)_log()
-> exc_info, func, extra, sinfo)
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1481)makeRecord()
-> def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
(Pdb) p name
'root'
(Pdb) p level
30
(Pdb) p msg
'%s-%s'
(Pdb) p args
('uh', 'oh')
(Pdb) up
> lib/python3.7/logging/__init__.py(1518)_log()
-> exc_info, func, extra, sinfo)
(Pdb) unt
> lib/python3.7/logging/__init__.py(1519)_log()
-> self.handle(record)
(Pdb) n
WARNING:root:uh-oh
Розбираємось з getLogger()
Перейдемо до детального ознайомлення з іншою функцією верхнього рівня — getLogger(), яка огортає Logger.manager.getLogger():
def getLogger(name=None):
if name:
return Logger.manager.getLogger(name)
else:
return root
Саме тут ми натрапляємо на шаблон проектування «Одинак»:
- Якщо ви визначаєте
name,.getLogger()здійснює пошук цього значення вdict. Усе зводиться до пошукуlogging.ManagerвloggerDict, словнику з усіма зареєстрованими логерами, що містять також проміжні екземпляриPlaceHolder. Вони генеруються, коли ви посилаєтесь на логер в глибокій ієрархії. - В іншому випадку повертається
root, екземпляр вже згаданогоRootLogger.
Саме за допомогою такої фічі можна оглянути усі зареєстровані логери:
>>> import logging
>>> logging.Logger.manager.loggerDict
{}
>>> from pprint import pprint
>>> import asyncio
>>> pprint(logging.Logger.manager.loggerDict)
{'asyncio': <Logger asyncio (WARNING)>,
'concurrent': <logging.PlaceHolder object at 0x10d153710>,
'concurrent.futures': <Logger concurrent.futures (WARNING)>}
Що тут насправді відбувається? Здається, ніби з пакетом logging відбулись якісь внутрішні зміни як результат імпорту іншої бібліотеки. Саме так і є.
Спершу пригадаймо, що Logger.manager є атрибутом класу, де екземпляр Manager з'єднаний з класом Logger. manager створений для відстеження та управління всіма екземплярами Logger, розміщеними всередині .loggerDict. Коли ви вперше імпортуєте logging, цей словник пустий. Але після імпорту asyncio, словник наповнюється трьома логерами. Маємо приклад того, як один модуль встановлює атрибути іншого. Всередині asyncio/log.py знайдемо такий вміст:
import logging
logger = logging.getLogger(__package__) # "asyncio"
Пара ключ-значення встановлюється всередині Logger.getLogger(), тому manager може оглянути повний простір імен логерів. Тобто об'єкт asyncio.log.logger реєструється в словнику логерів, який належить пакету logging. Щось подібне відбувається також в пакеті concurrent.futures, який імпортується aasyncio.
Усю потужність патерну «Одинак» в нашому випадку демонструє така перевірка:
>>> obj1 = logging.getLogger("asyncio")
>>> obj2 = logging.Logger.manager.loggerDict["asyncio"]
>>> obj1 is obj2
True
Тепер справді зрозуміло, що робить getLogger().
Детальніше про NullHandler
Ось ми і перейшли до кінцевих рядків коду з logging/__init__.py, де визначено NullHandler:
class NullHandler(Handler):
def handle(self, record):
pass
def emit(self, record):
pass
def createLock(self):
self.lock = None
NullHandler якраз і демонструє відмінності між логуванням в бібліотеці vs застосунку. Оглянемо, що це насправді означає.
Бібліотека — розширюваний, широко застосовний пакет Python, призначений для встановлення та налаштування іншими користувачами. Серед популярних проектів з відкритим сирцевим кодом — NumPy, dateutil, cryptography.
Застосунок, натомість, призначений для більш конкретної мети та вузького кола користувачів (можливо, лише одного). Популярний приклад — застосунки з бекендом на Django. Застосунки, як правило, використовують (імпортують) бібліотеки та інструменти.
Коли справа доходить до логування, використовуються різні трюки для бібліотек та застосунків. Тут на допомогу приходить NullHandler. По суті, це звичайний клас-заглушка.
Якщо ви створюєте бібліотеку на Python, вам треба зробити таке невеличке налаштування у файлі __init__.py вашого пакету:
# Помістіть наступний код у верхню частину `__init__.py`
# І більше нічого!
import logging
logging.getLogger(__name__).addHandler(NullHandler())
Для чого нам таке налаштування?
По-перше, бібліотечний логер, оголошений як logger = logging.getLogger(__name__) (без будь-якої подальшої конфігурації) буде писати логи в sys.stderr за замовчуванням, навіть якщо це не зовсім те, чого хотів кінцевий користувач. Тобто кінцевому користувачеві бібліотеки треба самостійно відімкнути логування в консоль, якщо він цього не хоче.
Зручніше було б, якби користувач бібліотеки самостійно визначав, чи потрібні йому логери, та проводив налаштування. З цього приводу автор пакету logging, Vinay Sajip, сказав:
Сторонні бібліотеки, що використовують logging, не повинні за замовчуванням вести логи, оскільки це може суперечити бажанням розробника.
wiki.python.org
Тобто не розробник бібліотеки, а її кінцевий користувач повинен викликати методи на зразок logger..addHandler() чи logger.setLevel().
По-друге, якщо ви спробуєте логувати LogRecord з логера без встановленого обробника у версіях Python 2.7 та більш ранніх, виникне попередження. Щоб запобігти цьому, використовується NullHandler.
Ось що конкретно відбувається на цьому рядку logging.getLogger(__name__).addHandler(NullHandler()) з фрагмента вище:
- Python отримує (створює) екземпляр
Loggerз назвою, що збігається з вашим пакетом. Якщо ви працюєте з пакетомcalculus, то в межах__init__.py,__name__прийме значенняcalculus. - Екземпляр
NullHandlerприєднується до цього логера. Тобто Python не буде використовувати за замовчуваннямlastResort.
Пам'ятайте, оскільки будь-який логер, створений в .py-модулях пакету буде дочірнім до згаданого логера і отримає його обробник, він не буде використовувати обробник lastResort чи виводити логи в stderr.
Для швидкого прикладу уявімо, що ваша бібліотека має таку структуру:
calculus/
│
├── __init__.py
└── integration.py
У файлі integration.py як розробник бібліотеки ви можете зробити наступне:
# calculus/integration.py
import logging
logger = logging.getLogger(__name__)
def func(x):
logger.warning("Look!")
# Інший код
return None
Тепер користувачі можуть встановити вашу бібліотеку з PyPI командою pip install calculus. В коді застосунку вони використовуватимуть from calculus.integration import func і зможуть вільно налаштовувати об'єкт logger, як будь-який інший об'єкт Python.
Особливості винятків у logging
Якщо у вас є виклик logging.error(), призначений для інформації при налагодженні, але з якоїсь причини він видає виняток, це стає досить іронічним.
Якщо в пакеті logging з'являється виняток, пов'язаний з самим процесом логування, виведеться стек-трейс, але не сам виняток.
Приклад з поширеною помилкою: передаємо два аргументи в logging.error() для форматування рядка, який очікує лише один аргумент. Важлива відмінність в тому, що нижче ми спостерігаємо не виняток, а, скоріше, прикрашений стек-трейс внутрішнього винятку, який було самостійно усунено:
>>> logging.critical("This %s has too many arguments", "msg", "other")
--- Logging error ---
Traceback (most recent call last):
File "lib/python3.7/logging/__init__.py", line 1034, in emit
msg = self.format(record)
File "lib/python3.7/logging/__init__.py", line 880, in format
return fmt.format(record)
File "lib/python3.7/logging/__init__.py", line 619, in format
record.message = record.getMessage()
File "lib/python3.7/logging/__init__.py", line 380, in getMessage
msg = msg % self.args
TypeError: not all arguments converted during string formatting
Call stack:
File "<stdin>", line 1, in <module>
Message: 'This %s has too many arguments'
Arguments: ('msg', 'other')
Так ваша програма зможе продовжити нормальну роботу. Логічно, що ви не хочете отримати необроблений виняток з logging та зупиняти через це виконання основного застосунку.
Стек-трейси можуть бути достатньо заплутаними, однак не в нашому випадку. Винятки усуваються за допомогою методу Handler.handleError(). Коли обробник викликає .emit(), метод, що намагається записати лог, то .handleError() викликається, якщо щось пішло не так. Реалізація .emit() для класу StreamHandler:
def emit(self, record):
try:
msg = self.format(record)
stream = self.stream
stream.write(msg + self.terminator)
self.flush()
except Exception:
self.handleError(record)
Будь-який виняток, що стосується форматування та запису логів, перехоплюється, а handleError записує стек-трейс в sys.stderr.
Трейсбеки в Python Logging
Продовжимо тему винятків. Як щодо випадків, коли ваша програма натрапляє на них, однак має записати лог винятку та продовжувати виконання?
Ось декілька способів це зробити.
Уявімо, що ви займаєтесь розробкою онлайн-лотереї, де користувач може робити ставку на число:
import random
class Lottery(object):
def __init__(self, n):
self.n = n
def make_tickets(self):
for i in range(self.n):
yield i
def draw(self):
pool = self.make_tickets()
random.shuffle(pool)
return next(pool)
Ви повинні переконатись, що відстежуєте будь-які помилки, які виникають у фронтенді. Перший і не найкращий спосіб — використовувати logging.error() та логувати str безпосередньо з екземпляра винятку:
try:
lucky_number = int(input("Enter your ticket number: "))
drawn = Lottery(n=20).draw()
if lucky_number == drawn:
print("Winner chicken dinner!")
except Exception as e:
# NOTE: Нижче є кращий спосіб це зробити
logging.error("Could not draw ticket: %s", e)
Так ви лише отримаєте фактичне повідомлення про виняток, але не трейсбек. Ви перевіряєте логи на сервері вашого веб-сайту та знаходите таке критичне повідомлення:
ERROR:root:Could not draw ticket: object of type 'generator' has no len()
Як розробник застосунку ви отримали серйозну проблему, а ваш користувач — збитки. Але сам виняток не дуже інформативний. Було б непогано побачити трейсбек, що призвів до нього.
Правильно буде використовувати logging.exception(), щоб логувати повідомлення з рівнем ERROR, а також трейсбек винятку. Замініть останні два рядки вище таким кодом:
except Exception:
logging.exception("Could not draw ticket")
Тепер ви будете більше проінформовані про зміст винятку:
ERROR:root:Could not draw ticket
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
File "<stdin>", line 9, in draw
File "lib/python3.7/random.py", line 275, in shuffle
for i in reversed(range(1, len(x))):
TypeError: object of type 'generator' has no len()
Використання exception() позбавляє вас потреби посилатися на виняток самостійно, оскільки logging отримує всю необхідну інформацію за допомогою sys.exc_info().
Тепер нам зрозуміло, що проблема виникла в методі random.shuffle(), який повен знати розмір об'єктів, який він перетасовує. Оскільки наш клас Lottery передає генератор в shuffle(), виняток виникає до того, як число може бути перетасоване.
Для більш масштабних застосунків вдалим вибором буде logging.exception() для трейсбеків з декількох бібліотек, з якими не можна працювати за допомогою дебагера на зразок pdb.
Код для logging.Logger.exception(), а отже і logging.exception() займає всього один рядок.
def exception(self, msg, *args, exc_info=True, **kwargs):
self.error(msg, *args, exc_info=exc_info, **kwargs)
Тобто logging.exception() викликає logging.error() зі значенням exc_info=True (яке за замовчуванням False). Якщо ви хочете логувати трейсбек винятку з рівнем, відмінним від logging.ERROR, просто викличте функцію зі значенням exc_info=True.
Пам'ятайте, що exception() слід викликати лише в контексті обробника винятків, всередині блоку except:
for i in data:
try:
result = my_longwinded_nested_function(i)
except ValueError:
# Зараз ми знаходимось в контексті обробника
# Якщо точно незрозуміло чому ми не могли обробити
# `i`, виведіть лог трейсбеку і продовжувати виконання
logger.exception("Could not process %s", i)
continue
Проте не варто зловживати таким способом. Він найбільш корисний, якщо ви налагоджуєте велику функцію з незрозумілою, важкодосяжною помилкою.
Висновок
Якщо ви протримались до кінця, можете пишатися собою, адже ви щойно ознайомились майже з 2000 рядків сирцевого коду. Тепер ви добре озброєні, аби працювати з пакетом logging.
Однак цей посібник не був вичерпним — у logging є ще багато корисних класів. Якщо ви хочете ще ретельніше ознайомитись з пакетом, огляньте класи Farmatter й окремі модулі logging/config.py та logging/handlers.py.

Ще немає коментарів