
Ласкаво просимо в майбутнє пошуку музичної інформації, де машинне навчання, векторні бази даних і аналіз аудіоданих об'єднуються, щоб забезпечити нові захопливі можливості! Якщо ви цікавитеся світом аналізу музичних даних або просто захоплюєтеся тим, як технології революціонізують музичну індустрію, цей посібник для вас.
Тут ми розповімо вам про пошук музичних даних за допомогою підходу, відомого як векторний пошук. Оскільки понад 80% даних у світі неструктуровані, корисно знати, як поводитися з різними типами даних, окрім тексту.
Якщо ви хочете стежити за кодом і виконувати його під час читання, отримайте доступ до файлу на GitHub, вказаного в кінці цієї статті.
Архітектура
Уявіть, що ви наспівуєте мелодію пісні, яку намагаєтеся згадати, і раптом на екрані з'являється пісня, яку ви наспівували? Саме це ми сьогодні й зробимо, доклавши певних зусиль та налаштувавши модель даних.
Щоб досягти нашого результату, ми створимо наступну архітектуру:
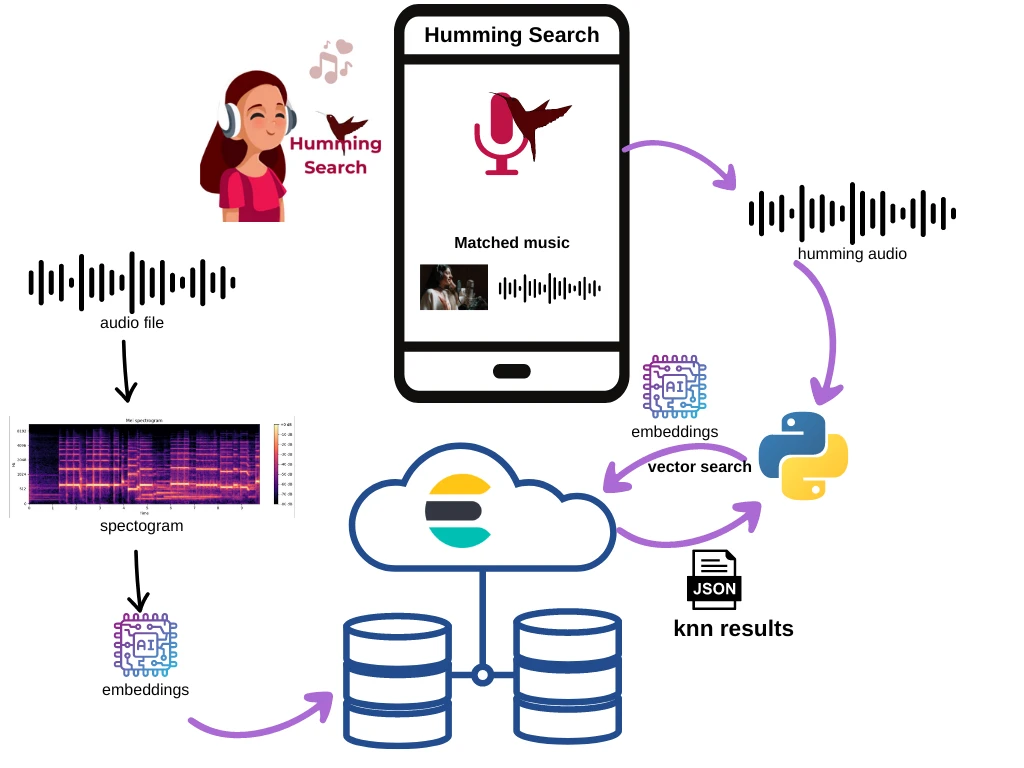
Головною дійовою особою тут є вбудовування. Ми будемо використовувати звукові вбудовування, згенеровані моделлю, як пошуковий ключ у нашому векторному пошуку.
Як створити звукове вбудовування
В основі створення вбудовувань лежать моделі, які навчаються на мільйонах прикладів, щоб надавати більш релевантні та точні результати. Для аудіо ці моделі можна навчати на великій кількості аудіоданих. Результатом роботи цих моделей є щільне числове представлення аудіо (тобто, аудіо вбудовування). Цей вектор високої розмірності фіксує ключові характеристики аудіокліпу, що дозволяє проводити обчислення подібності та ефективний пошук у вбудованому просторі.
Для генерації вбудовування ми будемо використовувати librosa (пакет з відкритим вихідним кодом на мові python). Зазвичай це передбачає вилучення значущих характеристик з аудіофайлів, таких як Mel-частотні цепстральні коефіцієнти (MFCC), кольоровість та особливості спектрограми в масштабі Mel. Отже, як ми можемо реалізувати аудіопошук за допомогою Elasticsearch?
Крок 1: Створення індексу для зберігання аудіоданих
Передусім перед тим, як заповнювати нашу векторну базу даних музичними даними, нам потрібно створити індекс в Elasticsearch.
- Почніть з розгортання Elasticsearch
- Під час цього процесу не забудьте зберегти облікові дані (ім'я користувача, пароль), які будуть використані в нашому Python-коді.
- Для простоти ми будемо використовувати код Python, запущений на Jupyter Notebook (Google Collab).
1.1 Створення індексу нашого набору аудіо даних
Тепер, коли у нас є з'єднання, створюємо індекс, в якому буде зберігатися аудіоінформація.
# Here we're defining the index configuration. We're setting up mappings for our index which determine the data types for the fields in our documents.
index_config = {
"mappings": {
"_source": {
"excludes": ["audio-embedding"]
},
"properties": {
"audio-embedding": {
"type": "dense_vector",
"dims": 2048,
"index": True,
"similarity": "cosine"
},
"path": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"timestamp": {
"type": "date"
},
"title": {
"type": "text"
}
}
}
}
# Index name for creating in Elasticsearch
index_name = "my-audio-index"
# Checking and creating the index
if not es.indices.exists(index=index_name):
index_creation = es.indices.create(index=index_name, ignore=400, body=index_config)
print("index created: ", index_creation)
else:
print("Index already exists.")
Наданий код на Python за допомогою Python-клієнта Elasticsearch створює індекс з заданими конфігураціями. Метою індексу є створення структури, яка дозволяє здійснювати пошукові операції у щільних векторних полях, які зазвичай використовуються для зберігання векторних представлень або вбудовувань деяких об'єктів (у цьому випадку - аудіофайлів).
Об'єкт index_config визначає властивості відображення цього індексу, включаючи поля audio-embedding, path, timestamp і title. Поле audio-embedding визначено як тип dense_vector, що відповідає розмірності 2048, та індексується за допомогою "косинусної" подібності, яка визначає метод, що використовується для обчислення відстані між векторами під час пошукових операцій. У полі "шлях" зберігатиметься шлях для відтворення аудіо. Зверніть увагу, що для вбудовування розмірності 2048 вам потрібно використовувати Elasticsearch версії 8.8.0 або новішої.
Потім скрипт перевіряє, чи існує індекс в екземплярі Elasticsearch. Якщо індексу не існує, він створює новий індекс із зазначеною конфігурацією. Цей тип конфігурації індексу можна використовувати в таких сценаріях, як пошук аудіофайлів, де аудіофайли перетворюються у векторне представлення для індексування і подальшого пошуку на основі схожості.
Крок 2: Наповнення Elasticsearch аудіо даними
Наприкінці цього кроку у вас буде індекс, який потрібно заповнити аудіоданими. Щоб ми могли продовжити аудіопошук, нам спочатку потрібно заповнити нашу базу даних.
2.1 Вибір аудіоданих для завантаження
Численні набори аудіоданих мають певні цілі. Для нашого прикладу я використаю файли, згенеровані на сторінці Google Music LM, а саме з розділу "Текст і мелодія". Помістіть ваші аудіофайли *.wav у певний каталог - у цьому випадку я обираю свій GoogleDrive /content/drive/MyDrive/audios.
import os
def list_audio_files(directory):
# The list to store the names of .mp3, .wav files
audio_files = []
# Check if the path exists
if os.path.exists(directory):
# Walk the directory
for root, dirs, files in os.walk(directory):
for file in files:
# Check if the file is a .wav file
if file.endswith('.wav'):
# Extract the filename from the path
filename = os.path.splitext(file)[0]
print(filename)
# Add the file to the list
audio_files.append(file)
else:
print(f"The directory '{directory}' does not exist.")
# Return the list of .mp3 files
return audio_files
# Use the function
audio_files = list_audio_files("/content/drive/MyDrive/audios")
У коді визначено функцію list_audio_files, яка отримує каталог як аргумент. Ця функція здійснює обхід вказаного каталогу та його підкаталогів у пошуках аудіофайлів з розширенням .wav. Функцію слід модифікувати, якщо ви бажаєте підтримувати файли .mp3.
2.2 Сила вбудовувань для векторного пошуку
На цьому кроці відбувається магія. Пошук за схожістю векторів - це механізм для зберігання, вилучення та пошуку векторів на основі їхньої схожості за запитом, який зазвичай використовується в таких програмах, як пошук зображень, обробка природної мови, рекомендаційні системи тощо. Ця концепція широко використовується завдяки розвитку глибокого навчання та представленню даних за допомогою вбудовувань. По суті, вбудовування - це векторне представлення багатовимірних даних.
Фундаментальна ідея полягає в тому, щоб представити елементи даних (наприклад, зображення, документи, профілі користувачів) у вигляді векторів у багатовимірному просторі. Потім подібність між векторами вимірюється за допомогою метрики відстані, наприклад, косинусної подібності або евклідової відстані, і найбільш схожі вектори повертаються як результати пошуку. У той час як текстові вставки витягуються за допомогою лінгвістичних ознак, аудіо вставки часто генеруються за допомогою спектрограм або інших ознак аудіосигналу.
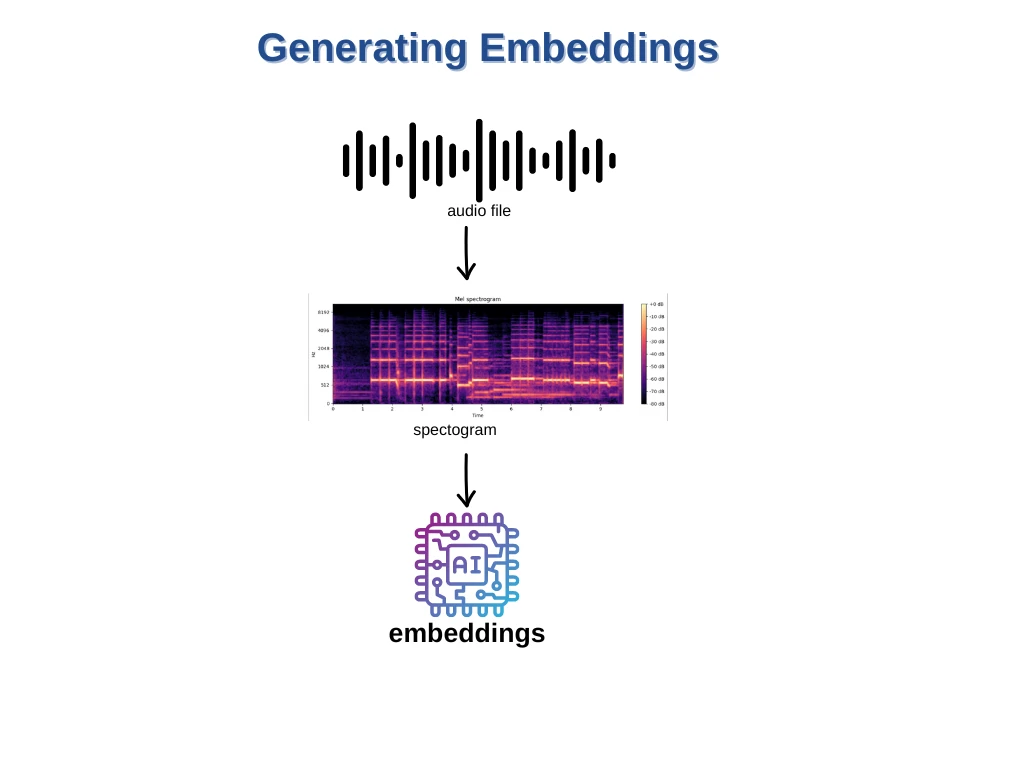 Процес створення вбудовувань як для текстових, так і для аудіоданих передбачає перетворення даних у вектори завдяки екстракції ознак або техніці вбудовування, після чого ці вектори індексуються в базі даних векторного пошуку.
Процес створення вбудовувань як для текстових, так і для аудіоданих передбачає перетворення даних у вектори завдяки екстракції ознак або техніці вбудовування, після чого ці вектори індексуються в базі даних векторного пошуку.
2.2.3 Витягнення звукових даних
Наступний крок полягає в аналізі наших аудіофайлів та витягуванні значущих особливостей. Цей крок є критично важливим, оскільки він допомагає моделі машинного навчання розуміти та навчатися на основі наших аудіоданих.
У контексті обробки аудіосигналів для машинного навчання процес видобування особливостей зі спектрограм є вирішальним кроком. Спектрограми - це візуальне представлення частотного вмісту аудіосигналів у часі. У цьому контексті ідентифіковані ознаки охоплюють три конкретні типи:
- Мел-частотні цепстральні коефіцієнти (MFCC): MFCC - це коефіцієнти, які відображають спектральні характеристики аудіосигналів у спосіб, що ближчий до людського слухового сприйняття.
- Характеристики кольоровості: Характеристики кольоровості представляють 12 різних класів висоти звуку в музичній октаві і є особливо корисними в завданнях, пов'язаних з музикою.
- Спектральний контраст: Спектральний контраст фокусується на сприйнятті яскравості різних частотних діапазонів в аудіосигналі.
Аналізуючи та порівнюючи ефективність цих наборів функцій у реальних текстових файлах, дослідники та практики можуть отримати цінну інформацію про їхню придатність для різних програм машинного навчання на основі аудіо, таких як класифікація та аналіз аудіо.
- По-перше, нам потрібно перетворити наші аудіофайли у формат, придатний для аналізу. Такі бібліотеки, як librosa на Python, можуть допомогти з цим перетворенням, перетворюючи аудіофайли на спектрограми.
- Далі ми витягнемо характеристики з цих спектрограм.
- Потім ми збережемо ці характеристики та надішлемо їх як вхідні дані для нашої моделі машинного навчання.
Ми використовуємо panns_inference - бібліотеку Python, призначену для задач тегування аудіо та розпізнавання звукових подій. Моделі, що використовуються в цій бібліотеці, навчаються на основі PANNs, що розшифровується як Large-Scale Pretrained Audio Neural Networks - методу розпізнавання аудіопаттернів.
!pip install -qU panns-inference librosa
from panns_inference import AudioTagging
# load the default model into the gpu.
model = AudioTagging(checkpoint_path=None, device='cuda') # change device to cpu if a gpu is not available
Примітка: Завантаження моделі виведення PANNS може зайняти кілька хвилин.
import numpy as np
# Function to normalize a vector. Normalizing a vector
means adjusting the values measured in different scales
to a common scale.
def normalize(v):
# np.linalg.norm computes the vector's norm (magnitude).
The norm is the total length of all vectors in a space.
norm = np.linalg.norm(v)
if norm == 0:
return v
# Return the normalized vector.
return v / norm
# Function to get an embedding of an audio file. An embedding is a reduced-dimensionality representation of the file.
def get_embedding (audio_file):
# Load the audio file using librosa's load function, which returns an audio time series and its corresponding sample rate.
a, _ = librosa.load(audio_file, sr=44100)
# Reshape the audio time series to have an extra dimension, which is required by the model's inference function.
query_audio = a[None, :]
# Perform inference on the reshaped audio using the model. This returns an embedding of the audio.
_, emb = model.inference(query_audio)
# Normalize the embedding. This scales the embedding to have a length (magnitude) of 1, while maintaining its direction.
normalized_v = normalize(emb[0])
# Return the normalized embedding required for dot_product elastic similarity dense vector
return normalized_v
2.3 Вставка аудіо даних в Elasticsearch
Тепер у нас є все необхідне, щоб вставити наші аудіодані в індекс Elasticsearch.
from datetime import datetime
#Storing Songs in Elasticsearch with Vector Embeddings:
def store_in_elasticsearch(song, embedding, path, index_name, genre, vec_field):
body = {
'audio-embedding' : embedding,
'title': song,
'timestamp': datetime.now(),
'path' : path,
'genre' : genre
}
es.index(index=index_name, document=body)
print ("stored...",song, embedding, path, genre, index_name)
audio_path = "/content/drive/MyDrive/@Blogs/MusicSearch/audios/"
# Initialize a list genre for test
genre_lst = ['jazz', 'opera', 'piano','prompt', 'humming', 'string', 'capella', 'eletronic', 'guitar']
for filename in audio_files:
audio_file = audio_path + filename
emb = get_embedding(audio_file)
song = filename
# Compare if genre list exists inside the song
for g in genre_lst:
if g in song.lower():
genre = g
else:
genre = "generic"
store_in_elasticsearch(song, emb, audio_file, index_name, genre, 2 )
2.4 Візуалізація результатів у Kibana
На цьому етапі ми можемо перевірити наш індекс з аудіо даними, вбудованими в щільне векторне поле. Kibana Dev Tools, зокрема функція Console, є потужним інтерфейсом для взаємодії з вашим кластером Elasticsearch. Вона надає можливість безпосередньо надсилати RESTful-команди до Elasticsearch та переглядати результати у зручному для користувача форматі.
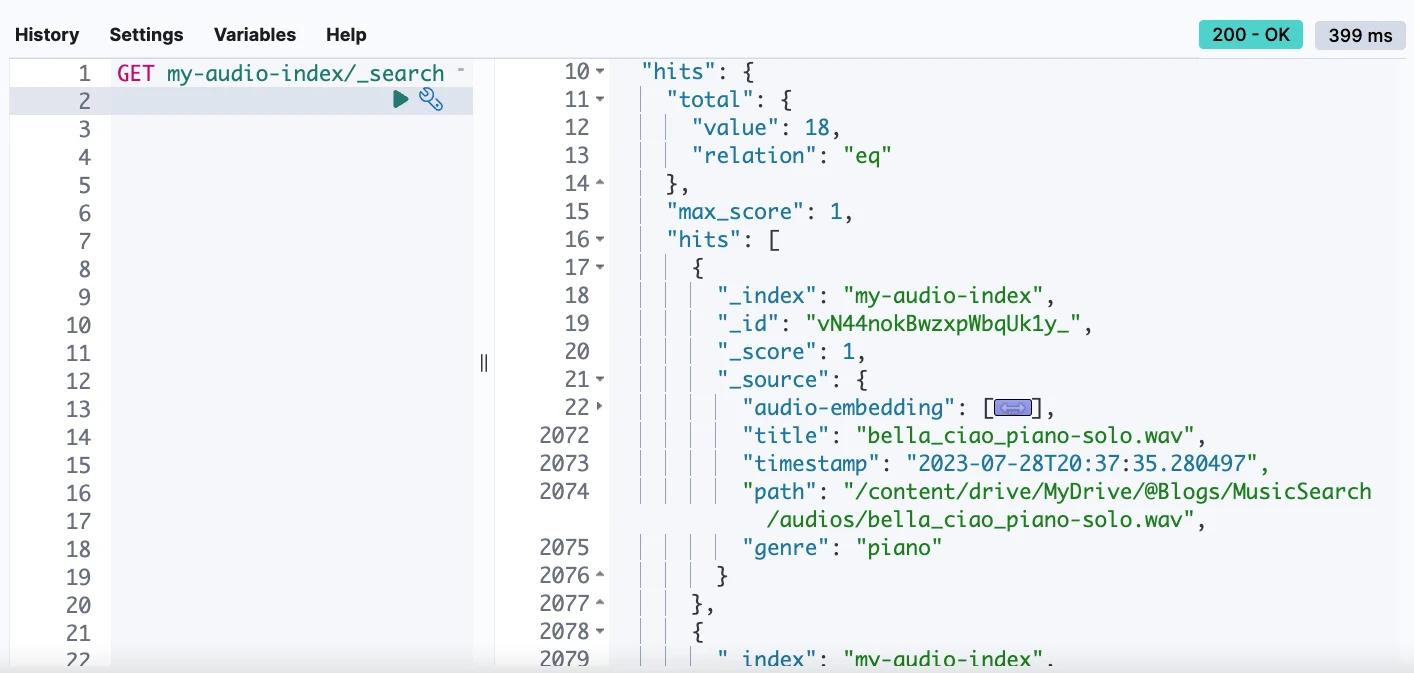
Крок 3: Пошук за музикою
Тепер ви можете виконати векторний пошук за схожістю, використовуючи створені вбудовування. Коли ви надаєте вхідну пісню системі, вона перетворює її на вбудовування, шукає в базі даних схожі вбудовування і повертає пісні зі схожими характеристиками.
# Define a function to query audio vector in Elasticsearch
def query_audio_vector(es, emb, field_key, index_name):
# Initialize the query structure
query = {
"bool": {
"filter": [{
"exists": {
"field": field_key
}
}]
}
}
# KNN search parameters
# field is the name of the field to perform the search on
# k is the number of nearest neighbors to find
# num_candidates is the number of candidates to consider (more means slower but potentially more accurate results)
# query_vector is the vector to find nearest neighbors for
# boost is the multiplier for scores (higher means this match is considered more important)
knn = {
"field": field_key,
"k": 2,
"num_candidates": 100,
"query_vector": emb,
"boost": 100
}
# The fields to retrieve from the matching documents
fields = ["title", "path", "genre", "body_content", "url"]
# The name of the index to search
index = index_name
# Perform the search
resp = es.search(index=index,
query=query,
knn=knn,
fields=fields,
size=5,
source=False)
# Return the search results
return resp
Переходимо до найцікавішого!
3.1 Вибір музики для пошуку
У наведеному нижче коді ми вибираємо музику безпосередньо з каталогу аудіофайлів GitHub і використовуємо аудіо для відтворення результату в Google Colab.
# Import necessary modules for audio display from IPython
from IPython.display import Audio, display
# Provide the URL of the audio file
my_audio = "/content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_humming.wav"
# Display the audio file in the notebook
Audio(my_audio)
3.2 Пошук музики
Тепер запустимо код для пошуку музики my_audio в Elasticsearch. Ми будемо використовувати тільки аудіофайл для пошуку.
# Generate the embedding vector from the provided audio file
emb = get_embedding(audio_file)
# Query the Elasticsearch instance 'es' with the embedding vector 'emb', field key 'audio-embedding',
# and index name 'my-audio-index'
resp = query_audio_vector (es, emb.tolist(), "audio-embedding", "my-audio-index" )
А Elasticsearch поверне вам всю музику, схожу на вашу ключову пісню:
{
'total': {
'value': 18,
'relation': 'eq'
},
'max_score': 100.0,
'hits': [
{
'_index': 'my-audio-index',
'_id': 'tt44nokBwzxpWbqUfVwN',
'_score': 100.0,
'fields': {
'path': ['/content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_humming.wav'],
'genre': ['humming'],
'title': ['bella_ciao_humming.wav']
}
},
{
'_index': 'my-audio-index',
'_id': 'u944nokBwzxpWbqUj1zy',
'_score': 86.1148,
'fields': {
'path': ['/content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_opera-singer.wav'],
'genre': ['opera'],
'title': ['bella_ciao_opera-singer.wav']
}
},
{
'_index': 'my-audio-index',
'_id': 'vt44nokBwzxpWbqUm1xK',
'_score': 0.0,
'fields': {
'path': ['/content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_tribal-drums-and-flute.wav'],
'genre': ['generic'],
'title': ['bella_ciao_tribal-drums-and-flute.wav']
}
},
{
'_index': 'my-audio-index',
'_id': 'uN44nokBwzxpWbqUhFye',
'_score': 0.0,
'fields': {
'path': ['/content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_electronic-synth-lead.wav'],
'genre': ['generic'],
'title': ['bella_ciao_electronic-synth-lead.wav']
}
},
{
'_index': 'my-audio-index',
'_id': 'wN44nokBwzxpWbqUpFyT',
'_score': 0.0,
'fields': {
'path': ['/content/drive/MyDrive/@Blogs/MusicSearch/audios/a-cappella-chorus.wav'],
'genre': ['generic'],
'title': ['a-cappella-chorus.wav']
}
}
]
}
Трохи коду, який допоможе відтворити результати:
NUM_MUSIC = 5 # example value
for i in range(NUM_MUSIC):
path = resp['hits']['hits'][i]['fields']['path'][0]
print(path)
content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_humming.wav /content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_humming.wav /content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_a-cappella-chorus.wav /content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_electronic-synth-lead.wav /content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_guitar-solo.wav
Audio("/content/drive/MyDrive/@Blogs/MusicSearch/audios/bella_ciao_a-cappella-chorus.wav")
Тепер ви можете перевірити результат, натиснувши кнопку Play.
3.3 Аналіз результатів
Отже, чи можу я розгорнути цей код у робочому середовищі та продати свій застосунок? Ні, оскільки імовірнісна нейронна мережа (PANN), як і будь-яка інша модель машинного навчання, потребує більшого обсягу даних і додаткового налаштування для ефективного застосування в реальних сценаріях.
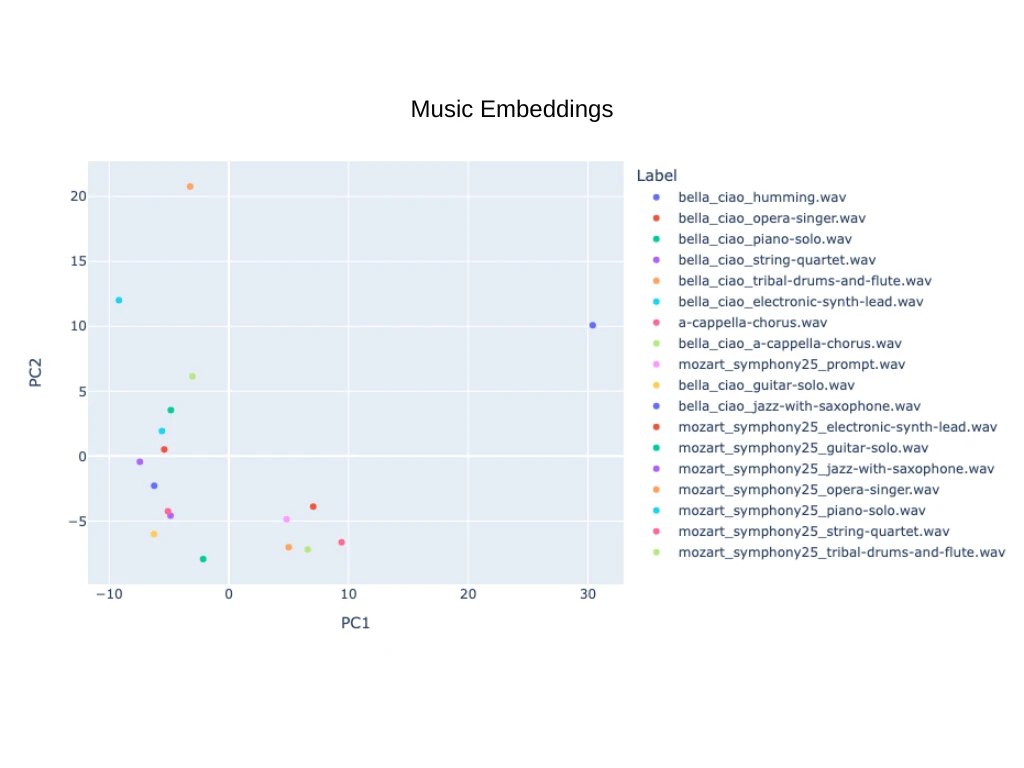
Це видно на графіку, що візуалізує вставки, пов'язані з нашою вибіркою з 18 пісень, які можуть спричинити помилкові спрацьовування підходу kNN. Однак перед майбутніми інженерами з обробки даних стоїть ще один важливий виклик: визначення оптимальної моделі для запиту за наспівуванням. Це захопливе поєднання машинного навчання та слухового пізнання, яке вимагає ретельних досліджень та інноваційного розв'язання проблем.
3.4 Покращення POC за допомогою інтерфейсу користувача (необов'язково)
З невеликими змінами я скопіював і вставив весь цей код в Streamlit. Streamlit - це бібліотека Python, яка спрощує створення інтерактивних застосунків для проєктів з науки про дані та машинного навчання. Вона дозволяє новачкам легко перетворювати скрипти даних на спільні веб-застосунки без глибоких знань з веб-розробки.
Результатом є цей застосунок
Вікно в майбутнє аудіопошуку
Ми успішно реалізували систему пошуку музики за допомогою векторів Elasticsearch на Python. Це слугує відправною точкою в галузі аудіопошуку і потенційно може надихнути на інноваційніші концепції завдяки використанню цього архітектурного підходу. Змінюючи моделі, можна розробляти різноманітні програми. Крім того, перенесення виведення на Elasticsearch може потенційно підвищити продуктивність. Відвідайте сторінку машинного навчання Elastic, щоб дізнатися більше про нього.
Це свідчить про значний потенціал та адаптивність цієї технології для різноманітних пошукових застосунків за межами тексту.
Весь код доступний в одному файлі Google Colab, elastic-music_search.ipynb, на GitHub.

Ще немає коментарів