Ті, хто займається машинним навчанням (Machine Learning, ML), зазвичай, реалізуючи різні проєкти, виконує наступні дії: збір даних, їх очищення, розвідувальний аналіз даних, розробка моделі, публікація моделі в локальній мережі або в інтернеті. Ось гарне відео, в якому можна дізнатися про подробиці про це.

Автор статті, переклад якої ми сьогодні публікуємо, хоче розповісти про те, як, використовуючи Python-бібліотеки streamlit, pandas і scikit-learn, створити простий веб застосунок, в якому застосовуються технології машинного навчання. Він говорить, що розмір цього додатка не перевищує 50 рядків. Стаття заснована на цьому відео, яке можна дивитися паралельно з читанням. Інструменти, які будуть тут розглянуті, крім іншого, дозволяють прискорити й спростити розгортання ML-проєктів.
Нам, щоб побудувати модель і опублікувати її де-небудь, знадобляться бібліотеки streamlit, pandas і scikit-learn. Поглянемо на загальну схему проєкту. Він буде складатися з двох великих частин: фронтенд і бекенд.
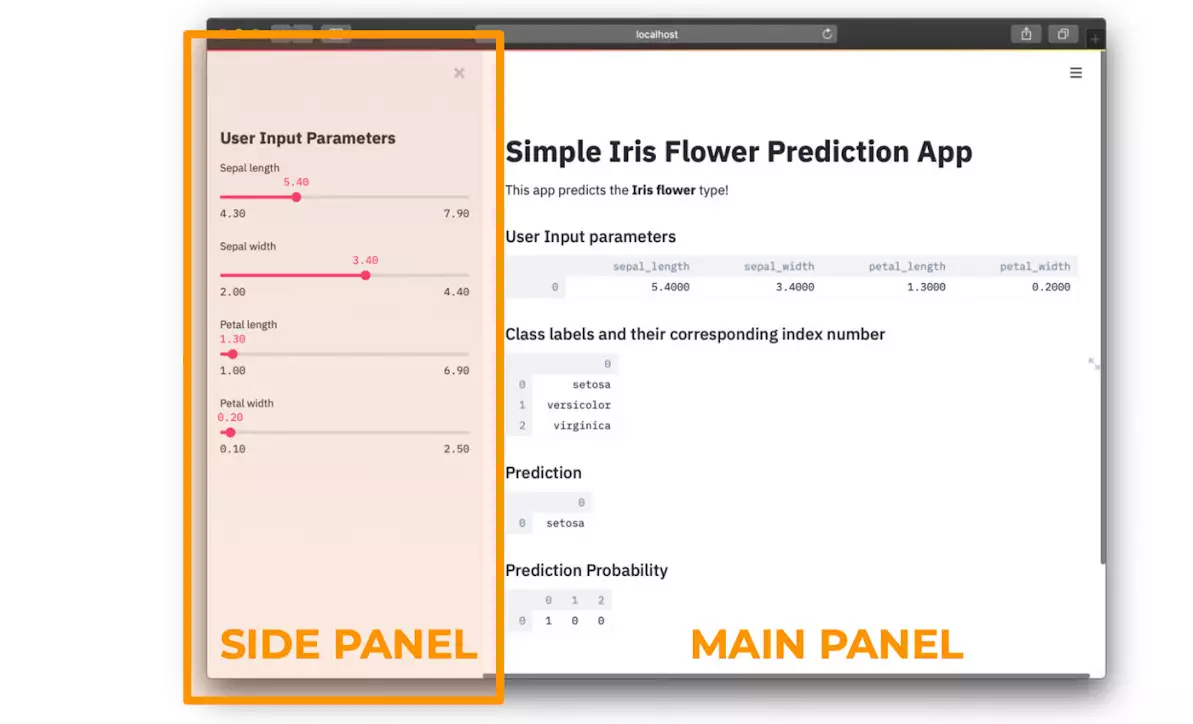
У фронтенд частини програми, а саме, на веб сторінці, буде бічна панель, що знаходиться ліворуч, в якій можна буде вводити вхідні параметри моделі, які пов'язані з характеристиками квіток ірису: довжина пелюстка (petal length), ширина пелюстка (petal width), довжина чашолистка (sepal length), ширину чашолистка (sepal width). Ці дані будуть передаватися бэкенду, де попередньо навчена модель буде класифікувати квітки, використовуючи задані характеристики. Фактично, мова йде про функцію яка отримує характеристики квітки повертає її вигляд. Результати класифікації відправляються фронтенду.
У бекенд-частини додатку, те що ввів користувач зберігається в датафреймі, який буде використовуватися у вигляді тестових даних для моделі. Потім буде побудована модель для обробки даних. У ній буде застосовуватися алгоритм «випадковий ліс» з бібліотеки scikit-learn. І нарешті, модель буде застосована для класифікації даних, введених користувачем, тобто — для визначення виду квітки. Крім того, разом з відомостями про вигляд квітки, будуть повертатися і дані про прогнозні ймовірності. Це дозволить нам визначити ступінь вірогідністі результатів класифікації.
Життєвий цикл проєкту в сфері машинного навчання
Етап публікації моделі завершує життєвий цикл ML-проєктів. Він так само важливий для data scientist і фахівців з машинного навчання, як і інші етапи. Звичайні підходи до публікації моделей передбачають використання універсальних фреймворків, таких, як Django або Flask. Головні проблеми тут полягають у тому, що для застосування таких інструментів потрібні особливі знання і навички, і в тому, що робота з ними може зайняти чимало часу.Автор статті, переклад якої ми сьогодні публікуємо, хоче розповісти про те, як, використовуючи Python-бібліотеки streamlit, pandas і scikit-learn, створити простий веб застосунок, в якому застосовуються технології машинного навчання. Він говорить, що розмір цього додатка не перевищує 50 рядків. Стаття заснована на цьому відео, яке можна дивитися паралельно з читанням. Інструменти, які будуть тут розглянуті, крім іншого, дозволяють прискорити й спростити розгортання ML-проєктів.
Огляд моделі, що визначає вид квітки ірису
Сьогодні ми створимо простий веб застосунок, що використовує технології машинного навчання. Він буде класифікувати квітки ірису з вибірки Фішера, відносячи їх до одного з чотирьох видів: ірис сетоза (iris setosa), ірис строкатий (iris versicolor), ірис віргінський (iris virginica). Можливо, ви вже бачили безліч ML-прикладів, побудованих на основі цього знаменитого набору даних. Але, сподіваюся, те, що я тут буду розглядати ще один такий приклад, вам не завадить. Адже цей набір — він як «lorem ipsum» — класичний безглуздий текст-заповнювач, який вставляють в макети сторінок.Нам, щоб побудувати модель і опублікувати її де-небудь, знадобляться бібліотеки streamlit, pandas і scikit-learn. Поглянемо на загальну схему проєкту. Він буде складатися з двох великих частин: фронтенд і бекенд.
У фронтенд частини програми, а саме, на веб сторінці, буде бічна панель, що знаходиться ліворуч, в якій можна буде вводити вхідні параметри моделі, які пов'язані з характеристиками квіток ірису: довжина пелюстка (petal length), ширина пелюстка (petal width), довжина чашолистка (sepal length), ширину чашолистка (sepal width). Ці дані будуть передаватися бэкенду, де попередньо навчена модель буде класифікувати квітки, використовуючи задані характеристики. Фактично, мова йде про функцію яка отримує характеристики квітки повертає її вигляд. Результати класифікації відправляються фронтенду.
У бекенд-частини додатку, те що ввів користувач зберігається в датафреймі, який буде використовуватися у вигляді тестових даних для моделі. Потім буде побудована модель для обробки даних. У ній буде застосовуватися алгоритм «випадковий ліс» з бібліотеки scikit-learn. І нарешті, модель буде застосована для класифікації даних, введених користувачем, тобто — для визначення виду квітки. Крім того, разом з відомостями про вигляд квітки, будуть повертатися і дані про прогнозні ймовірності. Це дозволить нам визначити ступінь вірогідністі результатів класифікації.
Установка бібліотек
Як вже було сказано, тут ми будемо користуватися трьома бібліотеками:streamlit, pandas та scikit-learn. Встановити їх можна, користуючись pip install:pip install streamlit
pip install pandas
pip install -U scikit-learn
Розробка веб додатку
Тепер напишемо код додатка. Проєкт у нас досить скромний. Він складається з менш ніж 50 рядків коду. А якщо точніше — то їх тут всього 48. Якщо ж цей код «ущільнити», позбувшись від коментарів і порожніх рядків, то розмір тексту програми скоротиться до 36 рядків.import streamlit as st
import pandas as pd
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
st.write("""
# Simple Iris Flower Prediction App
This app predicts the **Iris flower** type!
""")
st.sidebar.header('User Input Parameters')
def user_input_features():
sepal_length = st.sidebar.slider('Sepal length', 4.3, 7.9, 5.4)
sepal_width = st.sidebar.slider('Sepal width', 2.0, 4.4, 3.4)
petal_length = st.sidebar.slider('Petal length', 1.0, 6.9, 1.3)
petal_width = st.sidebar.slider('Petal width', 0.1, 2.5, 0.2)
data = {'sepal_length': sepal_length,
'sepal_width': sepal_width,
'petal_length': petal_length,
'petal_width': petal_width}
features = pd.DataFrame(data, index=[0])
return features
df = user_input_features()
st.subheader('User Input parameters')
st.write(df)
iris = datasets.load_iris()
X = iris.data
Y = iris.target
clf = RandomForestClassifier()
clf.fit(X, Y)
prediction = clf.predict(df)
prediction_proba = clf.predict_proba(df)
st.subheader('Class labels and their corresponding index number')
st.write(iris.target_names)
st.subheader('Prediction')
st.write(iris.target_names[prediction])
#st.write(prediction)
st.subheader('Prediction Probability')
st.write(prediction_proba)
Розбір коду
Тепер розберемо цей код.▍Імпорт бібліотек
import streamlit as st
import pandas as pd
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
streamlit та pandas, призначаючи їм, відповідно, псевдоніми st та pd. Ми, крім того, імпортуємо пакет datasets з бібліотеки scikit-learn (sklearn). Ми скористаємося цим пакетом нижче, у команді iris = datasets.load_iris(), для завантаження набору даних що нас цікавить. І нарешті, тут ми імпортуємо функцію RandomForestClassifier() з пакету sklearn.ensemble.▍Формування бічної панелі
st.sidebar.header('User Input Parameters')
st.sidebar.header(). Зверніть увагу на те, що тут sidebar стоїть між st і header(), що і дає повне ім'я функції st.sidebar.header(). Ця функція повідомляє бібліотеці streamlit про те, що ми хочемо помістити заголовок у бічну панель.def user_input_features():
sepal_length = st.sidebar.slider('Sepal length', 4.3, 7.9, 5.4)
sepal_width = st.sidebar.slider('Sepal width', 2.0, 4.4, 3.4)
petal_length = st.sidebar.slider('Petal length', 1.0, 6.9, 1.3)
petal_width = st.sidebar.slider('Petal width', 0.1, 2.5, 0.2)
data = {'sepal_length': sepal_length,
'sepal_width': sepal_width,
'petal_length': petal_length,
'petal_width': petal_width}
features = pd.DataFrame(data, index=[0])
return features
user_input_features(), яка бере дані, введені користувачем (тобто — чотири характеристики квітки, які вводяться з використанням повзунків), і повертає результат у вигляді датафрейма. Варто зазначити, що кожен вхідний параметр вводиться в систему за допомогою повзунка. Наприклад, повзунок для введення довжини чашолистка (sepal length) описується так: st.sidebar.slider('Sepal length', 4.3, 7.9, 5.4). Перший з чотирьох вхідних аргументів цієї функції ставить підпис повзунка, що виводиться вище нього. Це, в цьому випадку, текст Sepal length. Два наступні аргументи задають мінімальне та максимальне значення, яке можна задавати за допомогою повзунка. Останній аргумент задає значення, що виставляється на повзунку за замовчуванням, при завантаженні сторінки. Тут це — 5.4.▍Створення моделі
df = user_input_features()
user_input_features(), яку ми тільки що обговорили, записується в змінну df.iris = datasets.load_iris()
sklearn.datasets і запис його в змінну iris.X = iris.data
Х, яка містить відомості про 4 характеристиках квітки, які є в iris.data.Y = iris.target
Y, яка містить відомості про вигляд квітки. Ці відомості зберігаються в iris.target.clf = RandomForestClassifier()
RandomForestClassifier(), призначаємо класифікатор, заснований на алгоритмі «випадковий ліс», змінної clf.clf.fit(X, Y)
clf.fit(), передаючи їй в якості аргументів змінні X та Y. Суть полягає в тому, що модель буде навчена визначенню виду квітки (Y) на основі його характеристик (X).prediction = clf.predict(df)
prediction_proba = clf.predict_proba(df)
▍Формування основної панелі
st.write("""
# Simple Iris Flower Prediction App
This app predicts the **Iris flower** type!
""")
st.write(), виводимо текст. А саме, мова йде про заголовок, який показується в головній панелі програми, текст якого заданий у форматі Markdown. Символ # використовується для вказівки того, що текст є заголовком. За рядком заголовка йде рядок звичайного тексту.st.subheader('User Input parameters')
st.subheader(), ми вказуємо підзаголовок, виведений в основній панелі. Цей підзаголовок використовується для оформлення розділу сторінки, у якому буде показано вміст датафрейма, тобто того, що було введене користувачем за допомогою повзунків.st.write(df)
df.st.subheader('Class labels and their corresponding index number')
st.write(iris.target_names)
setosa, versicolor та virginica) і відповідні їм номери (0, 1, 2).st.subheader('Prediction')
st.write(iris.target_names[prediction])
prediction — це номер виду квітки, виданий моделлю на основі вхідних даних, введених користувачем. Для того щоб вивести назву виду, використовується конструкція iris.target_names[prediction].st.subheader('Prediction Probability')
st.write(prediction_proba)
Запуск веб-додатку
Код додатка збережений у файліiris-ml-app.py. Ми готові до того, щоб його запустити. Зробити це можна, виконавши наступну команду в терміналі:streamlit run iris-ml-app.py
> streamlit run iris-ml-app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://10.0.0.11:8501
http://localhost:8501.Те, що ви побачите, буде схоже на наступний малюнок.

Ще немає коментарів