GraphQL — сервіс, який створений за допомогою описання типів та їх полів. Іншими словами — це один з підходів організації інтерфейсу взаємодії між клієнтом та сервером. У статті говоримо про API розробку за допомогою GraphQL на платформі .NET, різницю між GraphQL та REST, розглянемо основні компоненти GraphQL, «за» та «проти» його використання.
GraphQL vs REST
Основна різниця між GraphQL та REST полягає в агрегації та принципі отримання даних. В REST ми маємо змогу отримати тільки цілу модель ресурсу, а не перелік конкретних полів.
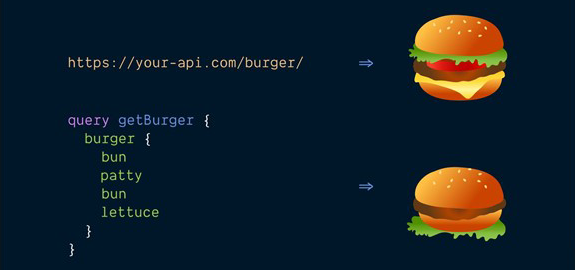
У випадку з GraphQL, ми маємо більшу гнучкість в плані агрегації даних. Наприклад: ми посилаємо запит, щоб отримати певний ресурс (бургер).
- REST: ми повертаємо всі поля (інгредієнти), які ми описали для ресурсу.
- GraphQL: ми передаємо перелік полів: bun, patty, bun, lettuce (інгредієнтів), які ми хочемо отримати.
На думку відразу приходить: ODATA (The best way to REST)? Відповідь: так, вони доволі подібні. Але основна перевага GraphQL полягає в тому, що він максимально тривіальний і простий в плані описання даних, які ми хочемо отримати.
Основні принципи GraphQL
GraphQL складається з таких компонентів як:
- Schema — корінь будь-якого сервера, який реалізує GraphQL. Іншими словами — місце, де зберігається інформація про типи схеми, яку ми описали, і, де виконуються наші queries.
- Type system — система типів, з якими ми можемо працювати.
- Query language — специфікація, що описує яким чином ми можемо маніпулювати даними та отримувати дані на клієнті.
Queries (Запити)
GET (якщо проводити аналогію з REST). Коротко, ми отримали можливість агрегувати дані через єдиний endpoint. Наприклад, ми хочемо отримати дані з декількох ресурсів (фільм та акторів, які знімались в ньому). З GraphQL ми можемо об'єднати все це в єдиний запит. Тобто, всередині query ми описуємо наступні поля: name, description, genre, actors.

В коді це виглядає наступним чином:

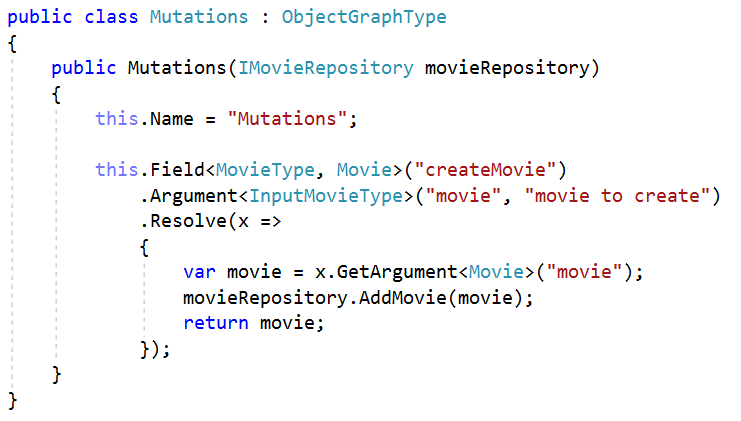
Mutations
Виходячи зі специфікації: будь-яка операція запису повинна реалізуватись через mutations. Для їх створення нам потрібно вказати три речі: назву мутації, описати структуру аргументів та даних, які ми хочемо отримати у разі успішного виконання.

Як це виглядає в коді:
Subscriptions
Subscriptions дають нам можливість підписуватись на певні події та отримувати інформацію по них, коли вони відбуваються. Наприклад: юзер надсилає mutation на створення фільму (або зміну дати виходу), і за допомогою subscription ми можемо повідомити інших юзерів про те, що вийшов новий фільм (або змінилась дата його виходу). Зазвичай вони реалізуються через WebSockets.
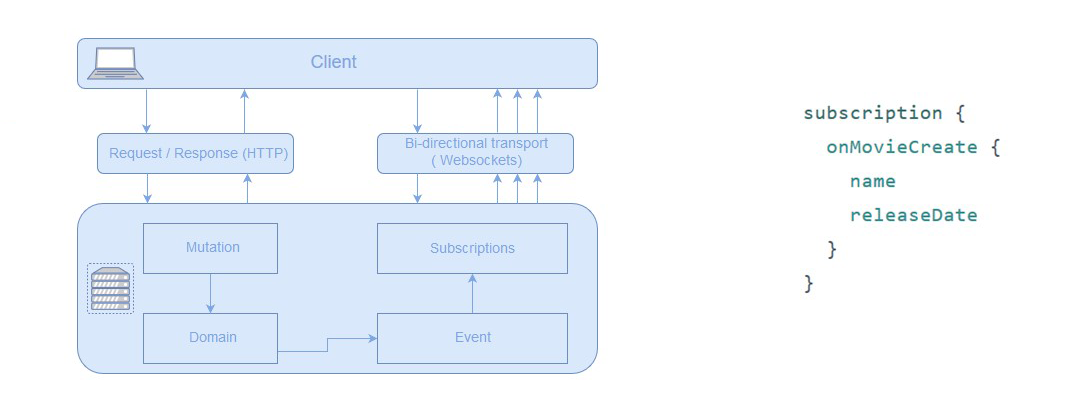
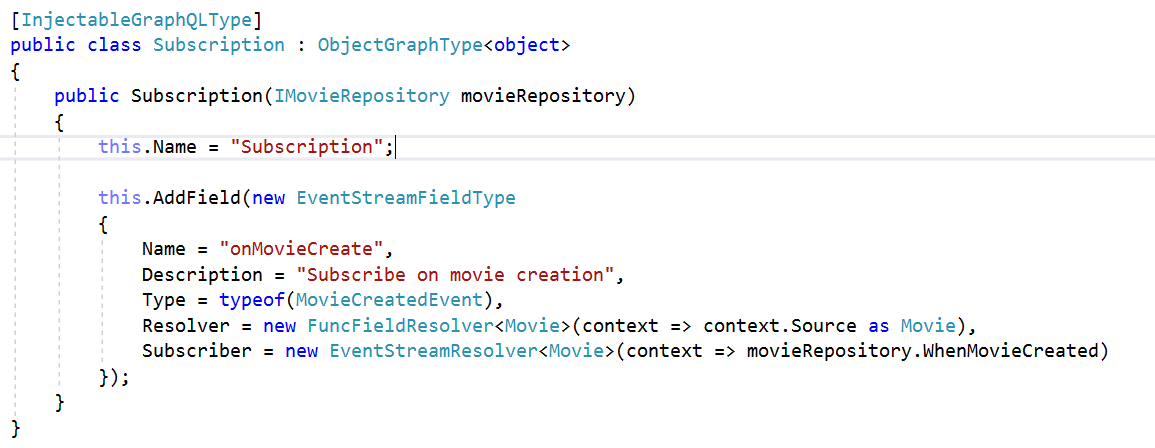
Для оголошення Subscription нам потрібно вказати назву та дані, які хочемо отримати. В коді це виглядає наступним чином:
Особливості
На що потрібно звернути увагу, коли ми збираємося додати GraphQL в нашу систему:
Специфікація GraphQL не охоплює авторизацію. Як рішення: ми можемо перенести її на вищий рівень, або створити окремий сервіс для авторизації.
Завантаження файлів. Суть полягає в тому, що GraphQL з коробки підтримує тільки серіалізовані дані, тому ми не можемо виконати multipart upload через mutation. Jayden Seric описав реалізацію для JavaScript та Apollo: https://github.com/jaydenseric/graphql-upload.
Рішення:
- Можна реалізувати підхід, який представив Jayden Seric в .NET.
- Як варіант, можна завантажувати файли, конвертовані в Base64.
- Реалізувати File Upload через REST.
Обмеженість ресурсів (resource limitations). При створенні GraphQL сервера потрібно враховувати, що ми можемо отримувати query, які будуть не дуже оптимальні в плані навантаження на систему. Розв'язати цю проблему ми можемо за допомогою:
- Query Complexity Analysis — підрахувавши складність певного запиту, ми отримуємо можливість встановити грань і відсіювати неоптимальні запити. Принцип простий: кожне поле має значення, яке ми надалі сумуємо.
- Limit Query Depth — оскільки граф в принципі не лінійна структура даних, нам потрібно обмежувати кількість вкладених типів всередині нашого запиту.
N+1. Приклад: ми хочемо отримати список фільмів з акторами по кожному, без оптимізації в нас вийде щось на зразок цього: фільм (1 запит) + (актори (n запитів)).
- Рішення: DataLoader. Він розв'язує дану проблему шляхом кешування та групування подібних запитів.
Плюси та мінуси
Плюси та мінуси, які можна виділити, імплементуючи технологію в проект.
До плюсів можна віднести:
- Incremental adoption: кожне поле містить за собою функції, тому ми маємо доволі гнучкий механізм в плані зміни та розширення сервера.
- No over fetching at network level: причина цього в тому, що отримуємо тільки ті дані, які ми описали в запиті на сервер.
- Declarative data fetching: це видно вище, що структура типу, яку ми описуємо, доволі подібна до JSON.
- Коли обидві команди (frontend та backend) описали граф типів, вони мають можливість працювати незалежно одна від одної, оскільки у випадку з GraphQL структуру (форму) даних визначає клієнт, а не сервер.
До мінусів:
- Unpredictable execution: оскільки ми не контролюємо виконання наших queries, доволі складно виявити причину, якщо ми неправильно оголосили певний тип або поле.
- Schema duplication: нам потрібно описати весь граф типів.
- Server/Client Data mismatch: клієнт визначає структуру даних, яку він хоче отримати, саме тому схема на клієнті може відрізнятись від тієї, що на сервері.
Висновки
Підсумовуючи все вищесказане про GraphQL, можна виділити такі пункти:
- Максимальну користь отримаємо в контрольованих середовищах, коли ми маємо бачення графа даних, який будемо використовувати, і не маємо проблем з комунікацією між командами. Тобто, всі розуміють як різні типи взаємопов'язані.
- Мені подобається цитата: «GraphQL Is A Tool In My Toolbox» — це не панацея від усього, а один з підходів до проектування API.
- Чи варто залишатися на REST? Відповідь: зверни увагу на попередній пункт.
- Чи потрібно мігрувати готовий проект GraphQL? Відповідь: Не потрібно. Як варіант, можна зробити свого роду Gateway між RESTful API та клієнтом.
Посилання на репозиторій, де можна знайти source code даного прикладу Github.
Дякую за увагу!

Ще немає коментарів