
Ми перебуваємо в самому розпалі революції штучного інтелекту. Вона перевертає будь-яку галузь, якої торкається, обіцяючи великі інновації, але водночас створює нові виклики. Ефективна обробка даних стала як ніколи важливою для програм, які використовують великі мовні моделі, генеративний ШІ та семантичний пошук.
Всі ці нові програми покладаються на векторні вбудовування (англ. vector embedded) - тип представлення даних, який несе в собі семантичну інформацію, критично важливу для розуміння ШІ та збереження довготривалої пам'яті, на яку він може спиратися при виконанні складних завдань.
Вбудовування генеруються моделями ШІ (наприклад, великими мовними моделями) і мають велику кількість атрибутів або ознак, що робить їхнє представлення складним для управління. У контексті ШІ та машинного навчання ці особливості представляють різні виміри даних, які є важливими для розуміння закономірностей, взаємозв'язків і базових структур.
Ось чому нам потрібна спеціалізована база даних, розроблена спеціально для роботи з цим типом даних. Векторні бази даних, такі як Pinecone, задовольняють цю вимогу, пропонуючи оптимізоване збереження та можливості запитів для вбудовувань. Векторні бази даних мають можливості традиційних баз даних, які відсутні в окремих векторних індексах, і спеціалізацію для роботи з векторними вбудовуваннями, чого бракує традиційним скалярним базам даних.
Проблема роботи з векторними вбудованими даними полягає в тому, що традиційні скалярні бази даних не можуть впоратися зі складністю та масштабом таких даних, що ускладнює вилучення інсайтів та проведення аналізу в реальному часі. Саме тут у гру вступають векторні бази даних - вони спеціально розроблені для роботи з цим типом даних і пропонують продуктивність, масштабованість і гнучкість, необхідні для отримання максимальної віддачі від ваших даних.
За допомогою векторної бази даних ми можемо додати розширені функції до нашого штучного інтелекту, такі як семантичний пошук інформації, довгострокова пам'ять і багато іншого. Діаграма нижче дає нам краще розуміння ролі векторних баз даних у цьому типі програм:
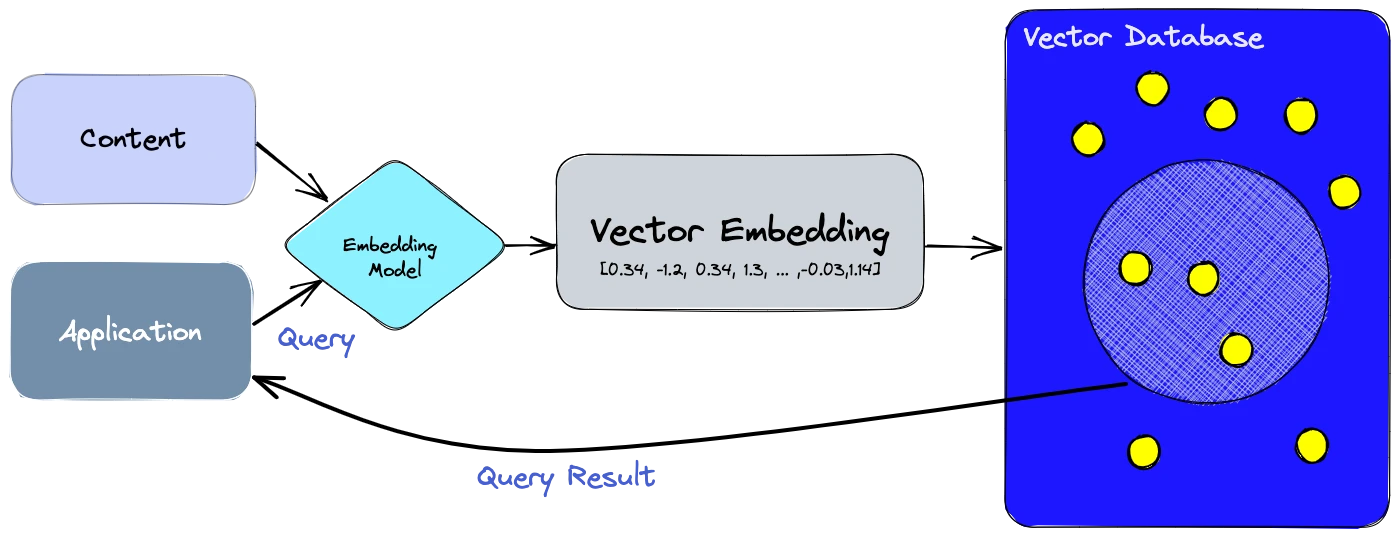
Розберімось, як це робиться:
- По-перше, ми використовуємо модель вбудовування для створення векторних вбудовувань для контенту, який ми хочемо індексувати.
- Векторне вбудовування вставляється у векторну базу даних з певним посиланням на оригінальний вміст, з якого було створено вбудовування.
- Коли програма видає запит, ми використовуємо ту саму модель вбудовування, щоб створити вбудовування для запиту, і використовуємо ці вбудовування для запиту до бази даних для пошуку подібних векторних вбудовувань. І, як уже згадувалося, ці схожі вбудовування пов'язані з оригінальним контентом, який було використано для їх створення.
Яка різниця між векторним індексом і векторною базою даних?
Автономні векторні індекси, такі як FAISS (Facebook AI Similarity Search), можуть значно покращити пошук і вибірку векторних вбудовувань, але їм не вистачає можливостей, які є в будь-якій базі даних. З іншого боку, векторні бази даних спеціально створені для управління векторними вбудовуваннями, що дає кілька переваг порівняно з використанням окремих векторних індексів:
-
Керування даними: Векторні бази даних пропонують добре відомі та прості у використанні функції для зберігання даних, такі як вставка, видалення та оновлення даних. Це полегшує управління та підтримку векторних даних порівняно з використанням окремого векторного індексу, такого як FAISS, який вимагає додаткової роботи для інтеграції з рішенням для зберігання даних.
-
Зберігання та фільтрація метаданих: Векторні бази даних можуть зберігати метадані, пов'язані з кожним векторним записом. Користувачі можуть робити запити до бази даних, використовуючи додаткові фільтри метаданих для більш детальних запитів.
-
Масштабованість: Векторні бази даних призначені для масштабування зі зростанням даних і вимог користувачів, забезпечуючи кращу підтримку розподіленої та паралельної обробки. Автономні векторні індекси можуть потребувати індивідуальних рішень для досягнення подібного рівня масштабованості (наприклад, розгортання та управління ними на кластерах Kubernetes або інших подібних системах).
-
Оновлення в режимі реального часу: Векторні бази даних часто підтримують оновлення даних у режимі реального часу, що дозволяє динамічно змінювати дані, тоді як автономні векторні індекси можуть вимагати повного переіндексування для включення нових даних, що може зайняти багато часу і вимагати значних обчислювальних витрат.
-
Резервне копіювання та колекції: Векторні бази даних виконують рутинну операцію резервного копіювання всіх даних, що зберігаються в базі даних. Pinecone також дозволяє користувачам вибірково обирати певні індекси, для яких можна створювати резервні копії у вигляді "колекцій", що зберігають дані в цьому індексі для подальшого використання.
-
Інтеграція в екосистему: Векторні бази даних легше інтегруються з іншими компонентами екосистеми обробки даних, такими як конвеєри ETL (наприклад, Spark), інструменти аналітики (наприклад, Tableau і Segment) і платформи візуалізації (наприклад, Grafana), що спрощує робочий процес управління даними. Він також забезпечує легку інтеграцію з іншими інструментами, пов'язаними зі штучним інтелектом, такими як LangChain, LlamaIndex і плагіни ChatGPT.
-
Безпека даних і контроль доступу: Векторні бази даних зазвичай пропонують вбудовані функції безпеки даних і механізми контролю доступу для захисту конфіденційної інформації, які можуть бути недоступні в автономних рішеннях векторних індексів.
Загалом, векторна база даних є кращим рішенням для обробки векторних вбудовувань, оскільки усуває обмеження автономних векторних індексів, такі як проблеми масштабування, громіздкі процеси інтеграції, відсутність оновлень у реальному часі та вбудованих заходів безпеки, забезпечуючи більш ефективне та спрощене управління даними.
Як працює векторна база даних?
Ми всі знаємо, як працюють традиційні бази даних (більш-менш) - вони зберігають рядки, числа та інші типи скалярних даних у рядках і стовпцях. З іншого боку, векторна база даних оперує векторами, тому спосіб оптимізації та запитів до неї зовсім інший.
У традиційних базах даних ми зазвичай запитуємо рядки бази даних, де значення зазвичай точно відповідає нашому запиту. У векторних базах даних ми застосовуємо метрику подібності, щоб знайти вектор, який найбільш схожий на наш запит.
Векторна база даних використовує комбінацію різних алгоритмів, які беруть участь у наближеному пошуку найближчого сусіда (ANN). Ці алгоритми оптимізують пошук за допомогою хешування, квантування або пошуку на основі графів.
Ці алгоритми зібрані в конвеєр, який забезпечує швидкий і точний пошук сусідів запитуваного вектора. Оскільки векторна база даних надає приблизні результати, основний компроміс, який ми розглядаємо, - це компроміс між точністю і швидкістю. Чим точніший результат, тим повільнішим буде запит. Однак хороша система може забезпечити надшвидкий пошук з майже ідеальною точністю.
Ось загальний конвеєр для векторної бази даних:

- Індексування: Векторна база даних індексує вектори за допомогою таких алгоритмів, як PQ, LSH або HNSW (докладніше про них нижче). На цьому етапі вектори зіставляються зі структурою даних, що уможливлює швидший пошук.
- Створення запиту: Векторна база даних порівнює індексований вектор запиту з індексованими векторами в наборі даних, щоб знайти найближчих сусідів (застосовуючи метрику подібності, що використовується цим індексом).
- Постобробка: У деяких випадках векторна база даних отримує остаточних найближчих сусідів з набору даних і здійснює постобробку, щоб повернути остаточні результати. Цей крок може включати переранжування найближчих сусідів з використанням іншої міри подібності.
У наступних розділах ми розглянемо кожен з цих алгоритмів більш детально і пояснимо, як вони впливають на загальну продуктивність векторної бази даних.
Алгоритми
Створення векторного індексу можна полегшити за допомогою декількох алгоритмів. Їхньою спільною метою є забезпечення швидкого виконання запитів шляхом створення структури даних, яку можна швидко обходити. Зазвичай вони перетворюють представлення вихідного вектора у стиснуту форму для оптимізації процесу запиту.
Однак, як користувачу Pinecone, вам не потрібно турбуватися про тонкощі та вибір цих різноманітних алгоритмів. Pinecone розроблений таким чином, щоб впоратися з усіма складнощами та алгоритмічними рішеннями за лаштунками, гарантуючи вам найкращу продуктивність та результати без зайвого клопоту. Використовуючи досвід Pinecone, ви можете зосередитися на тому, що дійсно має значення - на отриманні цінної інформації та створенні потужних рішень для ШІ.
У наступних розділах ми розглянемо кілька алгоритмів та їхні унікальні підходи до обробки векторних вбудовувань. Ці знання допоможуть вам приймати обґрунтовані рішення та оцінити бездоганну продуктивність, яку забезпечує Pinecone, коли ви розкриваєте весь потенціал вашого додатку.
Випадкова проекція (Random Projection)
Основна ідея випадкової проекції полягає в тому, щоб спроектувати вектори високої розмірності в простір нижчої розмірності за допомогою випадкової матриці проекцій. Ми створюємо матрицю випадкових чисел. Розмір матриці буде цільовим значенням низької розмірності, яке ми хочемо отримати. Потім ми обчислюємо точковий добуток вхідних векторів і матриці, в результаті чого отримуємо спроектовану матрицю, яка має меншу розмірність, ніж наші вихідні вектори, але все ще зберігає їхню подібність.
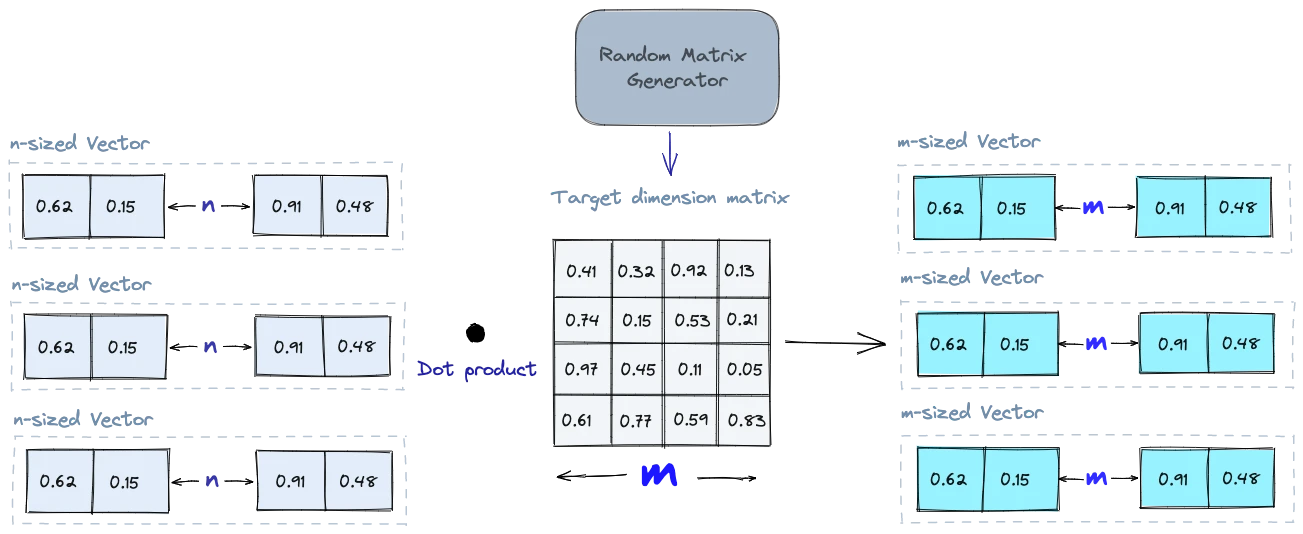
Коли ми робимо запит, ми використовуємо ту саму проекційну матрицю, щоб спроектувати вектор запиту на простір нижчої розмірності. Потім ми порівнюємо спроектований вектор запиту зі спроектованими векторами в базі даних, щоб знайти найближчих сусідів. Оскільки розмірність даних зменшується, процес пошуку відбувається значно швидше, ніж пошук у всьому просторі високої розмірності.
Слід пам'ятати, що випадкове проектування є наближеним методом, і якість проекції залежить від властивостей матриці проектування. Загалом, чим більш випадковою є матриця проекції, тим кращою буде якість проекції. Але генерація дійсно випадкової матриці проекції може бути обчислювально дорогою, особливо для великих наборів даних. Дізнайтеся більше про випадкову проекцію.
Кількісна оцінка продукту
Іншим способом побудови індексу є квантування продукту (PQ), яке є технікою стиснення з втратами для векторів високої розмірності (наприклад, векторних вкладень). Вона бере вихідний вектор, розбиває його на менші частини, спрощує представлення кожної частини шляхом створення репрезентативного "коду" для кожної частини, а потім знову збирає всі частини разом - без втрати інформації, яка є життєво важливою для операцій подібності. Процес PQ можна розбити на чотири етапи: розбиття, навчання, кодування та запит.
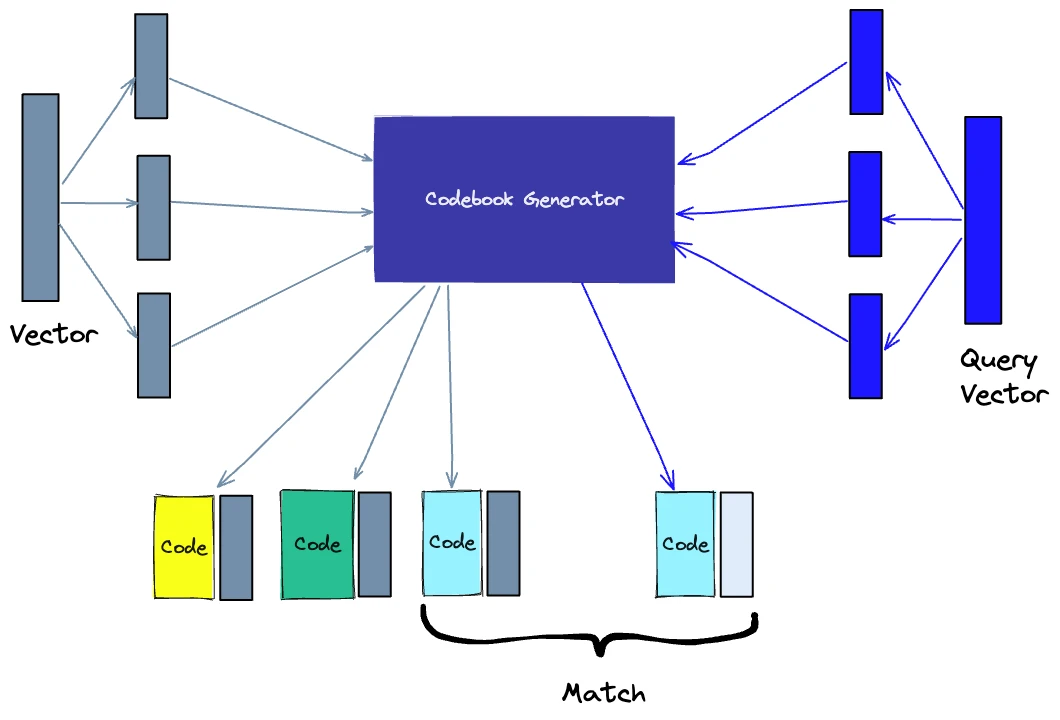
1. Розбиття - вектори розбиваються на сегменти.
2. Навчання - для кожного сегмента ми створюємо "кодову книгу". Простіше кажучи, алгоритм генерує пул потенційних "кодів", які можуть бути присвоєні вектору. На практиці - ця "кодова книга" складається з центральних точок кластерів, створених за допомогою кластеризації за методом k-середніх на кожному з відрізків вектора. Ми матимемо стільки ж значень у кодовій книзі сегментів, скільки значень ми використовуємо для кластеризації за методом k-середніх.
4. Кодування - алгоритм присвоює кожному сегменту певний код. На практиці ми знаходимо найближче значення в кодовій книзі до кожного сегмента вектора після завершення навчання. Наш PQ-код для сегмента буде ідентифікатором відповідного значення в книзі кодів. Ми можемо використовувати стільки PQ-кодів, скільки захочемо, тобто ми можемо вибрати кілька значень з кодової книги для представлення кожного сегмента.
2. Запит - коли ми робимо запит, алгоритм розбиває вектори на підвектори і квантує їх, використовуючи ту ж саму кодову книгу. Потім він використовує проіндексовані коди, щоб знайти найближчі вектори до вектора запиту.
Кількість репрезентативних векторів у книзі кодів є компромісом між точністю представлення та обчислювальними витратами на пошук у книзі кодів. Чим більше репрезентативних векторів у кодовій книзі, тим точніше представлення векторів у підпросторі, але тим вищі обчислювальні витрати на пошук у кодовій книзі. І навпаки, чим менше репрезентативних векторів у кодовій книзі, тим менш точне представлення, але тим менші обчислювальні витрати. Дізнайтеся більше про PQ.
Хешування з урахуванням місцезнаходження
Локально-чутливе хешування (LSH) - це метод індексування в контексті наближеного пошуку найближчого сусіда. Він оптимізований для швидкості, але при цьому дає приблизний, невичерпний результат. LSH зіставляє схожі вектори у "відра" (англ. buckets) за допомогою набору функцій хешування, як показано нижче:
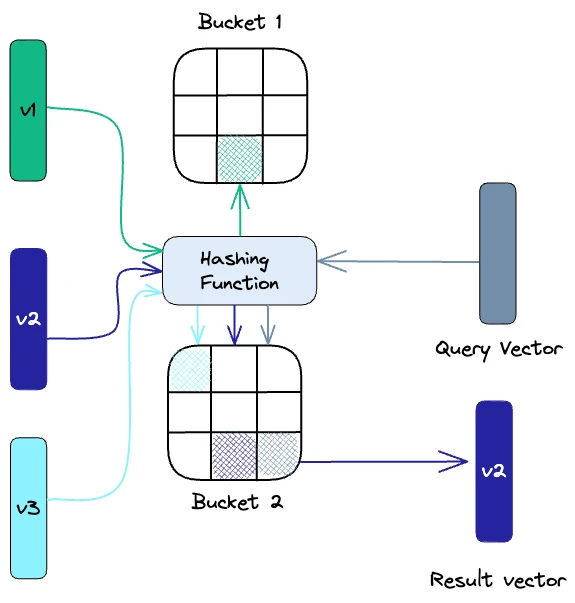
Щоб знайти найближчих сусідів для заданого вектора запиту, ми використовуємо ті ж самі функції хешування, які застосовуються для "занесення" схожих векторів у хеш-таблиці. Вектор запиту хешується до певної таблиці, а потім порівнюється з іншими векторами в тій самій таблиці, щоб знайти найближчі збіги. Цей метод набагато швидший, ніж пошук у всьому наборі даних, оскільки в кожній хеш-таблиці набагато менше векторів, ніж у всьому просторі.
Важливо пам'ятати, що LSH є наближеним методом, і якість наближення залежить від властивостей хеш-функцій. Загалом, чим більше хеш-функцій використовується, тим кращою буде якість наближення. Однак, використання великої кількості хеш-функцій може бути дорогим в обчислювальному плані і може бути нездійсненним для великих наборів даних. Дізнайтеся більше про LSH.
Ієрархічний навігаційний малий світ (HNSW)
HNSW створює ієрархічну деревоподібну структуру, де кожен вузол дерева представляє набір векторів. Ребра між вузлами відображають схожість між векторами. Алгоритм починається зі створення набору вузлів, кожен з яких містить невелику кількість векторів. Це можна зробити випадковим чином або шляхом кластеризації векторів за допомогою алгоритмів на кшталт k-середніх, де кожен кластер стає вузлом.
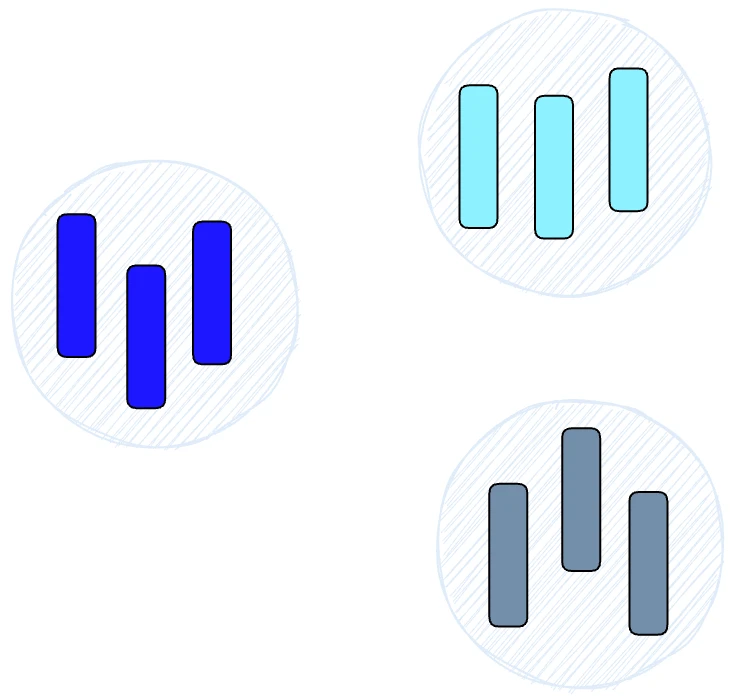
Потім алгоритм досліджує вектори кожної вершини і малює ребро між цією вершиною і вершинами, які мають найбільш схожі вектори з її вектором.
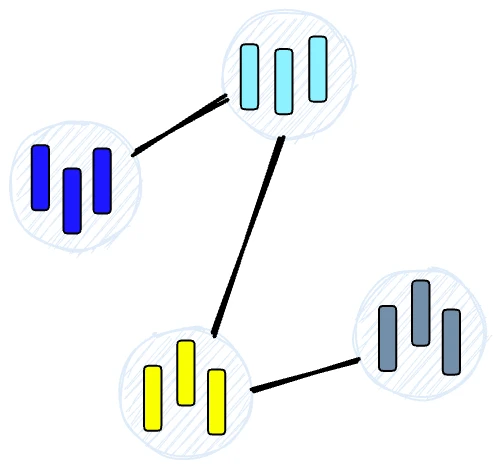
Коли ми запитуємо індекс HNSW, він використовує цей граф для навігації по дереву, відвідуючи вузли, які, швидше за все, містять найближчі вектори до вектора запиту.
Міри схожості
Спираючись на раніше розглянуті алгоритми, нам потрібно зрозуміти роль мір подібності у векторних базах даних. Ці міри є основою того, як векторна база даних порівнює і визначає найбільш релевантні результати для заданого запиту.
Міри подібності - це математичні методи для визначення того, наскільки схожі два вектори у векторному просторі. Міри подібності використовуються у векторних базах даних для порівняння векторів, що зберігаються в базі даних, і знаходження тих, які найбільш схожі на вектор запиту.
Можна використовувати декілька мір подібності, зокрема
1. Косинусна подібність: вимірює косинус кута між двома векторами у векторному просторі. Він знаходиться в діапазоні від -1 до 1, де 1 позначає ідентичні вектори, 0 - ортогональні вектори, а -1 - вектори, які є діаметрально протилежними.
2. Евклідова відстань: вимірює відстань по прямій між двома векторами у векторному просторі. Вона коливається від 0 до нескінченності, де 0 позначає ідентичні вектори, а більші значення - все більш відмінні вектори.
3. Точковий добуток: вимірює добуток величин двох векторів на косинус кута між ними. Він знаходиться в діапазоні від -∞ до ∞, де додатне значення представляє вектори, які спрямовані в одному напрямку, 0 - ортогональні вектори, а від'ємне значення - вектори, які спрямовані в протилежних напрямках.
Вибір міри подібності впливає на результати, отримані з векторної бази даних. Важливо також відзначити, що кожна міра подібності має свої переваги і недоліки, і важливо вибрати правильну міру в залежності від випадку використання і вимог. Дізнайтеся більше про міри схожості.
Фільтрація
Кожен вектор, що зберігається в базі даних, також містить метадані. На додаток до можливості пошуку схожих векторів, векторні бази даних можуть також фільтрувати результати на основі запиту метаданих. Для цього векторна база даних зазвичай підтримує два індекси: індекс вектора та індекс метаданих. Потім вона виконує фільтрацію метаданих або до, або після векторного пошуку, але в будь-якому випадку виникають труднощі, які спричиняють уповільнення процесу виконання запиту.
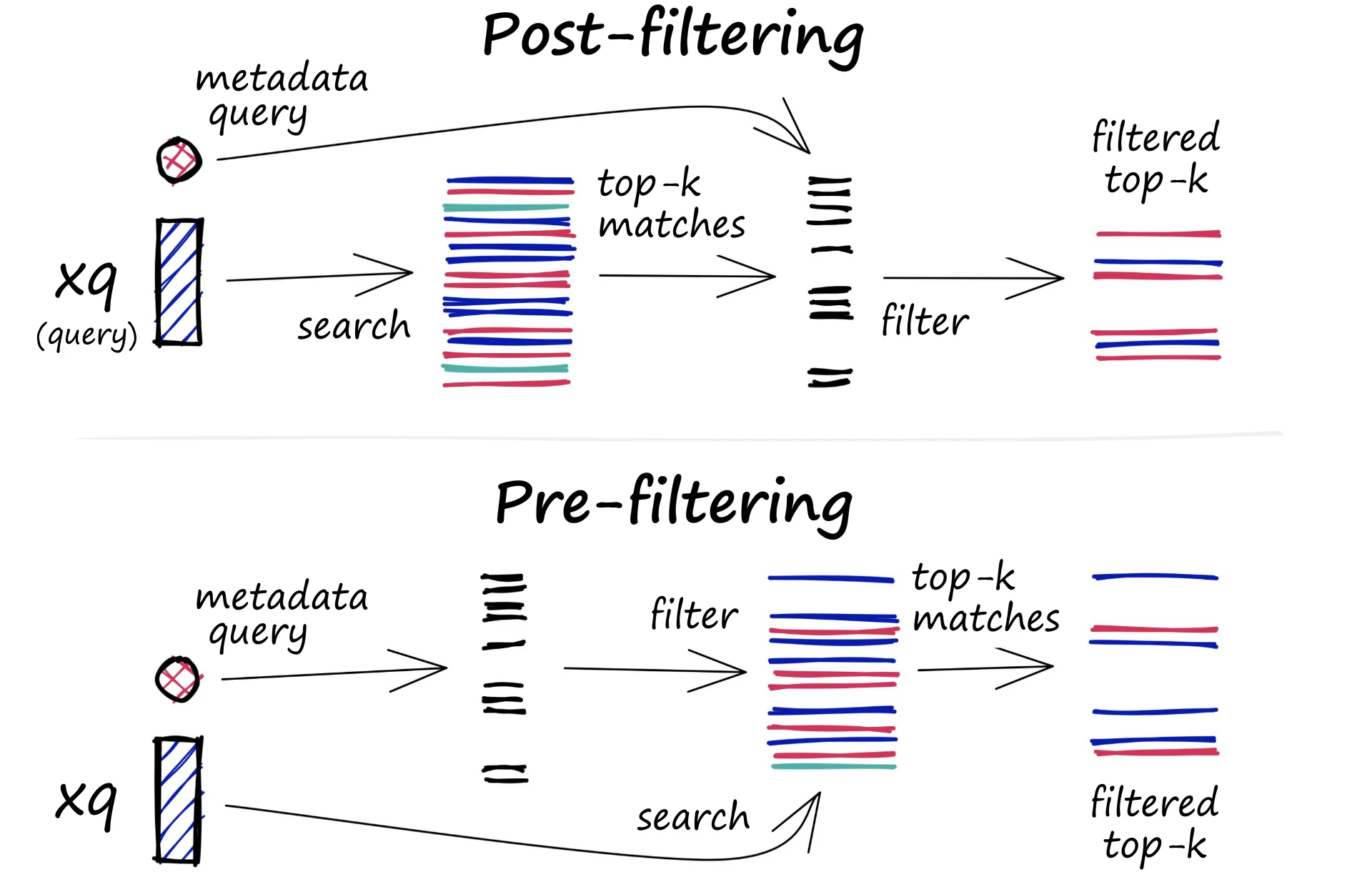
Процес фільтрації може бути виконаний до або після самого векторного пошуку, але кожен підхід має свої особливості, які можуть вплинути на продуктивність запиту:
1. Попередня фільтрація: У цьому підході фільтрація метаданих виконується перед векторним пошуком. Хоча це може допомогти зменшити пошукову область, це також може призвести до того, що система пропустить релевантні результати, які не відповідають критеріям фільтрації метаданих. Крім того, фільтрація метаданих може сповільнити процес пошуку через додаткові обчислювальні витрати.
2. Пост-фільтрація: У цьому підході фільтрація метаданих виконується після векторного пошуку. Це може допомогти забезпечити врахування всіх релевантних результатів, але також може призвести до додаткових накладних витрат і сповільнити виконання запиту, оскільки після завершення пошуку необхідно відфільтрувати нерелевантні результати.
Для оптимізації процесу фільтрації у векторних базах даних застосовуються різні методи, наприклад, використання передових методів індексування метаданих або паралельна обробка для прискорення завдань фільтрації. Баланс між продуктивністю пошуку і точністю фільтрації є важливим для забезпечення ефективних і релевантних результатів запитів у векторних базах даних.
Операції з базами даних
На відміну від векторних індексів, векторні бази даних оснащені набором можливостей, які роблять їх більш придатними для використання у великих масштабах. Розгляньмо загальний огляд компонентів, які беруть участь в роботі з базою даних.
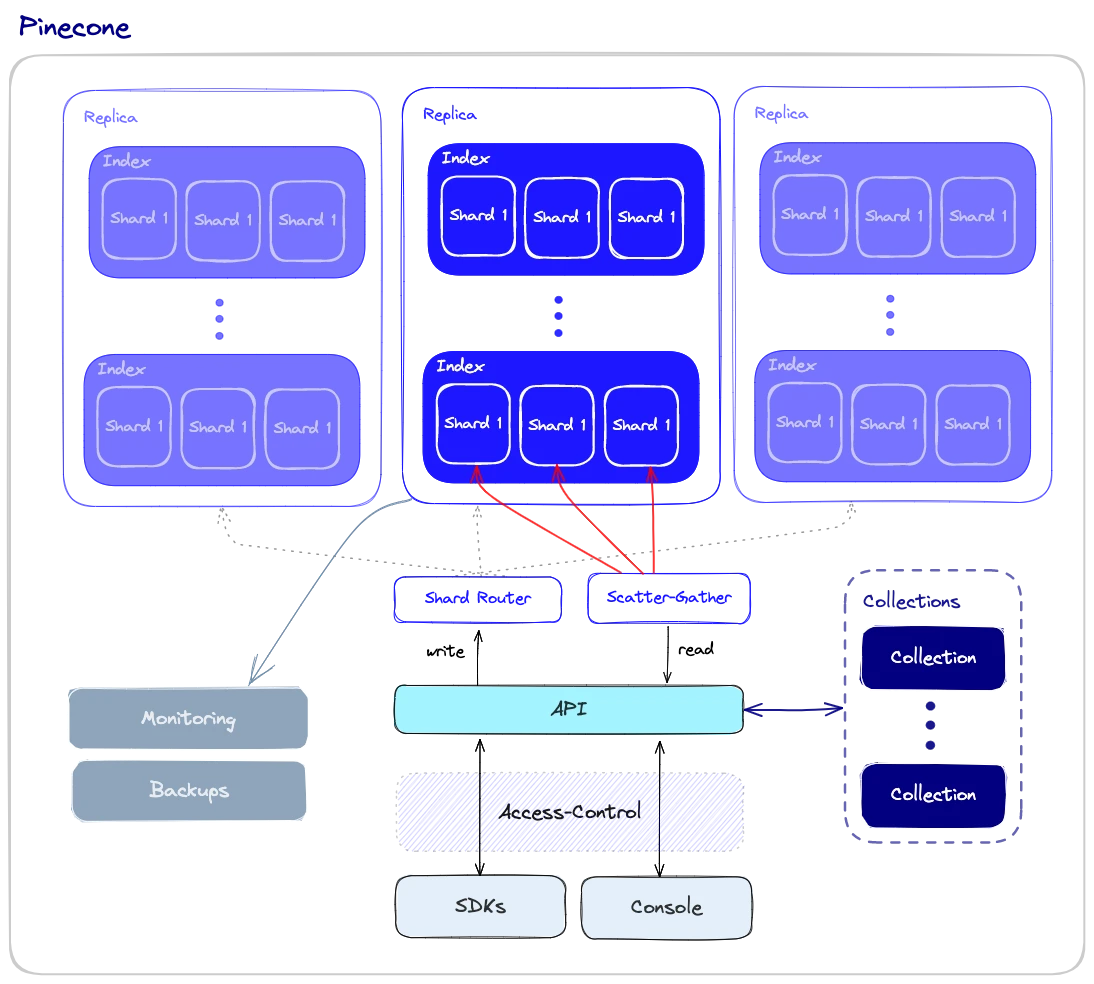
Продуктивність і відмовостійкість
Продуктивність і відмовостійкість тісно пов'язані між собою. Чим більше даних ми маємо, тим більше вузлів потрібно - і тим більша ймовірність помилок і збоїв. Як і у випадку з іншими типами баз даних, ми хочемо гарантувати, що запити будуть виконуватися якомога швидше, навіть якщо деякі з базових вузлів вийдуть з ладу. Це може бути пов'язано з апаратними збоями, збоями в мережі або іншими типами технічних помилок. Такі збої можуть призвести до простою або навіть до неправильних результатів запитів.
Для забезпечення високої продуктивності та відмовостійкості у векторних базах даних застосовують шардінг та реплікацію:
1. Шардинг - розбиття даних на декілька вузлів. Існують різні методи розбиття даних на розділи - наприклад, вони можуть бути розбиті за схожістю різних кластерів даних, щоб схожі вектори зберігалися в одному розділі. Коли робиться запит, він надсилається до всіх шардів, а результати отримуються і об'єднуються. Це називається шаблоном "розкидати-збирати".
2. Реплікація - створення декількох копій даних на різних вузлах. Це гарантує, що навіть якщо певний вузол вийде з ладу, інші вузли зможуть його замінити. Існує дві основні моделі узгодженості: можлива узгодженість і сильна узгодженість. Евентуальна узгодженість допускає тимчасові невідповідності між різними копіями даних, що покращує доступність і зменшує затримки, але може призвести до конфліктів і навіть втрати даних. З іншого боку, сильна узгодженість вимагає, щоб усі копії даних були оновлені до того, як операція запису буде вважатися завершеною. Такий підхід забезпечує більшу узгодженість, але може призвести до більшої затримки.
Моніторинг
Для ефективного управління та підтримки векторної бази даних нам потрібна надійна система моніторингу, яка відстежує важливі аспекти продуктивності, стану та загального стану бази даних. Моніторинг має вирішальне значення для виявлення потенційних проблем, оптимізації продуктивності та забезпечення безперебійних виробничих операцій. Деякі аспекти моніторингу векторної бази даних включають наступне:
1. Використання ресурсів - моніторинг використання ресурсів, таких як процесор, пам'ять, дисковий простір і мережева активність, дозволяє виявити потенційні проблеми або обмеження ресурсів, які можуть вплинути на продуктивність бази даних.
2. Продуктивність запитів - затримка запитів, пропускна здатність і рівень помилок можуть вказувати на потенційні системні проблеми, які потребують вирішення.
3. Стан системи - загальний моніторинг стану системи включає стан окремих вузлів, процес реплікації та інші критичні компоненти.
Контроль доступу
Контроль доступу - це процес управління та регулювання доступу користувачів до даних і ресурсів. Це життєво важливий компонент безпеки даних, який гарантує, що тільки авторизовані користувачі мають можливість переглядати, змінювати або взаємодіяти з конфіденційними даними, що зберігаються в базі даних векторів.
Контроль доступу важливий з кількох причин:
1. Захист даних: Оскільки програми ШІ часто мають справу з чутливою і конфіденційною інформацією, впровадження суворих механізмів контролю доступу допомагає захистити дані від несанкціонованого доступу і потенційних порушень.
2. Відповідність вимогам: У багатьох галузях, таких як охорона здоров'я та фінанси, діють суворі правила конфіденційності даних. Впровадження належного контролю доступу допомагає організаціям дотримуватися цих норм, захищаючи їх від юридичних та фінансових наслідків.
3. Підзвітність та аудит: Механізми контролю доступу дозволяють організаціям вести облік дій користувачів у базі даних векторів. Ця інформація має вирішальне значення для цілей аудиту, а в разі порушення безпеки вона допомагає відстежити будь-який несанкціонований доступ або модифікації.
4. Масштабованість і гнучкість: По мірі зростання та розвитку організації, її потреби в контролі доступу можуть змінюватися. Надійна система контролю доступу дозволяє легко змінювати та розширювати права користувачів, гарантуючи, що безпека даних залишається незмінною протягом усього розвитку організації.
Резервні копії та колекції
Коли все інше не спрацьовує, векторні бази даних пропонують можливість покладатися на регулярно створювані резервні копії. Ці резервні копії можна зберігати на зовнішніх системах зберігання або в хмарних сервісах, забезпечуючи безпеку і можливість відновлення даних. У разі втрати або пошкодження даних, ці резервні копії можуть бути використані для відновлення бази даних до попереднього стану, мінімізуючи час простою та вплив на загальну систему. За допомогою Pinecone користувачі можуть створювати резервні копії окремих індексів і зберігати їх як "колекції", які пізніше можна використовувати для заповнення нових індексів.
API та SDK
Це те місце, де гума зустрічається з дорогою: Розробники, які взаємодіють з базою даних, хочуть робити це за допомогою простого у використанні API, використовуючи звичний і комфортний набір інструментів. Надаючи зручний інтерфейс, рівень API векторних баз даних спрощує розробку високопродуктивних додатків для векторного пошуку.
На додаток до API, векторні бази даних часто надають SDK для конкретної мови програмування, які обгортають API. SDK ще більше спрощують розробникам взаємодію з базою даних у своїх додатках. Це дозволяє розробникам зосередитися на своїх конкретних випадках використання, таких як семантичний пошук тексту, генерація запитань-відповідей, гібридний пошук, пошук схожості зображень або рекомендацій щодо продуктів, не турбуючись про складності базової інфраструктури.
Підсумок
Експоненціальне зростання векторних вбудовувань у таких галузях, як НЛП, комп'ютерний зір та інші додатки ШІ, призвело до появи векторних баз даних як обчислювального рушія, що дозволяє нам ефективно взаємодіяти з векторними вбудовуваннями в наших додатках.
Векторні бази даних - це спеціально створені бази даних, які спеціалізуються на вирішенні проблем, що виникають при управлінні векторними вбудовуваннями у виробничих сценаріях. З цієї причини вони мають значні переваги над традиційними скалярними базами даних та окремими векторними індексами.
У цій статті ми розглянули ключові аспекти векторної бази даних, включаючи те, як вона працює, які алгоритми в ній використовуються, а також додаткові функції, які роблять її готовою до використання у виробничих сценаріях. Ми сподіваємося, що це допоможе вам зрозуміти внутрішню роботу векторних баз даних. На щастя, це не те, що вам потрібно знати, щоб використовувати Pinecone. Pinecone бере на себе всі ці (і не тільки) міркування і дозволяє вам зосередитися на решті частини вашого додатку.

Ще немає коментарів