WebPack — це дуже потужний і цікавий інструмент, який можна вважати фундаментом багатьох сучасних технологій для веброзробки. Однак налаштувати WebPack і працювати з ним не завжди легко.
У цій статі ми поділимося подробицями про роботу та конфігурування webpack. Ви дізнаєтеся, як працює ледаче завантаження, як очистити дерево файлів, як працюють деякі завантажувачі тощо. Головна мета цієї статті — подолати проблеми, пов'язані з webpack, і ретельно розібратись із усім процесом налагоджування.
Візуалізація процесу за допомогою діаграми
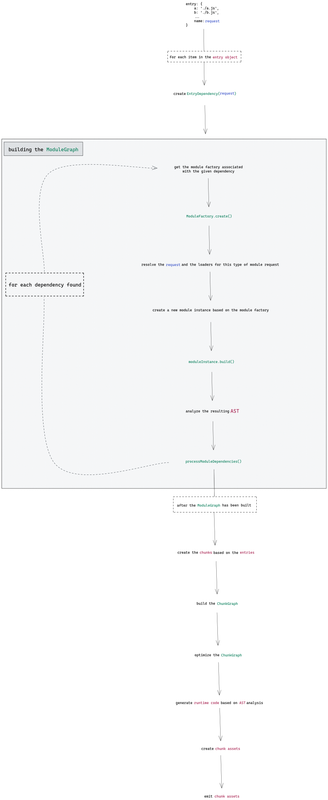
Ви можете переглянути цю діаграму в Excalidraw. А оскільки стаття постійно посилатиметься на неї, так вам буде зручніше дивитись на неї під час читання.
Що ж, почнімо!
Об'єкт entry
Все починається з об'єкта entry. Очікувано, що він підтримує багато конфігурацій. Ми розглянемо тут найпростіший приклад, у якому об'єкт entry — це лише набір пар ключ-значення:
/ webpack.config.js
entry: {
\ta: './a.js',
\tb: './b.js',
\t/* ... */
}
По суті модуль у webpack асоціюється з файлом. На діаграмі 'a.js' і 'b.js' отримають по новому власному модулю. Наразі досить пам'ятати, що модуль є оновленою версією файлу.
Створений і побудований модуль, крім джерельного коду, містить багато важливих даних, наприклад: використовувані завантажувачі, його залежності, експорт (якщо він є), хеш та багато іншого. Кожен елемент об'єкта entry можна розглядати як кореневий модуль у дереві модулів. Для кореневого модуля можуть знадобитися інші модулі (які можна назвати залежностями), тож дерево модулів для них може потребувати інших модулів і так до нескінченності. Саме так і будуються дерева вищого рівня. Усі ці дерева модулів зберігаються разом у ModuleGraph, який ми розглянемо у наступному розділі.
Далі, webpack побудований з використанням багатьох плагінів. Хоч процес групування і добре налагоджений, існує багато способів додати власну логіку. Розширення функціональності у webpack реалізується за допомогою хуків. Наприклад, ви можете додати власну логіку після побудови ModuleGraph, коли новий ресурс було згенеровано для фрагмента, але до того, як модуль буде вбудовуватися (запускаються завантажувачі та аналізується джерельний код) тощо.
Здебільшого хуки групуються за призначенням і для будь-якого чітко визначеного завдання існує плагін. Наприклад, є плагін, який відповідає за обробку функції import() (відповідає за синтаксичний аналіз коментарів та аргументів). Він називається ImportParserPlugin, а єдине його завдання додавати хук, коли виклик import() виникає під час синтаксичного аналізу AST.
Не дивина, що існує пара плагінів, які відповідають за роботу з об'єктом entry. Є EntryOptionPlugin, який бере об'єкт entry і створює EntryPlugin для кожного елемента в об'єкті. Ця частина важлива і також пов'язана з тим, що було зазначено на початку цього розділу: кожен елемент об'єкта entry перетворюється на дерево модулів (всі ці дерева відокремлені одне від одного). EntryPlugin починає створення дерева модулів, кожне з яких додаватиме інформацію до одного й того ж місця — ModuleGraph. Неодноразово ми бачитимемо, як EntryPlugin розпочинає цей складний процес.
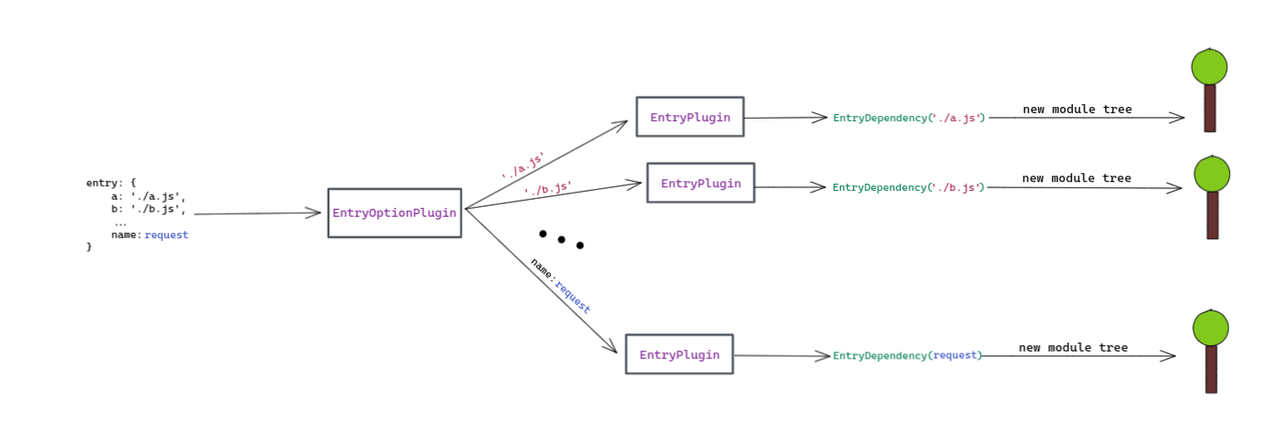
Щоб узгодити це з початковою діаграмою, згадаємо, що EntryPlugin також є місцем, де створюється EntryDependency.
На основі згаданої діаграми розгляньмо, наскільки важливим є EntryOptionsPlugin, на прикладі:
class CustomEntryOptionPlugin {
// Це стандартний спосіб створення плагінів.
// Це радше проста функція, але ми використовуємо цей підхід,
// щоб зрозуміти, як створюються більшість плагінів.
apply(compiler) {
// Повторний виклик цих хуків дозволяє нам впливати
// на процес пов'язування.
// За допомогою хука `entryOption` ми додаємо логіку,
// що означатиме початок процесу пов'язування. Тобто
// аргумент `entryObject` міститиме об'єкт `entry` з
// файлу конфігурації, і ми будемо використовувати його для
// створення модульних дерев.
compiler.hooks.entryOption.tap('CustomEntryOptionPlugin', entryObject => {
\t\t\t// Клас `EntryOption` оброблятиме створення модульного дерева.
const EntryOption = class {
constructor (options) {
this.options = options;
};
// Оскільки це все ж таки плагін, ми дотримуємось стандарту.
apply(compiler) {
// Хук `start` позначає початок пов'язування.
// Він викликатиметься **після** виклику hooks.entryOption`.
compiler.hooks.start('EntryOption', ({ createModuleTree }) => {
// Створення нового дерева модулів, заснованих на конфігурації цього плагіну.
// `Параметри` містять назву запису (яка, по суті, є назвою частки коду)
// та назву файлу.
// `EntryDependency` інкапсулює ці параметри, а також забезпечує спосіб
// створення модулів (оскільки він є картою до `NormalModuleFactory`, який продукує `NormalModule`).
// Після виклику `createModuleTree`, буде знайдено початковий код файлу,
// потім буде створений екземпляр модуля, а потім webpack отримає свій AST, котрий
// буде додатково використано у процесі пов'язування.
createModuleTree(new EntryDependency(this.options));
});
};
};
// Для кожного елемента в `entryObject` ми готуємося до
// створення дерева модулів. Пам'ятайте, що кожне
// дерево модулів незалежне одне від одного.
// `entryObject` може бути схожим на такий вираз: `{ a: './a.js' }`
for (const name in entryObject) {
const fileName = entryObject[name];
// Умовно ми кажемо: `ok, webpack, коли почнеться процес пов'язування,
// будь готовий створити дерево модулів для цього запису`.
new EntryOption({ name, fileName }).apply(compiler);
};
});
}
};
В останній частині цього розділу ми докладніше розглянемо, що таке Dependency (залежність), тому що ми будемо використовувати її далі в цій статті. Тепер вам може бути цікаво, що таке EntryDependency і навіщо вона потрібна.
Усе зводиться до розумної абстракції, коли справа доходить до створення нових модулів. Простіше кажучи, залежність — це лише підготовка до фактичного екземпляра модуля. Наприклад, навіть елементи об'єкта entry — це залежності з погляду Webpack, і вони вказують необхідний мінімум для створення екземпляра модуля, а саме його шлях (наприклад ./a.js, ./b.js).
Створення модуля не може розпочатися без залежності, оскільки серед інших важливих даних залежність містить запит модуля. Це шлях до файлу, де можна знайти джерело модуля (наприклад, './a.js'). Залежність також вказує, як побудувати цей модуль, і це робиться за допомогою module factory. Вона знає, як почати роботу з початкового стану (наприклад, початкового коду, який є простим рядком) і дійти до конкретних сутностей, які потім використовуватиме webpack.
EntryDependency насправді є типом ModuleDependency, тобто він обов'язково міститиме запит модуля, а module factory, на яку вона указує, — це NormalModuleFactory. Тоді NormalModuleFactory точно знає, що робити, аби створити щось значуще для webpack лише зі шляху. Іншими словами: спочатку модуль був лише простим шляхом (або в об'єкті entry, або в частині оператора import), потім він став залежністю, а потім, нарешті, модулем. Схематично це має такий вигляд:
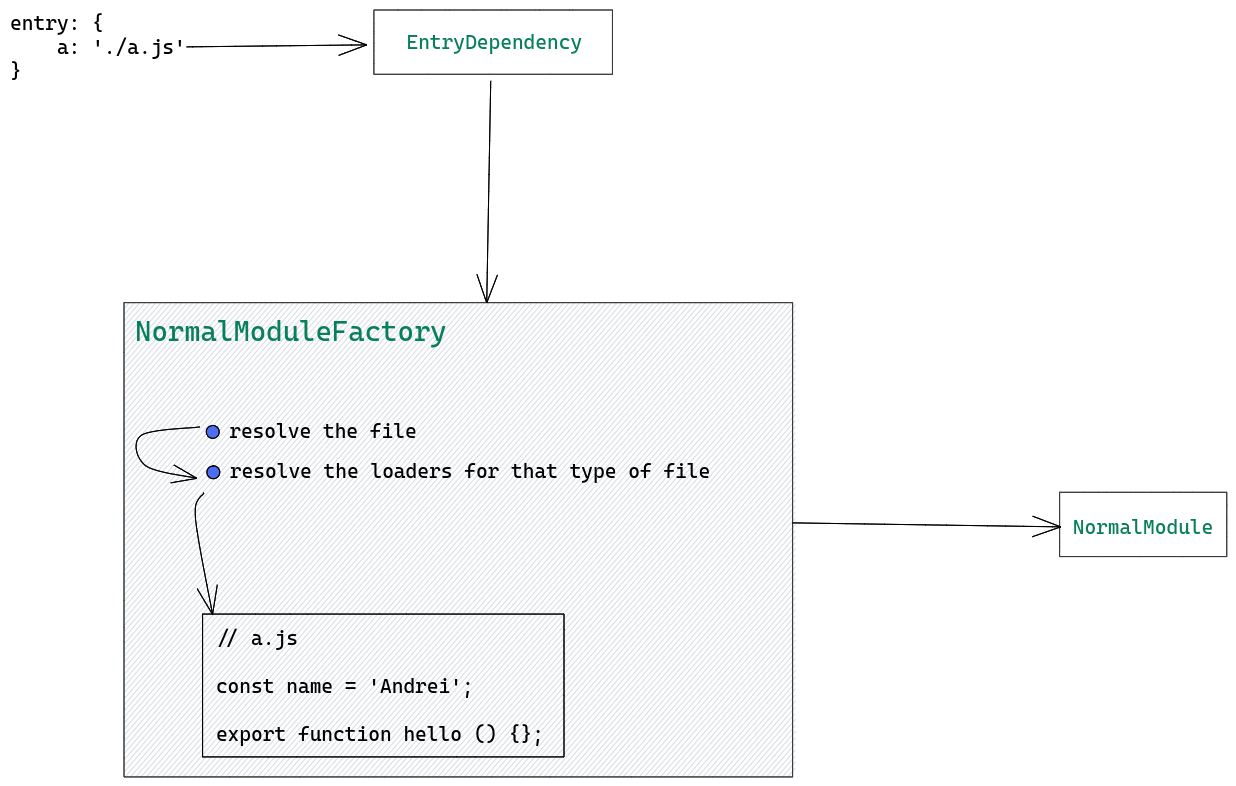
Посилання на діаграму Excalidraw тут.
Отже, EntryDependency використовується на початку, при створенні кореневого модуля дерева модулів.
Для решти модулів існують інші типи залежностей. Наприклад, якщо ви використовуєте оператор import, як-от import defaultFn from './a.js', тоді існуватиме HarmonyImportSideEffectDependency, що містить запит модуля (в цьому випадку './a.js'), а також карта до NormalModuleFactory. Отже, з'явиться новий модуль для файлу 'a.js'. Тепер ви розумієте наскільки важливу роль, яку відіграють залежності. Вони надають інструкції для webpack щодо створення модулів. Детальніше про залежності ми розповімо трохи згодом.
Коротко підсумуємо цей розділ: для кожного елемента в об'єкті entry, з'явиться екземпляр EntryPlugin, де створюється EntryDependency. EntryDependency міститиме запит модуля (тобто шлях до файлу), а також надає можливість зробити цей запит корисним — через синтаксичний аналіз NormalModuleFactory. Він знає, як сформувати суб'єкти, корисні для webpack, використовуючи лише шлях.
Знову ж таки, залежність має вирішальне значення для створення модуля, оскільки вона містить важливу інформацію, наприклад, запит модуля та спосіб обробки цього запиту. Є кілька типів залежностей, і не всі вони корисні для створення нового модуля. З кожного екземпляра EntryPlugin та за допомогою нещодавно створеного EntryDependency буде створено дерево модулів. Дерево модуля будується з модулів та їхніх залежностей, які також є модулями й також можуть мати залежності.
Тепер розгляньмо докладніше ModuleGraph.
Що таке ModuleGraph
ModuleGraph — це спосіб відстежувати побудовані модулі. Він дуже покладається на залежності. Вони забезпечують йому способи під'єднання 2 різних модулів. Наприклад:
// a.js
import defaultBFn from '.b.js/';
// b.js
export default function () { console.log('Hello from B!'); }
Тут маємо 2 файли, а отже і 2 модулі. Файл a вимагає чогось від файлу b, тому він має залежність, яка встановлюється інструкцією import. Оскільки під'єднано ModuleGraph, залежність визначає спосіб під'єднання 2 модулів. Навіть EntryDependency з попереднього розділу з'єднує 2 модулі: кореневий модуль графіку, який ми назвемо нульовим модулем, та модуль, пов'язаний з файлом вводу. Наведений фрагмент можна візуалізувати так:

Важливо зрозуміти різницю між простим модулем (тобто екземпляром NormalModule) та модулем, що належить до ModuleGraph. Вузол ModuleGraph називається ModuleGraphModule, і це просто екземпляр NormalModule з декоратором. ModuleGraph відстежує ці модулі з декораторами за допомогою карти з підписом Map<Module, ModuleGraphModule>.
Ці аспекти необхідно згадати, бо якщо є лише екземпляри NormalModule, то з ними мало що можна зробити, вони не знають, як взаємодіяти одне з одним. ModuleGraph надає значення цим чистим модулям, з'єднуючи їх за допомогою згаданої карти, яка призначає кожному NormalModule по ModuleGraphModule.
Усе це стане зрозумілішим після розділу про побудову ModuleGraph, де ми будемо використовувати ModuleGraph та його внутрішню карту. Ми називатимемо модуль, який належить до ModuleGraph, просто модулем, оскільки різниця лише у кількох додаткових властивостях.
Для вузла, що належить до ModuleGraph, є кілька визначених речей: вхідні з'єднання та вихідні з'єднання. З'єднання — це ще одна невелика сутність ModuleGraph, і вона містить важливі дані, як-от: модуль походження, модуль призначення та залежність, яка з'єднує 2 належних модулі. Тобто, виходячи з наведеної діаграми, було створено нове з'єднання:
// Базується на діаграмі та наведеному вгорі фрагменті.
Connection: {
\toriginModule: A,
\tdestinationModule: B,
\tdependency: ImportDependency
}
Указане з'єднання теж буде додано до набору A.outgoingConnections та до набору B.incomingConnections.
Це основні поняття ModuleGraph. Як уже згадувалося в попередньому розділі, усі дерева модулів, створені із записів, будуть виводити важливі дані в одне й те ж місце, — ModuleGraph. Це пояснюється тим, що всі ці дерева модулів з часом будуть з'єднані з нульовим модулем (кореневим модулем ModuleGraph).
З'єднання з нульовим модулем встановлюється за допомогою EntryDependency та модуля, створеного з вхідного файлу. Ось як можна уявити ModuleGraph:
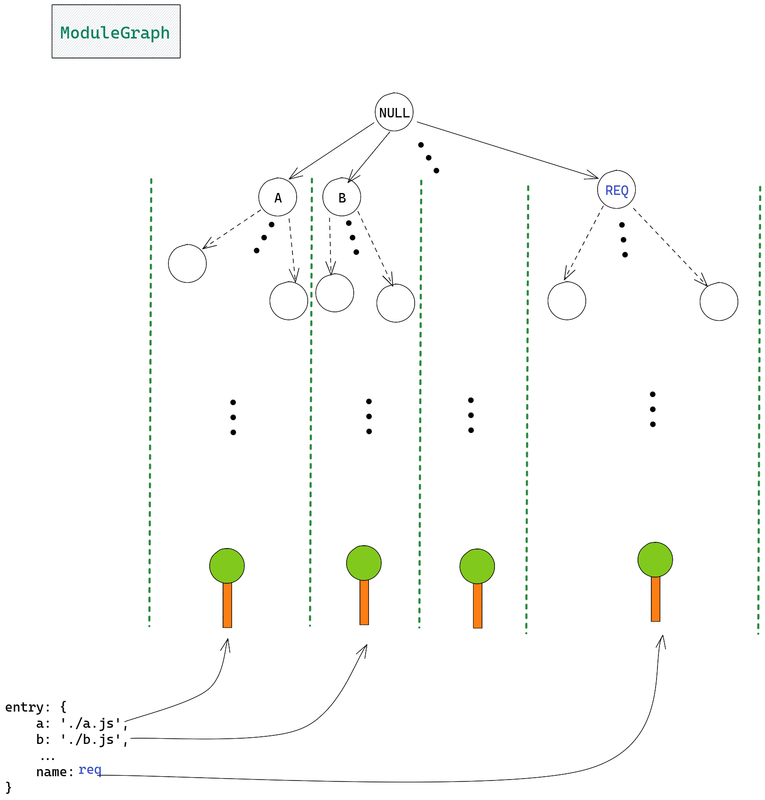
Ось посилання на цю діаграму на Excalidraw. Зауважте: ця діаграма не базується на попередньому прикладі.
Як бачите, нульовий модуль має з'єднання з кореневим модулем кожного дерева модуля, згенерованого з елемента в об'єкті entry. Кожен край у графіку — це зв'язок між 2 модулями, і кожне з'єднання містить дані про початковий вузол, призначення вузла та залежність (яка неформально відповідає на запитання, чому ці 2 модулі під'єднані).
Тепер, коли ми трохи більше знайомі з ModuleGraph, час дізнатися, як він побудований.
Побудова ModuleGraph
Як ми дізналися у попередньому розділі, ModuleGraph починається з нульового модуля. Його прямі нащадки — це кореневі модулі дерев модулів, які були побудовані з елементів об'єктів entry. З цієї причини, щоб зрозуміти побудову ModuleGraph, ми розглянемо створення єдиного дерева модулів.
Модулі, котрі будуть створені першими
Почнемо з дуже простого об'єкта entry:
entry: {
\ta: './a.js',
}
З першого розділу ми знаємо, що в якийсь момент отримаємо EntryDependency, запитом якого є './a.js'. Ця залежність EntryDependency надає спосіб створити щось важливе з цього запиту, оскільки вона посилається на NormalModuleFactory. Це ми розглянули у першому розділі.
Далі на сцені з'являється NormalModuleFactory. Якщо вона успішно виконає своє завдання, то створить NormalModule.
NormalModule — це просто десеріалізована версія початкового коду файлу, яка є звичайним рядком. Цей рядок не має великого значення, тому webpack небагато чого може з ним зробити.
NormalModule також зберігатиме початковий код у вигляді рядка, але водночас він міститиме й інші важливі дані та функціональні можливості, наприклад: завантажувачі, застосовані до нього, логіку побудови модуля, логіку генерації середовища виконання коду, його хеш-значення та багато іншого. Іншими словами, NormalModule — це корисна версія простого необробленого файлу, з погляду webpack.
Щоб NormalModuleFactory повернув NormalModule, він повинен виконати кілька кроків. Існує також кілька речей, які повинні виконатися після створення модулів, наприклад, побудова модуля та обробка його залежностей, якщо вони є.
Ось частина нашої діаграми, зосереджена на побудові ModuleGraph:
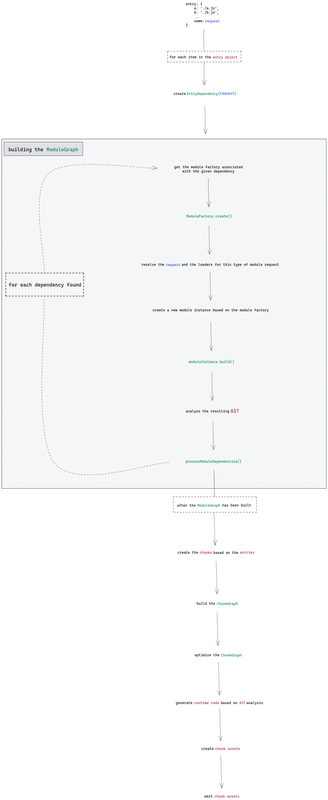
NormalModuleFactory запускає свою магію, викликом методу create. Потім починається процес розв'язування. Саме тут розв'язується запит (шлях файлу), а також завантажувачі для цього типу файлу. Зверніть увагу, що буде визначено лише шляхи файлів завантажувачів, але вони ще не викликаються на цьому етапі.
Процес побудови модуля
Після того, як всі необхідні шляхи файлів були розв'язані, створюється NormalModule. Однак у цей момент модуль ще не має цінності. Багато потрібних даних надійде після побудови модуля. Процес побудови NormalModule складається з кількох інших кроків:
- По-перше, завантажувачі будуть викликані з вихідного коду; якщо є кілька завантажувачів, то вивід одного завантажувача може бути вводом для іншого (важливий порядок, у якому завантажувачі вказані у файлі конфігурації).
- По-друге, отриманий після виконання всіх завантажувачів рядок буде повернено з acorn (парсер JavaScript), який дає AST даного файлу.
- Нарешті, проаналізується AST. Такий аналіз потрібен, оскільки під час виконання цього етапу визначаться залежності поточного модуля (наприклад, інші модулі), webpack може виявити його магічні функції (наприклад,
require.context,module.hot). Аналіз AST відбувається уJavascriptParser, і якщо ви натиснете посилання, ви побачите, що там обробляється багато випадків. Ця частина одна з найважливіших, тому що він неї залежить багато подальших процесів.
Виявлення залежностей через отримане синтаксичне дерево (AST)
Виявлення залежностей відбувається приблизно за такою схемою:
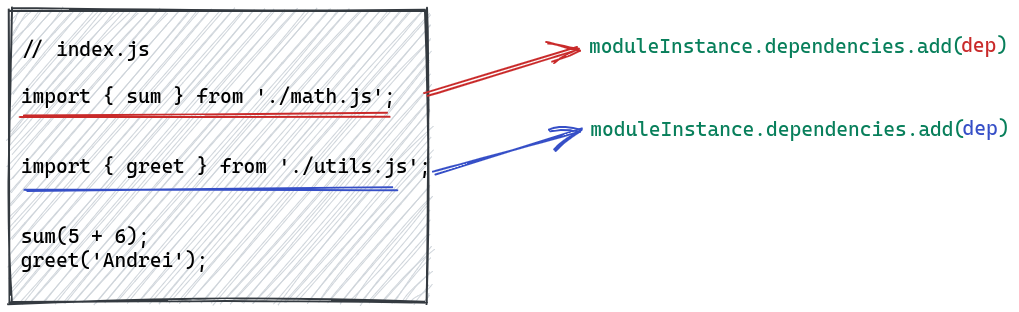
Тут moduleInstance посилається на NormalModule, створений з файлу index.js. dep, виділений червоним кольором, посилається на створену з першого твердження import залежність, а dep синього кольору — на друге твердження import. Це спрощена схема. Насправді залежності додаються після отримання AST.
Тепер, коли розглянуто AST, саме час продовжити створення дерева модуля. Наш наступний крок — обробка залежностей, які були виявлені на попередньому етапі.
Якщо поглянути на діаграму згори, ми побачимо, що модуль index має 2 залежності, які також є модулями: math.js та utils.js. Але до того, як залежності фактично стануть модулями, ми маємо лише модуль index. Його module.dependencies має 2 значення, які містять дані, такі як запит модуля (шлях файлу), специфікатор імпорту (наприклад, sum, greet). Щоб перетворити їх на модулі, ми повинні використовувати ModuleFactory, до якого ведуть ці залежності, та повторити описані раніше кроки (повторення позначається пунктирною стрілкою на діаграмі, показаній на початку цього розділу).
Після обробки поточних залежностей модуля, вони також можуть отримати залежності, і цей процес триватиме, допоки не зникнуть залежності. Так будується дерево модуля, хоча, звичайно, варто переконатися, що зв'язки між батьківськими та дочірніми модулями встановлюються як слід.
Тепер, коли ми все це знаємо, можемо поекспериментувати з ModuleGraph. Для цього розгляньмо спосіб реалізації спеціального плагіну, який дасть нам змогу пройтися по ModuleGraph. На діаграмі можна побачити, як модулі залежать один від одного:
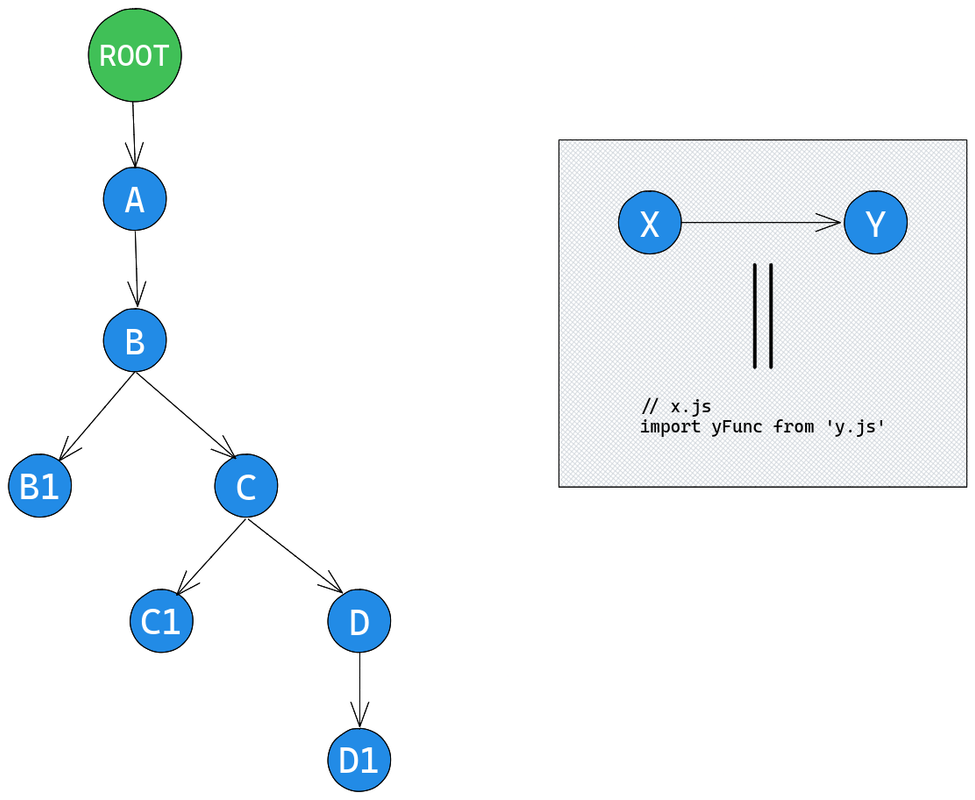
Переконаоємося, чи на діаграмі все зрозуміло. Файл a.js імпортує файл b.js, який імпортує і b1.js, і c.js. Потім c.js імпортує c1.j і d.js, і, врешті, d.js імпортує d1.js. Нарешті, ROOT посилається на нульовий модуль, котрий є коренем ModuleGraph. Параметри entry складаються лише з одного значення — a.js:
// webpack.config.js
const config = {
entry: path.resolve(__dirname, './src/a.js'),
\t/* ... */
};
Тепер подивімося, яким буде наш кастомний плагін:
// Спосіб, у який ми додаємо логіку до наявного хука webpack
// за допомогою методу `tap`, який має цей підпис:
// `tap(string, callback)`
// де основне завдання `string` — це налагодження, що вказує
// на джерело, з якого було додано кастомну логіку.
// Аргумент `callback` залежить від хука, у якому ми додаємо кастомну
// функціональність.
class UnderstandingModuleGraphPlugin {
apply(compiler) {
const className = this.constructor.name;
// Об'єкт `compilation`: тут зберігається більша частина *стану*
// процесу пов'язування. Він містить таку інформацію, як модуль graph,
// фрагменти (chunk) graph, створені фрагменти й модулі, згенеровані активи
// та багато іншого.
compiler.hooks.compilation.tap(className, (compilation) => {
// `finishModules` викликається після побудови *усіх* модулів(включно з
// їхніми залежностями та залежностями всіх залежностей)
compilation.hooks.finishModules.tap(className, (modules) => {
// `modules` — набір, який містить усі побудовані модулі.
// Це просто екземпляри `NormalModule`. Повторимо, `NormalModule`
// створюється у `NormalModuleFactory`.
// console.log(modules);
// Отримання **карти модуля**(Map<Module, ModuleGraphModule>).
// містить всю інформацію, необхідну для передавання graph.
const {
moduleGraph: { _moduleMap: moduleMap },
} = compilation;
// Передаємо модуль graph у формі DFS.
const dfs = () => {
// Нагадаємо, що модуль root (кореневий) `ModuleGraph` — це
// *null module* (нульовий модуль).
const root = null;
const visited = new Map();
const traverse = (crtNode) => {
if (visited.get(crtNode)) {
return;
}
visited.set(crtNode, true);
console.log(
crtNode?.resource ? path.basename(crtNode?.resource) : 'ROOT'
);
// Отримання пов'язаного `ModuleGraphModule`, який має лише додаткові
// властивості, крім `NormalModule`, які ми можемо використовувати для передавання graph далі.
const correspondingGraphModule = moduleMap.get(crtNode);
// На `originModule` з `Connection` починається стрілка,
// а на `module` з `Connection` стрілка закінчується.
// Отже, `module` з `Connection` — це дочірній вузол.
// Тут ви можете знайти більше про з'єднання graph: https://github.com/webpack/webpack/blob/main/lib/ModuleGraphConnection.js#L53.
// `correspondingGraphModule.outgoingConnections` буде або Set, або undefined(якщо вузол не має дочірніх вузлів).
// Ми використовуємо `new Set` оскільки модуль може посилатися на той самий модуль через кілька з'єднань.
// Наприклад, `import foo from 'file.js'` повернеться за 2 з'єднання: одне для простого імпорту,
// а одне для типового специфікатора `foo`. Це деталь імплементації, про яку вам не варто турбуватися.
const children = new Set(
Array.from(
correspondingGraphModule.outgoingConnections || [],
(c) => c.module
)
);
for (const c of children) {
traverse(c);
}
};
// Починається передавання.
\t\t\t\t\ttraverse(root);
};
dfs();
});
});
}
}
Приклад, який ми наслідуємо зараз, можна знайти у застосунку StackBlitz. Обов'язково запустіть npm run build, щоб побачити плагін у роботі. Ґрунтуючись на ієрархії модулів, після запуску команди build ми повинні отримати такий результат:
a.js
b.js
b1.js
c.js
c1.js
d.js
d1.js
Тепер, коли ModuleGraph створено і ми докладно з ним розібрались, саме час дізнатися, що відбуватиметься далі. Згідно з основною діаграмою, наступний крок — створення фрагментів (chunk), тож переходимо до них. Але перш ніж це зробити, варто уточнити деякі важливі поняття, зокрема Chunk, ChunkGroup і EntryPoint.
Що таке Chunk, ChunkGroup, EntryPoint
Тепер ми краще розуміємо, що таке модулі, тож швиденько розглянемо поняття з назви цього розділу. Достатньо знати, що модуль — це покращена версія файлу. Створений і побудований модуль містить багато значущої інформації, крім початкового коду. Наприклад: використовувані завантажувачі, його залежності, експорт (якщо є), його хеш тощо.
Chunk, або фрагмент, інкапсулює модуль або модуль модулів. Може здатися, що кількість файлів запису (файл запису = елемент об'єкта entry) пропорційна кількості отриманих фрагментів. Це частково правда, оскільки об'єкт entry може мати лише один елемент, а кількість отриманих фрагментів може бути більшою за одиницю.
Правда й те, що кожен елемент entry матиме відповідний фрагмент у каталозі dist. Однак інші фрагменти можуть бути створені неявно, наприклад, функцією import(). Але незалежно від того, як його створено, кожен фрагмент матиме відповідний файл у каталозі dist. Ми розповімо про це в розділі про побудову ChunkGraph, де уточнимо, які модулі будуть належати до chunk, а які ні.
ChunkGroup містить один або більше фрагментів. ChunkGroup може бути батьківською або дочірньою щодо іншої ChunkGroup. Наприклад, під час динамічного імпорту для кожної використовуваної функції import() створиться ChunkGroup. Її батьківським елементом буде наявна ChunkGroup, яка містить файл (тобто модуль), в якому застосовуються функції import(). Візуалізацію цього можна побачити у розділі про побудову ChunkGraph.
EntryPoint — це тип ChunkGroup, що створюється для кожного елемента об'єкта entry. Оскільки фрагмент належить до EntryPoint, він впливає на процес рендерингу.
Тепер продовжимо і розберемося з ChunkGraph.
Побудова ChunkGraph
Нагадаємо, що до цього моменту ми маємо просто ModuleGraph з попереднього розділуі. Однак ModuleGraph — це лише частина процесу пов'язування й один із засобів для, наприклад, розділення коду.
На цьому етапі процесу пов'язування для кожного елемента з об'єкта entry існуватиме EntryPoint. Оскільки це тип ChunkGroup, він міститиме принаймні один фрагмент. Отже, якщо об'єкт entry має 3 елементи, буде 3 екземпляри EntryPoint, кожен з яких має фрагмент, також званий фрагментом точки входу. Його назва — це значення ключа елемента entry. Модулі, пов'язані з файлами входу, називаються модулями входу, і кожен з них належатиме до свого фрагмента точки входу. Вони важливі, оскільки це відправні точки процесу побудови ChunkGraph. Зауважте, що фрагмент може мати більше одного модуля входу:
// webpack.config.js
entry: {
foo: ['./a.js', './b.js'],
},
У наведеному прикладі є фрагмент з назвою foo (ключ елемента). Він має 2 модулі введення: один, пов'язаний з файлом a.js, а інший — з файлом b.js. І, звичайно, фрагмент належатиме до екземпляра EntryPoint, створеного на основі елемента entry.
Перш заглибитися в деталі, створімо приклад, щоб обговорити процес побудови:
entry: {
foo: [path.join(__dirname, 'src', 'a.js'), path.join(__dirname, 'src', 'a1.js')],
bar: path.join(__dirname, 'src', 'c.js'),
},
Цей приклад охоплюватиме все згадане раніше: батьківські-дочірні зв'язки у ChunkGroups (а, отже, динамічний імпорт), фрагменти та EntryPoints.
Можете ознайомитися з цим прикладом тут. Діаграма, з якою ми далі працюватимемо побудована на основі нього.
ChunkGraph побудований рекурсивним способом. Він починається з додавання всіх модулів входу до черги. Коли модуль входу буде оброблено, це означатиме, що його залежності (які також є модулями) перевіряться. Кожна залежність також буде додана до черги. Так триватиме, поки у черзі не залишиться елементів.
Це етап перевірки модулів, однак це лише перша частина процесу. Нагадаємо, що ChunkGroup може бути батьківським або дочірнім для інших ChunkGroup. Ці зв'язки розв'язуються у другій частині.
Наприклад, динамічний імпорт (тобто функція import()) призведе до створення нової дочірньої групи ChunkGroup. Говорячи мовою webpack, вираз import() визначить асинхронний блок залежностей. У випадку import('./foo.js'.then(module => ...) зрозуміло, що ми збираємося завантажити щось асинхронно. Очевидно, що для використання змінної module необхідно розв'язати всі залежності (тобто модулі) foo (включно з самим foo), перш ніж власне модуль стане доступним.
Якщо вам цікаво, ось тут створюється блок під час аналізування AST.
Джерельний код, що узагальнює процес побудови ChunkGraph розміщено тут.
Тепер розгляньмо діаграму ChunkGraph, створену за допомогою нашої конфігурації:
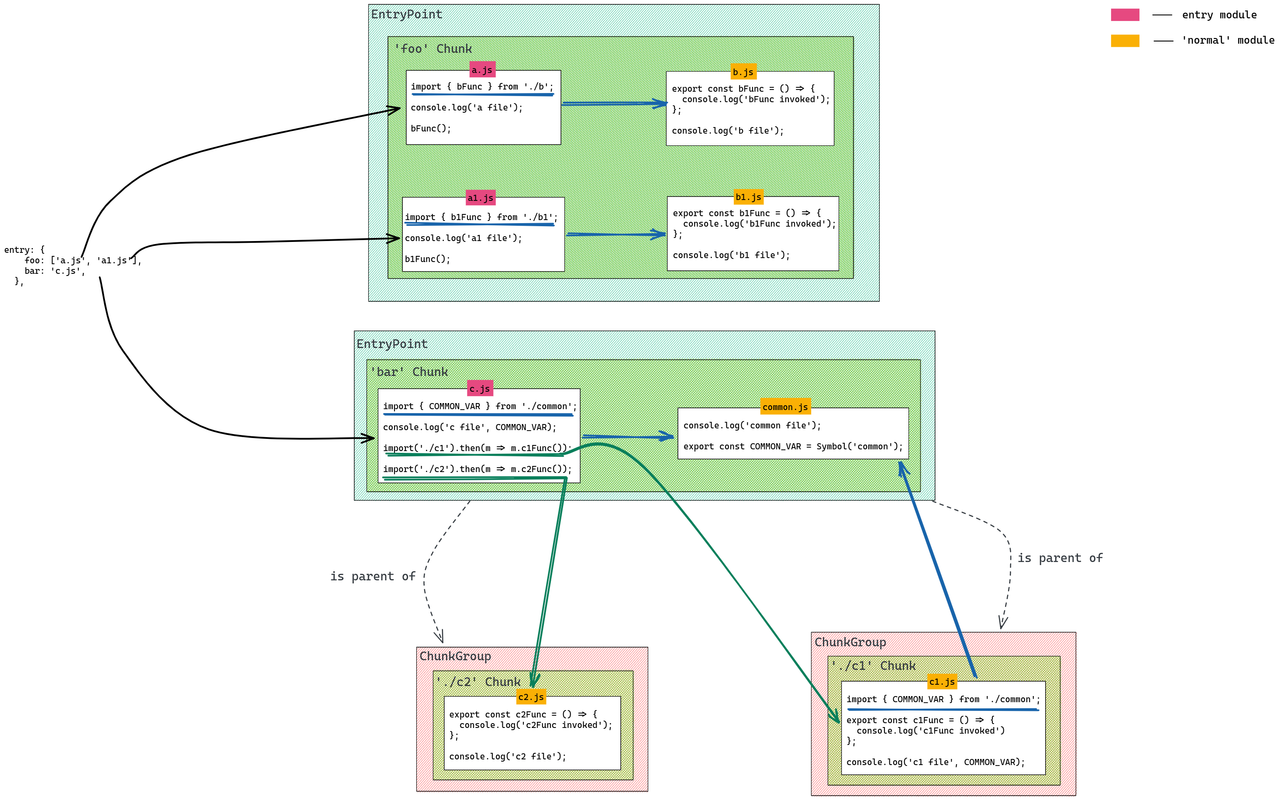
Діаграма демонструє дуже спрощену версію ChunkGraph, але цього достатньо, щоб висвітлити отримані фрагменти та зв'язки між групами ChunkGroup. Ми бачимо 4 фрагменти, тож буде 4 вихідних файли. Фрагмент foo матиме 4 модулі, 2 з яких — вхідні. bar має лише 1 модуль входу, а інший можна вважати звичайним модулем. Кожен вираз import() створить нову групу ChunkGraph (батьківським для неї буде bar EntryPoint), яка залучить новий фрагмент.
Вміст отриманих файлів визначається на основі ChunkGraph, тому він дуже важливий для всього процесу пов'язування. Ми коротко поговоримо про активи фрагментів (тобто отримані файли) у наступному розділі.
Перш ніж досліджувати приклад із ChunkGraph, важливо згадати деякі його особливості. Подібно до ModuleGraph, вузол, який належить до ChunkGraph, називається ChunkGraphChunk (тобто фрагмент, що належить ChunkGraph). Це просто декорований фрагмент, тобто додаткова властивість, як і модулі, котрі є частиною фрагмента, або модулі введення фрагмента тощо.
Як і ModuleGraph, ChunkGraph відстежує ці фрагменти з додатковими властивостями за допомогою карти, яка має такий підпис: WeakMap<Chunk, ChunkGraphChunk>. У порівнянні з картою ModuleGraph, ця карта, яку підтримує ChunkGraph, не містить відомостей про зв'язки між фрагментами. Натомість усі необхідні дані (наприклад, про групи ChunkGroup, до яких вона належить) зберігаються в самому фрагменті.
Пам'ятайте, що фрагменти згруповані разом у ChunkGroups, і між цими групами фрагментів можуть існувати відносини «батьківська-дочірня» (як ми бачили на діаграмі вгорі). Це не стосується модулів, оскільки модулі можуть залежати один від одного, але не обов'язково є батьківськими.
Тепер спробуємо використати ChunkGraph у кастомному плагіні, щоб краще все зрозуміти. Зверніть увагу, що приклад, який ми розглядаємо, зображений на діаграмі вгорі:
const path = require('path');
// Виведемо це, щоб виокремити зв'язок батьківський-дочірній елемент
// між групами `ChunkGroup`.
const printWithLeftPadding = (message, paddingLength) => console.log(message.padStart(message.length + paddingLength));
class UnderstandingChunkGraphPlugin {
apply (compiler) {
const className = this.constructor.name;
compiler.hooks.compilation.tap(className, compilation => {
// Хук `afterChunks` викликається після побудови `ChunkGraph`.
compilation.hooks.afterChunks.tap(className, chunks => {
// `chunks` — це набір усіх створених фрагментів. Фрагменти додаються
// у цей набір в порядку, в якому вони створені.
// console.log(chunks);
// Як ми вже говорили в статті, об'єкт `compilation` містить
// стан процесу пов'язування. Тут ми також можемо знайти всі
// створені групи `ChunkGroup`(включно з екземплярами `Entrypoint`).
// console.log(compilation.chunkGroups);
// `EntryPoint` — це тип `ChunkGroup`, який створюється для кожного
// елемента в об'єкті `entry`. У нашому поточному прикладі їх 2.
// Отже, щоб передати `ChunkGraph`, нам доведеться почати
// з `EntryPoints`, які зберігаються в об'єкті `compilation`.
// Докладніше про карту `entrypoints`(<string, Entrypoint>): https://github.com/webpack/webpack/blob/main/lib/Compilation.js#L956-L957
const { entrypoints } = compilation;
// Докладніше про `chunkMap`(<Chunk, ChunkGraphChunk>): https://github.com/webpack/webpack/blob/main/lib/ChunkGraph.js#L226-L227
const { chunkGraph: { _chunks: chunkMap } } = compilation;
const printChunkGroupsInformation = (chunkGroup, paddingLength) => {
printWithLeftPadding(`Current ChunkGroup's name: ${chunkGroup.name};`, paddingLength);
printWithLeftPadding(`Is current ChunkGroup an EntryPoint? - ${chunkGroup.constructor.name === 'Entrypoint'}`, paddingLength);
// `chunkGroup.chunks` — `ChunkGroup` може містити один або кілька фрагментів.
const allModulesInChunkGroup = chunkGroup.chunks
.flatMap(c => {
// Використання даних, котрі зберігаються у `ChunkGraph`,
// щоб отримати модулі, вміщені в один фрагмент.
const associatedGraphChunk = chunkMap.get(c);
// Сюди включено *модулі введення*.
// Використано оператор розповсюдження, оскільки `.modules` — це
// набір у цьому випадку.
return [...associatedGraphChunk.modules];
})
// Ресурс модуля — це абсолютний шлях і нас цікавить лише назва
// файлу, пов'язана з нашим модулем.
.map(module => path.basename(module.resource));
printWithLeftPadding(`The modules that belong to this chunk group: ${allModulesInChunkGroup.join(', ')}`, paddingLength);
console.log('\
');
// `ChunkGroup` може мати дочірні групи `ChunkGroup`.
[...chunkGroup._children].forEach(childChunkGroup => printChunkGroupsInformation(childChunkGroup, paddingLength + 3));
};
// Передавання `ChunkGraph`, у схожий на DFS спосіб.
for (const [entryPointName, entryPoint] of entrypoints) {
printChunkGroupsInformation(entryPoint, 0);
}
});
});
}
};
Приклад можна переглянути у застосунку StackBlitz. Після запуску npm run build, буде повернено таке:
Current ChunkGroup's name: foo;
Is current ChunkGroup an EntryPoint? - true
The modules that belong to this chunk group: a.js, b.js, a1.js, b1.js
Current ChunkGroup's name: bar;
Is current ChunkGroup an EntryPoint? - true
The modules that belong to this chunk group: c.js, common.js
Current ChunkGroup's name: c1;
Is current ChunkGroup an EntryPoint? - false
The modules that belong to this chunk group: c1.js
Current ChunkGroup's name: c2;
Is current ChunkGroup an EntryPoint? - false
The modules that belong to this chunk group: c2.js
Ми використали відступ, щоб розрізняти батьківські-дочірні елементи. Також можемо помітити, що вихідні дані відповідають діаграмі, тому ми можемо бути впевнені в правильності передавання.
Випуск фрагментів ресурсів (chunk assets)
Важливо, що отримані файли — це не просто скопійовані та вставлені версії початкових файлів. Бо ж для досягнення своїх завдань webpack повинен додати певний кастомний код, завдяки якому все працюватиме як слід.
Звідси виникає запитання: як webpack знає, який код генерувати? Усе починається з найбазовішого (і найкориснішого) шару: module. Модуль може експортувати учасників, імпортувати інших учасників, використовувати динамічний імпорт, застосовувати специфічні для webpack функції (наприклад, require.resolve) тощо.
Враховуючи початковий код модуля, webpack може визначити, який код генерувати для досягнення бажаних результатів. Розуміння цього починається під час аналізу AST, де перебувають залежності. Хоча досі ми використовували залежності та модулі як взаємозамінні, під капотом все трохи складніше.
Наприклад, простий import { aFunction } from './foo' поверне 2 залежності (одну для самого твердження import, а іншу для специфікатора, тобто aFunction), з яких буде створено єдиний модуль. Інший приклад — функція import(). Як згадувалося в попередніх розділах, вона створить асинхронний блок залежностей, і однією з цих залежностей буде ImportDependency, яка є специфічною для динамічного імпорту.
Ці залежності важливі, оскільки вони містять деякі вказівки щодо того, який код має бути згенерований. Наприклад, ImportDependency точно знає, на що вказати webpack, щоб асинхронно отримати імпортований модуль і використовувати його експортовані елементи.
Такі вказівки можна назвати вимогами середовища виконання. Наприклад, якщо модуль експортує деякі свої елементи, серед них буде залежність (нагадаємо, що зараз йдеться не про модулі), а саме HarmonyExportSpecifierDependency, яка повідомить webpack, що він повинен обробляти логіку для експорту учасників.
Підсумуємо: модуль має вимоги середовища виконання, які залежать від того, що цей модуль використовує у своєму початковому коді. Вимоги від середовища виконання до фрагмента будуть набором усіх вимог рантайму до всіх модулів, які належать до цього фрагмента. Тепер, коли webpack знає про всі вимоги до фрагмента, він зможе правильно згенерувати код середовища виконання.
Це ще називається процесом рендерингу. Ми не заглиблюватимемося у подробиці; наразі достатньо розуміти, що процес рендерингу значною мірою залежить від ChunkGraph, оскільки він містить групи фрагментів (наприклад, ChunkGroup, EntryPoint), у яких є фрагменти з модулями. Там розміщено докладну інформацію та вказівки про код середовища виконання, який повинен згенерувати webpack.
Цим розділом ми завершуємо теоретичну частину цієї статті. У наступному розділі ми розглянемо кілька способів налагодження початкового коду webpack, який може стати в пригоді, якщо ви зіткнетеся з проблемою, або захочете дізнатися докладніше про роботу webpack.
Налагодження початкового коду webpack
Зі сподіванням, що попередні розділи пролили світло на роботу webpack під капотом, у цьому розділі ми розкажемо про налагодження його початкового коду. Ми також розглянемо, де розмістити точки зупинки, щоб дослідити окремі частини процесу пов'язування.
Використовуємо VS Code
VS Code — це дивовижний інструмент з розмаїттям можливостей для перегляду кодової бази.
План дій такий — клонуємо репозиторій webpack до власного репозиторію за допомогою підмодулів Git. Це спростить нам відстеження змін у репозиторії webpack. Ми покажемо власний приклад, але не соромтеся обирати підхід, який найкраще задовольнить ваші потреби.
По-перше, створюємо свій репозиторій під назвою understanding-webpack. Якщо ви хочете повторювати, ви можете створити репозиторій так:
git clone --recurse-submodules git@github.com:Andrei0872/understanding-webpack.git
yarn
У ньому ви побачите каталог з назвою examples, де кожен конкретний приклад представлений каталогом. У package.json, ви побачите щось подібне:
"scripts": {
"understand": "yarn import-order",
"import-order": "webpack --config ./examples/import-order/webpack.config.js",
"create-example": "cd examples && cp -r dummy-example"
},
Правила такі: основна команда (тобто команда, з якою ми працюватимемо, щоб випробувати будь-який приклад) — yarn understand. Якщо ви запустите її зараз, webpack використовуватиме приклад за шляхом examples/import-order. Кожен приклад отримає свій власний скрипт, наприклад import-order у згаданому сніпеті. Якщо потрібно використовувати інший приклад, все, що нам потрібно зробити, це замінити import-order у "understand": "yarn import-order" з назвою прикладу.
А тепер про налагодження. У репозиторії є каталог .vscode/launch.json, який зберігає конфігурацію налагодження. Після натискання F5 він повинен запустити команду з yarn understand у середовищі налагодження, тому, щоб швидко перевірити її, помістіть точку зупинки в тіло функції seal(), у файлі Compilation.js (натисніть CTRL + P, а потім введіть webpack/lib/Compilation.js, потім натисніть CTRL + SHIFT + O, потім введіть seal) перед запуском налагоджувача.

До речі, функція seal охоплює багато кроків, наведених у головній діаграмі, наприклад: створення перших фрагментів, побудова ChunkGraph, генерування середовища виконання коду та створення ресурсів.
Отже, ми побачили, як налагоджувати власні приклади. Тепер розгляньмо, як налагодити тест webpack або будь-який інший скрипт, який webpack визначив у своєму файлі package.json.
Короткий відступ: Якщо ви використовуєте webpack у продакшн-режимі, або якщо ви включили terser plugin, у вас можуть виникнути проблеми з вбудованим налагоджувачем VS Code, тому що він не має функціональності налагодження worker_threads або дочірніх процесів. Але цим послуговується пакунок jest-worker, а jest-worker використовується плагіном terser-webpack-plugin. Для цього існує інструмент під назвою ndb. Після його встановлення ви можете просто перейти в каталог webpack (підмодуль git) і ввести ndb у нове вікно, з якого ви зможете вибрати, який скрипт запускати в режимі налагодження. Ви також можете вказати там точки зупинки, як це зазвичай робите у VS Code.
Наприклад, ми розмістили точку зупинки в Chunk.unittest.js, перед вказівкою ndb запустити скрипт test:unit (розміщено в нижньому лівому куті):

Ви також можете запустити певний набір тестів, використовуючи команду, подібну до цієї:
// Опції взяті з одного зі скриптів `package.json`
// Просто замініть `TestCases.template.js` іншою назвою
// файлу, якщо хочете налагодити щось інше.
ndb node --max-old-space-size=4096 --trace-deprecation node_modules/jest-cli/bin/jest --testMatch "<rootDir>/test/TestCases.template.js"
Одна з проблем, яку розв'язує ndb: ви можете використовувати налагоджувач для файлів, які виконуються в робочому потоці або в процесі, відмінному від початкового, який розпочав процес налагодження. Отже, якщо ви хочете налагодити процес мініфікації terser у власному прикладі, можете застосувати ndb yarn understand (з кореневого каталогу репозиторію):
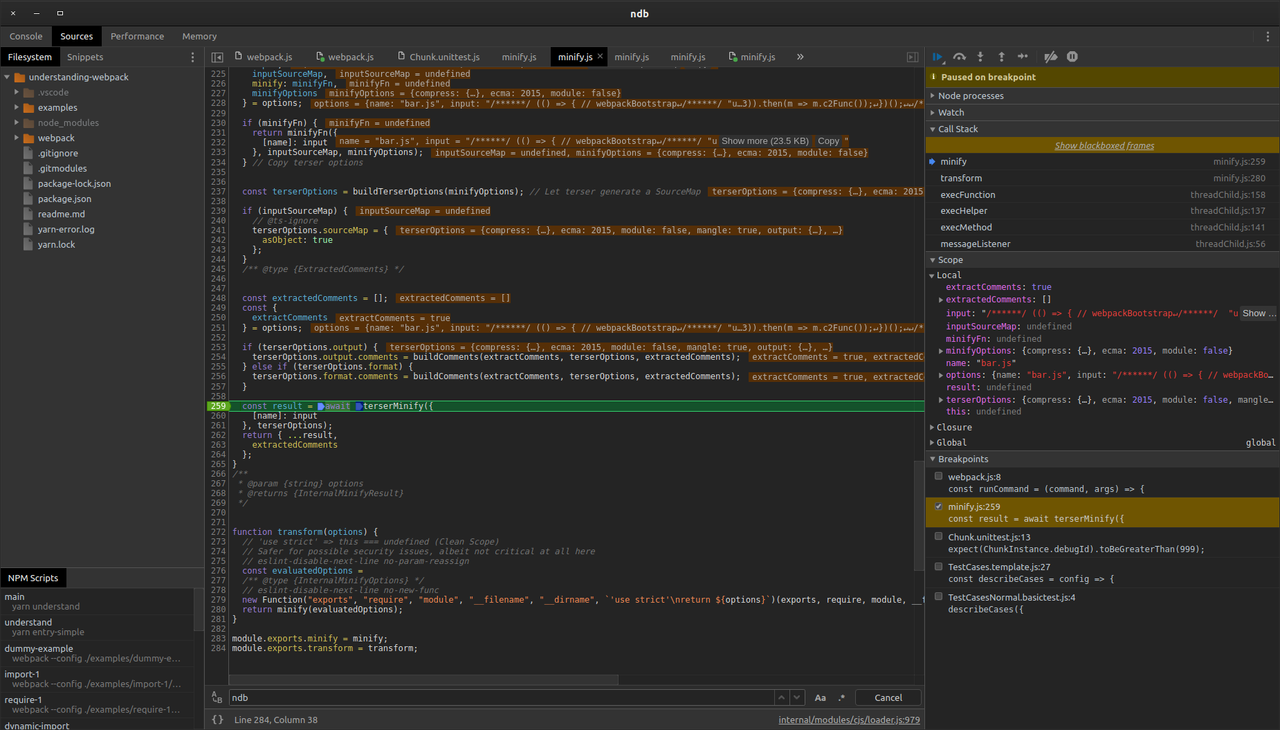
Файл можна знайти за шляхом webpack/node_modules/terser-webpack-plugin/dist/minify.js. Якщо ви спробуєте виконати налагодження у VS Code, ви помітите, що точка зупинки нехтується. А от з ndb вона спрацює.
Якщо ви хочете дослідити процес пов'язування з самого початку, можете додати точку зупинки у функції createCompiler у файлі webpack/lib/webpack.js.
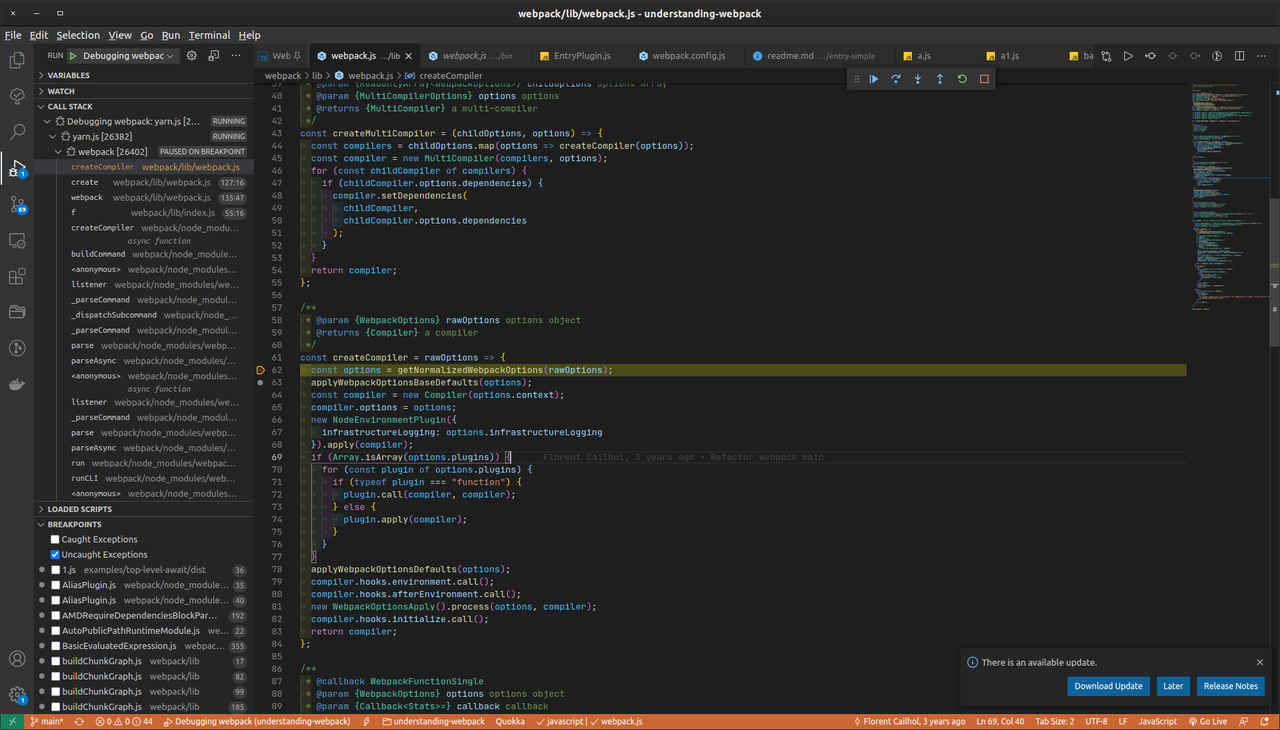
На цьому етапі ви також можете перевірити значення типової конфігурації.
Загалом радимо використовувати ndb, коли потрібно налагоджувати файли, які запускаються за допомогою worker_threads, або запустити процес, окремий від процесу налагодження.
Кілька хитрощів для легкої навігації кодовою базою webpack (або будь-якою іншою)
Примітка: поради для VS Code.
- Натиснувши
CTRL + SHIFT + F12можна переглянути усі місця репозиторію, у яких вжито вказану змінну/суб'єкт/функцію:
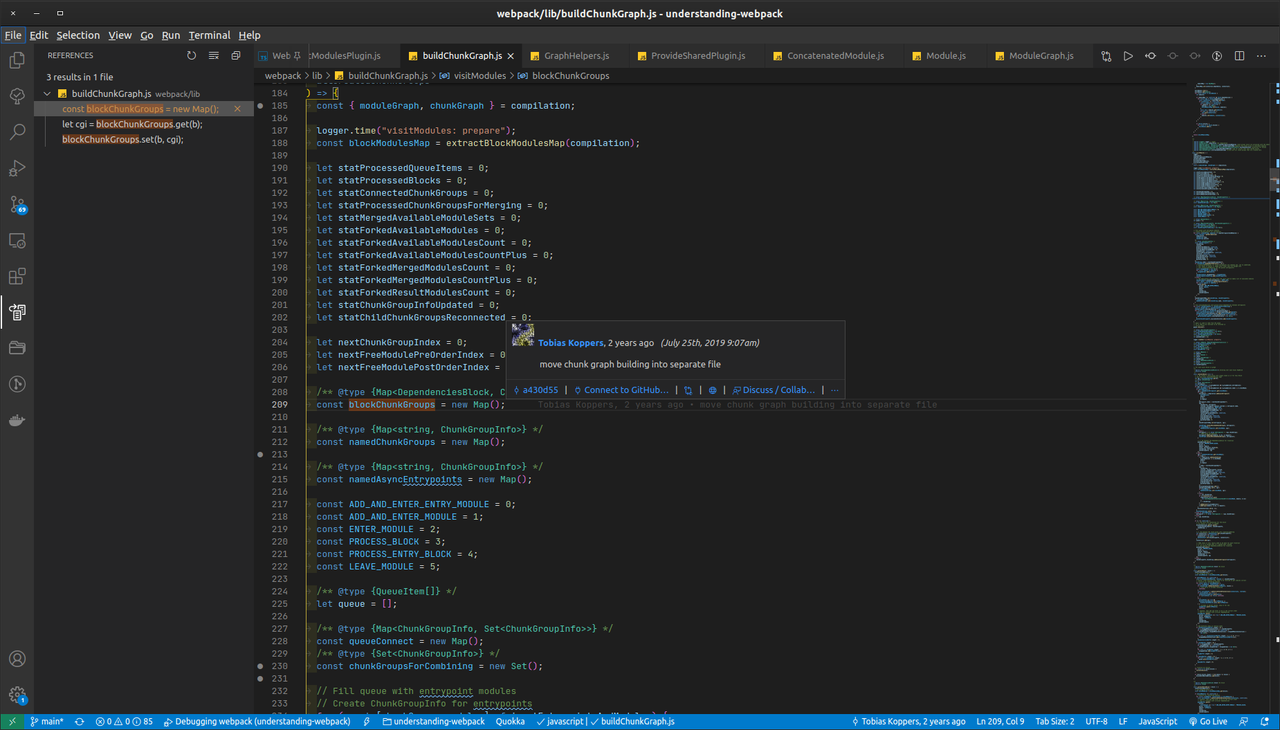
-
Натиснувши
CTRL + SHIFT + \\можна знайти відповідні дужки -
Натиснувши
ALT + SHIFT + Hможна переглянути ієрархію викликів
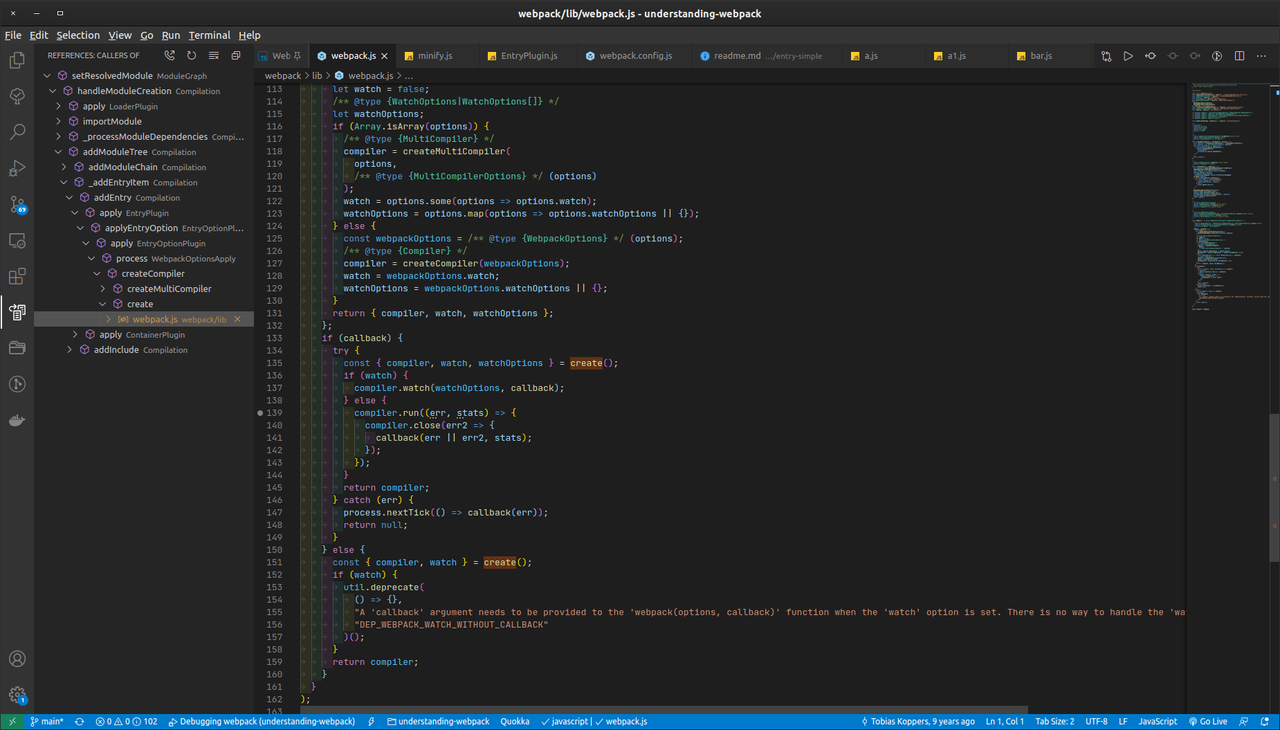
На цьому знімку екрана ви можете побачити, що спричиняє виклик setResolvedModule.
- Щоб визначити, які плагіни додали кастомні функції до наданих webpack хуків, ви можете відкрити глобальний пошук (
CTRL + SHIFT + F) і ввести.hooks.nameOfTheHook.tap(спосіб, у який ви додаєте кастомні функції до хуку за допомогою методуtap/tapAsync):
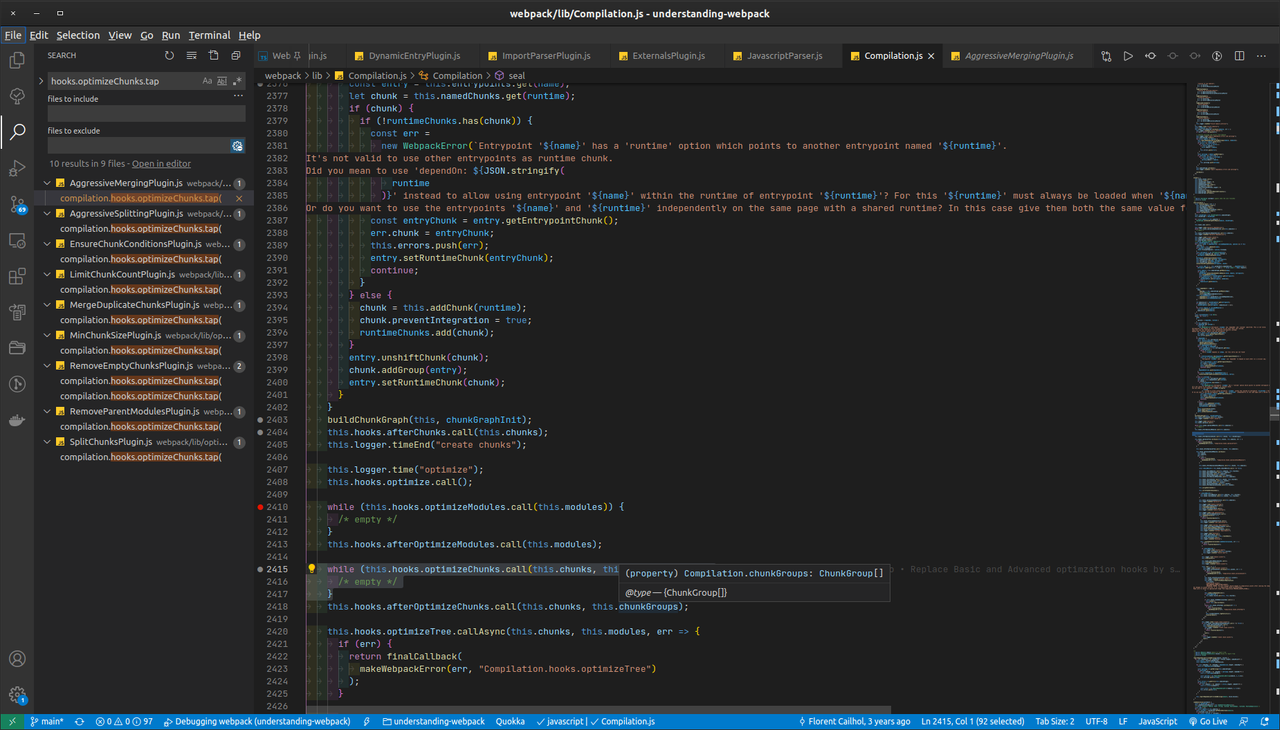
На лівій панелі ви можете побачити, якими плагінами додано нову логіку до вбудованого хука optimizeChunks.
Крім того, якщо ви використовуєте налагоджувач, швидко перевірте властивість хука taps, щоб переглянути джерела, з яких було додано функціональність:

Використовуємо StackBlitz
StackBlitz — це ще один чудовий інструмент для розробників. Використовуючи StackBlitz, вам більше не доведеться перемикатися з браузера. Ви можете робити все, що було описано в розділі про використання VS Code. Крім того, поведінку ndb вже вбудовано у StackBlitz — тож не потрібні жодні додаткові інструменти!
Автор створив проєкт StackBlitz, який називається webpack-base, з базовими налаштуваннями, які можуть бути гарною відправною точкою під час створення інших демонстрацій. Щоразу, коли потрібно швидко дослідити якусь можливість webpack, достатньо просто відкрити цей проєкт, створити форк і працювати з ним.
Також є відео про це. Припускаючи, що ми хочемо розпочати вивчення процесу пов'язування з точки створення компілятора, наводимо необхідні для цього кроки (спершу переконайтеся, що створили форк проєкту):
-
запустіть
code node_modules/webpack/lib/webpack.jsу терміналі; -
перейдіть до 135 рядка (
CTRL + G— як і у VS Code) або знайдіть місце, де викликається функціяcreate(CTRL + SHIFT + Pможе допомогти); -
уведіть ключове слово
debugger; -
відкрийте інструменти розробника;
-
запустіть скрипт
npm run buildу терміналі.
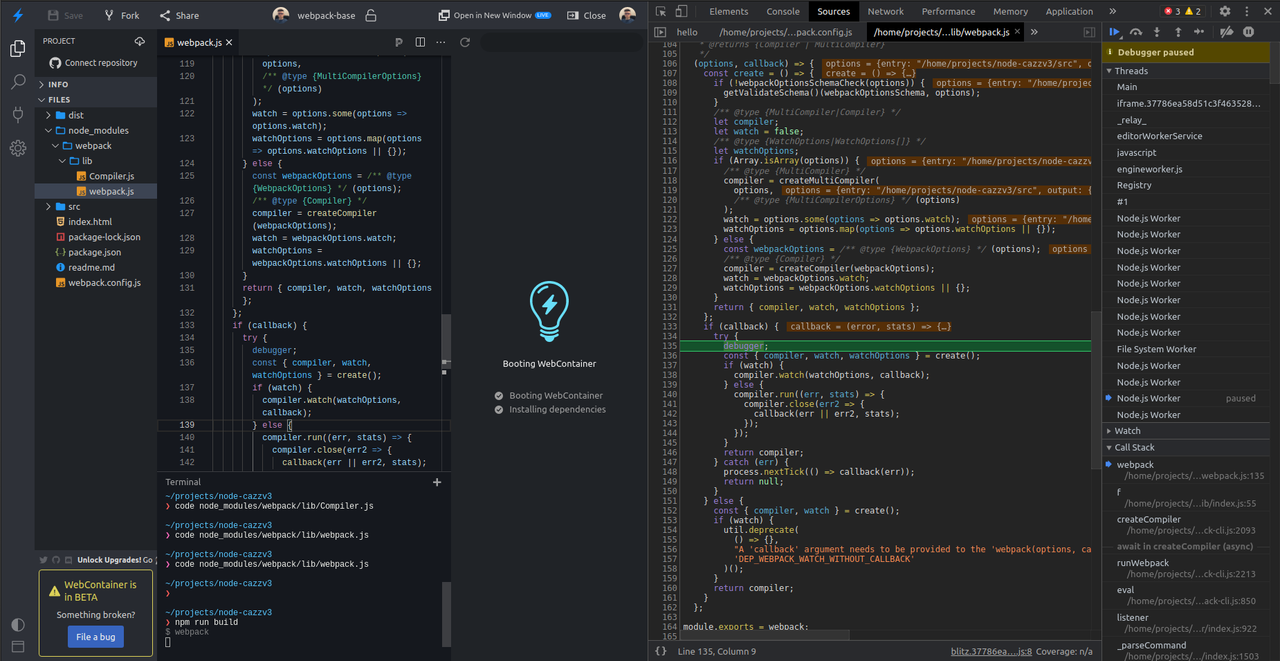
Ми вжили ключове слово debugger;, щоб простіше знайти на вкладці Sources. Іноді буває важко знайти його за допомогою CTRL + P. З цього моменту ви можете розпочинати процес налагодження, як зазвичай: клацніть номери рядків, щоб розмістити точки зупинки, можете додавати умовні точки зупинки, перейти до потрібної тощо.
Примітка: ви можете застосувати той самий процес для кожного скрипту вузла.
Висновок
У цій статті без зайвих деталей надано достатньо інформації, щоб ви могли поглянути на webpack з іншої перспективи. Це складний (і чудовий) інструмент, тож, сподіваємось, ця стаття зробила його простішим та зрозумілішим.

Ще немає коментарів