Про автора: Іван Мельничук, Head of Programming в IТ-компанії Nexteum. Має 10-річний досвід програмування, близько 4 років розвиває highload проекти.
Привіт усім! У своїй публікації хочу поділитися досвідом, як на власній практиці розв'язував проблему повільної віддачі сторінок. Не секрет, що тривале завантаження сторінок — проблема для highload проектів, особливо у сегменті онлайн-торгівлі. Інтернет-магазини з багатомільйонним асортиментом та органічним трафіком з Google у боротьбі за кожного клієнта намагаються максимально скоротити тривалість відкриття сторінки. Бізнес диктує вимоги, ми розробляємо фічі. Тож про одну із них розповім у публікації детальніше.
На певному етапі роботи у Nexteum, замовник поставив нашій команді амбіційну задачу — на одній платформі розвинути 8 напрямків бізнесу. Терміни були обмежені. До того ж у стислий час нам потрібно було не тільки збільшити кількість каталогів на одній платформі, але й розв'язати проблему зі статистикою та аналітикою. Саме ці задачі привели нас до винаходу «велосипеду» ELK. Та про все по черзі.
Справи насущні
При активній роботі над розширенням онлайн-платформи не обходиться без технічних несподіванок. Як показує досвід, вони підкрадаються поступово. Зазвичай якийсь період часу все йде чудово: органічний трафік зростає, SEO-спеціалісти молодці. Але наступає момент, коли все в одну хвилину валиться: БД падає, кеш тріщить, а сайт починає працювати дуже повільно або з перебоями.
Недосвідчені розробники, як правило, розводять руками, мовляв, «ми робили просто сайт». Так, але онлайн-магазин, який працюватиме на збільшення продажів, це апріорі не просто сайт. Це поліфункціональна платформа з рядом «навантажень» у вигляді:
- величезного об'єму контенту (часто він не лімітований);
- органічного трафіку;
- ботів (створюють чимало мороки). Зазвичай на сторінки як мінімум може завітати GoogleBot. Та, окрім нього, часто приходять ще й AdsBot, BingBot та інші парсери.
У такій ситуації багато хто запропонує закешувати сторінки. А якщо їх 20 чи 30 мільйонів? У кеш вони просто не залітають, тому що там різний контент (який додається на другому пункті). Тож насправді жоден memcached не врятує ситуацію, адже не існує стільки петабайт пам'яті у світі, скільки потрібно закешити, щоб швидко віддавати великий об'єм контенту.
Ще одна вагома проблема (як для замовника, так і для розробника) — як зрозуміти, наскільки повільно відкриваються сторінки. Статистика, здавалося б, за Google Analytics, однак цей сервіс семплірує дані й часто показує лише 5% правдивої інформації. Так, Google Analytics не те що б обманює, він ніби приховує інформацію. А звідки ж тоді взяти правдиві дані? Їх потрібно враховувати. Як саме? Адміни, наприклад, запропонують швидке рішення: грепнемо все, увімкнемо апач і логи, знову вінд ... Швидке рішення — добре, але у даному випадку потрібен велосипед. Маленький, але все ж таки свій «велосипед». І в Nexteum ми спробували скористатися новим рішенням — своя ELK. Заради справедливості зазначу, що це не до кінця велосипед, але ми його «прикрутимо».
Проблеми на «певному» етапі проекту
Розглянемо основні та часто поширені проблеми, які виникають при стрімкому розвитку онлайн-магазину.
- Ріст трафіку. Це водночас і проблема, і радість. Як варіант — питання ще може бути в адмінах і їх неправильних налаштуваннях.
- Навантаження на потужності. Є логічним наслідком зростання трафіку.
- «Просто все тупить» Найоптимальніше розв'язання цієї проблеми — горизонтальне масштабування.
- Читання з HDD. Вирішується досить просто — виносимо в сховище типу Memcache, Redis, NoSQL solutions.
- Не оптимізоване читання з бази. Вирішується шляхом оптимізації запитів, кешуванням.
- Виконання скриптів. Рішення: Оптимізація скриптів. Наприклад, PHP 7+ вирішив близько 30% наших проблем.
Як визначити, що саме створює проблеми у великому проекті?
Для масштабних проектів на етапі росту актуальним є питання: як зрозуміти, що проблема в БД? Як приклад, у нашої платформи 30 млн. унікальних сторінок, 20 млн. з яких відкривається на добу. Коли в MySQL потраплять якісь запити, десь індекси й кардіналіті в 5-6 не так порахуються, оптимізатор не туди ж подивиться — все дуже складно відстежити. В цей момент замовник може прийти поскаржитися на роботу проекту, адже, за його даними, статистика від Google Analytics показує зовсім непривабливі цифри. Водночас наша статистика показує протилежну картину. У такі моменти на допомогу приходять ось такі графіки.
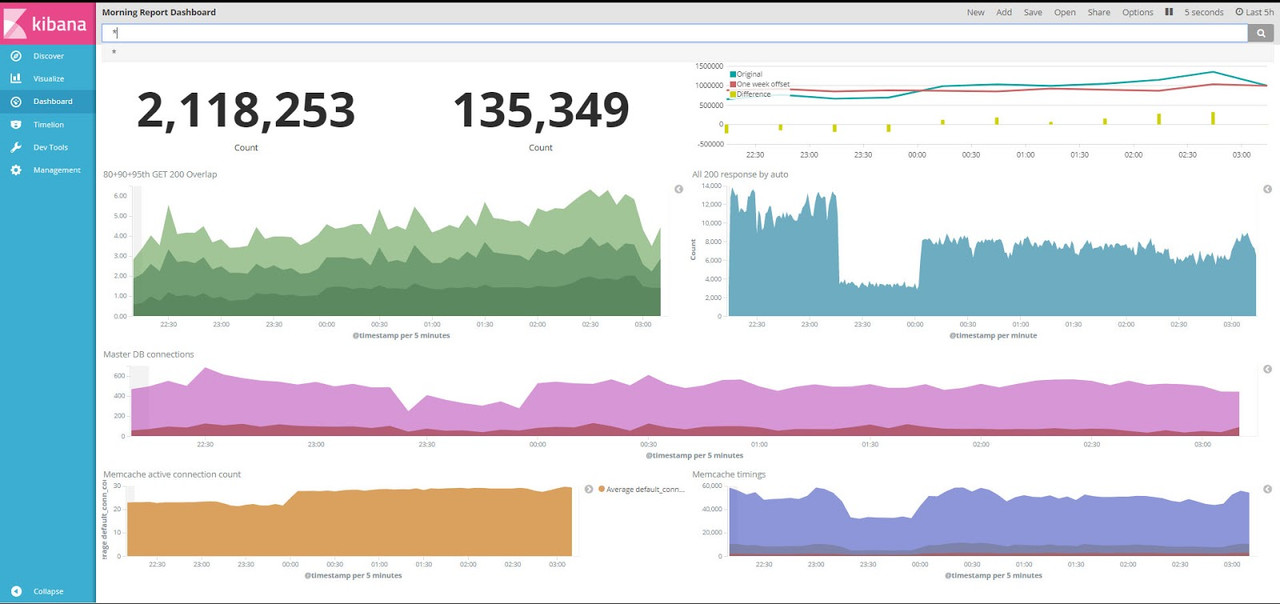
По суті це інтерфейс Kibana, який виводить дані Elastic Search.
Такий графік є моїм особистим підходом. Монтувати в нього можна все, що завгодно (і про це трішки згодом). Однак для мене найголовнішими на першому етапі впровадження були такі показники:
- Diff із попереднього тижня. Чому саме він? Тому що допомагає відстежити, хто завинив у ситуації «коли вчора наче добре все працювало, а сьогодні на піку все обвалилося».
- Персентилі часу відповіді.
- Середній показник кількості запитів.
- Кількість підключень до кешу.
- Таймінг кешу.
Далі розглянемо схему формування логів в ELK. Графічно вона виглядає так:
Відкриті сторінки / Збираємо перемінні Apache // Nginx / Шифруємо та кладемо у syslog-ng / Logtash фільтрація + форматування та запис в індекс в Elastic Search / Kibana — виведення графіку
Що робить користувач, щоб отримати дані в цій ELK?
Потрібно відкрити сторінку і зібрати всі змінні Apache і Nginx. У чому вся сіль? Змінні сетаємо із РНР; далі Nginx усе шифрує і кладе в syslog-ng. Зрештою в ці логи я кладу таймінги всіх запитів до БД і таймінги відповідей мемкеша. Також у змінні складаю таймінги абсолютно всіх мікросервісів чи служб, або всього того, що «проситься» з інтернету (з сервера, який відповідає користувачеві). Саме ця система допомагає зрозуміти, чому конкретна сторінка так довго відкривається.
Коли всі дані склали в syslog-ng, їх швиденько розбирають в Log stash. Усі ці наномаги, які застосовують адміни, можуть бути варіативними. Як розгрібати syslog — вже справа девопса. А у них різні варіанти, як навести лад.
Як тільки дані опиняються в Elastic Search, на графіку їх виводить Kibana.
Ось таку систему в Nexteum ми налаштували всього за два дні. Програмісти зі свого боку швиденько накидали адаптери коду, а адміністратори, у свою чергу, за кілька днів усе налаштували.
Переваги такого рішення
- Простота імплементації. Оперативна реалізація рішення.
- Гнучкість внаслідок змінних Apache | Nginx. Сетаємо змінні та зберігаємо там все, що потрібно. Навіть такі дрібні факти як час візиту на сайт певного користувача і його дії. Чому це важливо? Тому що головний репозиторій нашого моноліту, який ми намагаємося розкидати на мікросервіси, становить 1 гігабайт. До того ж є маса legacy code. Наприклад, в команді ми працюємо над одним проектом близько 14 років, і в ньому багато що накопичилось. Тому такий трекінг дуже зручний.
- Можливість логувати сторонні сервіси.
Недоліки системи
Заради справедливості варто зазначити, що дане рішення має і певні мінуси. Найвагоміші з них:
- Мережеві навантаження
Не забувайте, що у дата-центрі є сервер і кабель. Пропускна здатність кабелю не безмежна, тому мережа даватиме збої при навантаженні великими даними. Але недолік можна і варто мінімізувати. Розпиляйте моноліт на менші мікросервіси або на модулі, аби максимально розмістити дані на різних серверах і тим самим розвантажити мережу.
- Велика кількість займаного місця на гвинтах.
Дані, що лежать в Elastic Search, і його кеш доволі об'ємні. Тому їх потрібно розміщувати на HDD/SSD. На щастя, гвинти доступні, у вільному продажу і їх покупка сьогодні вже не б'є по гаманцю.
Додаткові можливості
Насправді описана система надає доступ до багатьох корисних можливостей. З її допомогою можна:
- логувати таймінги мемкеша;
- логувати таймінги відповіді запитів;
- логувати таймінги підключення до бази даних.
Що ж, з ELK розібралися. Час перейти до другої частини.
Можливі графіки
Для себе виокремив наступні пріоритетні графіки:
- Порівняння з попереднім проміжком часу.
- Графік за типами сторінок.
- Графік за типами юзер агентів / IP (можливість трекати частину ботів).
- Графік по швидкості відповіді сторонніх сервісів.
Хтось запитає, чому я розділив перші два пункти. Річ у тім, що тип сторінок — моя кастомна інформація. В мережі не сказано, який саме у мене тип сторінок. А я знаю і їх тип, і кількість трафіку на них, і який відсоток ботів… Одного разу була ситуація, коли показники SEO-шників відрізнялися від моїх даних у 10 (!!!) разів.
Приклад використання: від виявлення до релізу
Першим кроком до розв'язання проблем завжди є виявлення її причин.
Ми тестували дві БД — master і slave. Зрозуміли, що весь час читати і писати в Master DB нам не підходить; при цьому використовуємо MySQL, весь час «нариваємося» на Lock meta lock та мегалоги (в разі довгих вибірок) — і в результаті у нас падає БД.
Використовуючи ELK, ми виявили сторінки, які чомусь повільно відповідають по 95-му персентилю. Перевірили всі сервіси і завдяки вище розміщеному графіку дізналися, що проблема в БД. Тобто зависає база саме на запитах по 95-му персентилю. Тоді в Elastic Search додали додаткові коригування (зокрема, щоб відстежувати, скільки користувачів у конкретний момент підключається до бази даних). І ми дізналися, що за одну сесію користувача (тобто за одне відкриття сторінки) формується 4 підключення — доктрінівське, сімфоніське, з legacy сектору (застарілий код) і одне х-картівське (оскільки проект створювався з X cart). І це при тому, що база даних має ліміт на підключення. І в результаті база даних блокує нові підключення, допоки попередні не відпрацюють.
Ми зрозуміли, що для розв'язання проблеми потрібно додати slave і читати з нього для частини користувачів. Швидко від'єднати всі підключення є проблематичним, оскільки маємо значний legacy і маса викликів йде з інших місць. Вирізати не можемо, адже не маємо юніт-тестів. Тому перемикалися на Slave, а потім розв'язували питання зростання підключень.
Далі відстежували результати (перемикання на читання зі Slave).
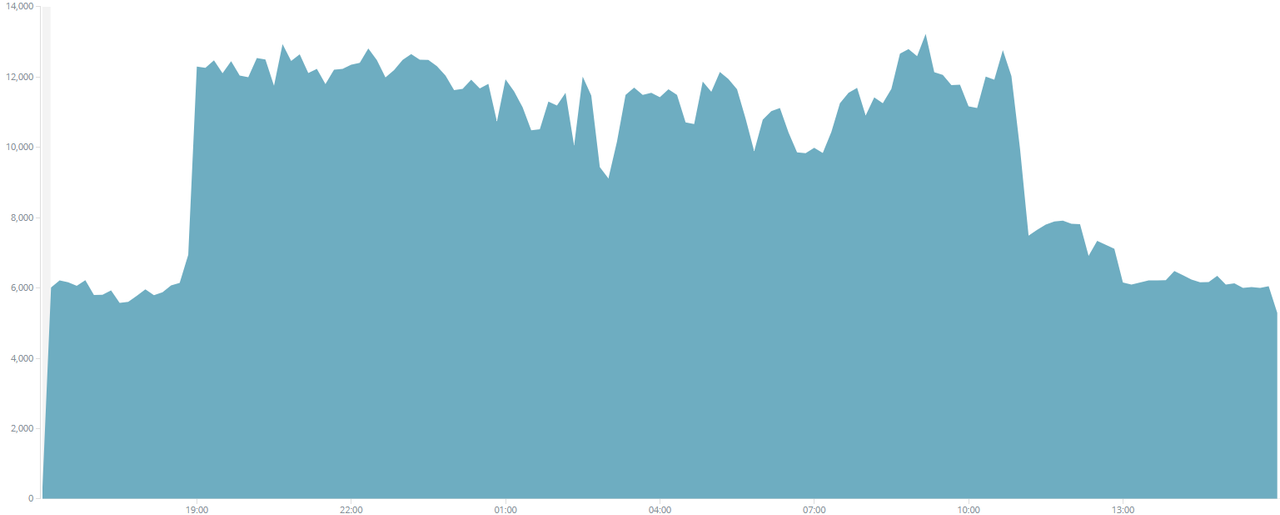
Ми бачимо великий стрибок трафіку, який приходить на наш сайт. Йдемо у Zabbix (інструмент DevOps для графіків статусів сервера) і перевіряємо обсяг підключення. Бачимо ріст трафіку, при цьому кількість підключень до БД не збільшилася.

Далі ми спробували перейти на slave і знову побачили ріст. Хоча на графіку можна спостерігати й показники, які впали. Вони знизилися тому, що ми двічі підключалися в одне і те ж місце. В один момент зрозуміли, що кількість підключень аж занадто зросла.
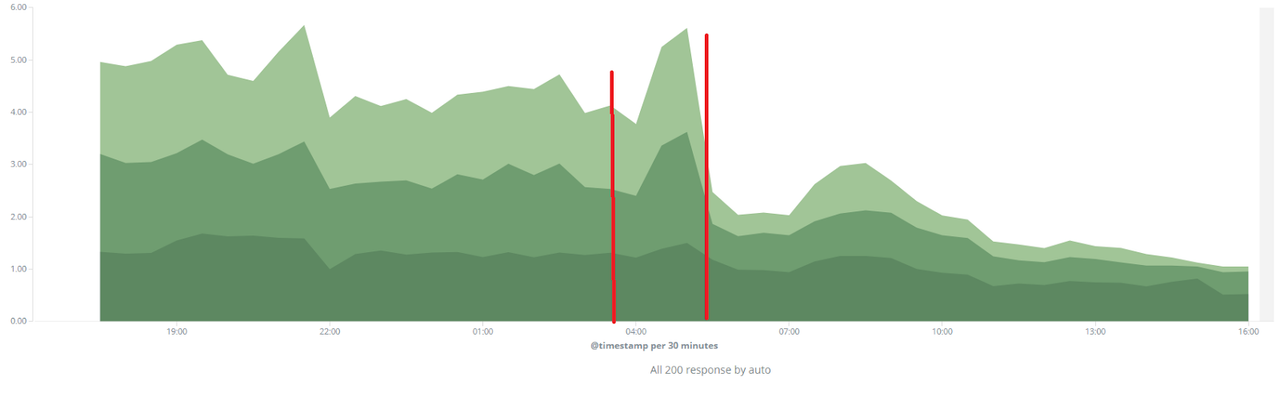
На графіку в Kibana ми також бачимо 2 релізи, позначені червоними лініями. В їх діапазоні виділені секунди, витрачені на час відповіді. Після першого релізу спостерігаємо збільшення часу відповіді, оскільки тримаємо 2 підключення — і до Slave, і до Master. Після другого релізу спостерігаємо відмінні показники зменшення загальної швидкості відповіді. Цей графік вже можна показувати бізнесу та отримувати «ордени».
Висновки
- ELK є непоганим інструментом для статистики. Однак якщо у вас чимало мікросервісів, не забувайте про проблему з мережею.
- Не складно реалізувати у проекті (створили його за 2 дні, і завдяки йому вирішили 90% проблем, які у нас були).
- Потрібен на етапі «коли вже складно стежити за проектом». В один момент у нас стрімко зросла кількість сторінок, і ми зрозуміли, що завдяки трекінгу вже не можемо бачити повну картину і потрібен інший інструмент.
- Хороша альтернатива статистиці від Google.

Ще немає коментарів