Видання MIT Technology Review проаналізувало наймасштабніше дослідження технологій розпізнавання облич і їхній вплив на конфіденційність. Переказуємо основні тези цієї статті (та радимо почитати увесь матеріал на сайті MIT і саме дослідження).
Епоха технологій розпізнавання облич розпочалась у 1964 році, коли математик та інформатик Вудро Бледсоу вперше спробував порівняти риси обличчя підозрюваних із фотографіями раніше заарештованих людей.
Зараз дослідниці Дебора Раджі (Deborah Raji, Mozilla) та Женев'єва Фрід (Genevieve Fried) проаналізували понад 130 наборів даних, зібраних за останні 43 роки для технологій розпізнавання облич. Виявилось, що з часом автори цих датасетів дедалі менше просили дозволу в людей, чиї фото вони збирали. Тож у системи спостереження потрапляють особисті фото користувачів, які про це не знають.
Такий підхід також призводить до хаотичності датасетів — із зображеннями неповнолітніх, расистськими чи сексистськими метаданими, поганою якістю чи освітленням. Цим можуть пояснюватись випадки, коли системи помилялися й поліція заарештовувала не тих людей.
Чотири епохи розпізнавання облич
Дослідники виділили чотири основні епохи розпізнавання облич, під час кожної з яких технологію намагались вдосконалити. До 1990-х років процеси були переважно повільними й багато чого доводилось робити вручну.
Згодом цей напрямок став перспективнішим і Міноборони США інвестувало 6,5 мільйона доларів у створення першого масштабного набору даних. Фотосесії для нього тривали протягом трьох років, загалом зробили 14 122 зображення 1199 осіб, які давали згоду організаторам. Набір даних називався FERET і був випущений у 1996 році.
Наступні десять років дослідження у цій галузі розвивались і наборів даних ставало більше. Зазвичай учасники теж давали згоду, а в самих датасетах були ретельно прописані метадані — вік, етнічність, інформація про освітлення тощо.
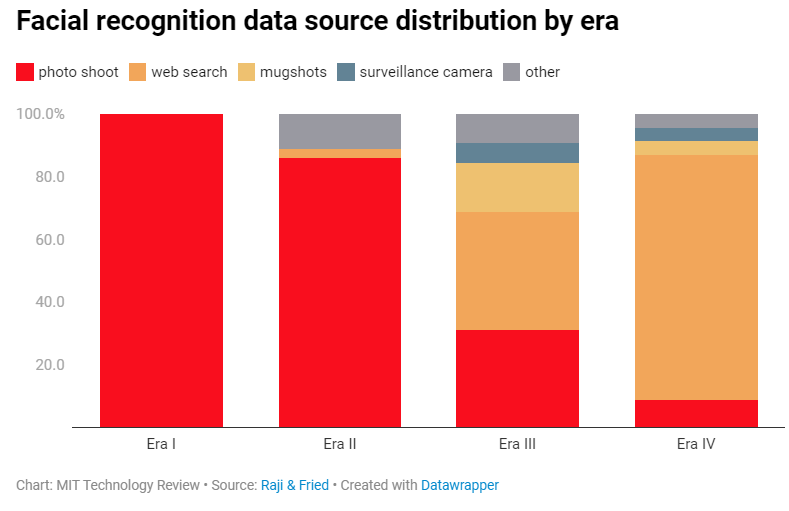
Однак ранні системи не надто добре працювали в реальних умовах, тож потрібні були масштабніші й різноманітніші дані. У 2007 році вийшов набір Labeled Faces in the Wild (LFW) — і після цього дослідники почали збирати фотографії з мережі. Вони брали зображення з Google, Flickr, Yahoo та не запитували дозволу людей.
До того ж для різноманітності даних у LFW були фотографії за тегами «немовля», «підліток» тощо, відтак стандарти у галузі дещо послабились.
У 2014 році Facebook використав фото користувачів для тренування моделі DeepFace. Сам набір ніколи не публікувався, але дослідниці кажуть, що цього разу йшлося про десятки мільйонів фотографій. Метадані до них генерувались автоматично й містили принизливі описи, які не редагувались вручну.
У цей час системи починають менше розпізнавати, а більше класифікувати людей. Умовно, не лише визначати, чи на фото Петро, а й зараховувати Петра до певної категорії та наділяти його певними якостями.
Дослідниці зазначають, що масштаби технологій глибокого навчання не дозволяють повноцінно контролювати процес — і вже складно передбачити, як конфіденційні дані про людей будуть використовуватись далі. З усім дослідженням можна ознайомитись за посиланням.

Ще немає коментарів